
Всем привет!
В последнее время наметился интересный тренд — быстрое «распухание» веб-проектов до бесконечности. Объем данных многих популярных сайтов растет все быстрее и быстрее, их нужно куда-то девать, при этом эффективно бэкапить (весело будет, если файлы на 500Т потеряются :-) ), и конечно супербыстро раздавать клиентам, чтобы все их могли качать, качать, качать… на высокой скорости.
Для системного администратора задача даже редкого, ежедневного резервного копирования такого объема файлов навевает мысли о суициде, а менеджер веб-проекта просыпается в холодном поту от мысли о предстоящей профилактике датацентра на 6 часов (чтобы файлы перевести из одного датацентра в другой нужно пару раз загрузить багажник автомобиля винчестерами :-) ).
Коллеги с умным видом советуют приобрести одно из решений от NetApp, но, жаль, что бюджет у проекта в 1000 раз меньше, это вообще стартап… что делать будем?
В статье хочу разобрать частые кейсы дешевого и дорогого решения данной задачи — от простого к сложному. В конце статьи расскажу как задача решена в нашем флагманском продукте — всегда полезно сравнивать opensource-решения с коммерческими, мозгам нужна гимнастика.
Если Вы хоть раз посещали конференцию HighLoad, то наверняка знаете, что на входе нужно обязательно ответить на вопрос — почему ставят nginx перед apache? Иначе дальше гардероба не пройти ;-)
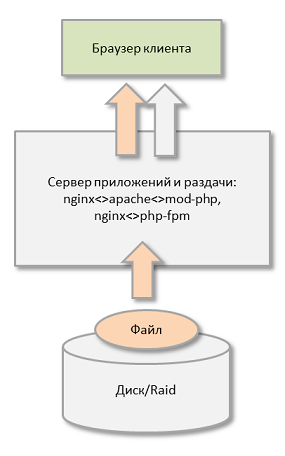
Правильно, nginx или аналогичный обратный прокси позволяет эффективно раздавать файлы, особенно по медленным каналам, серьезно снижая нагрузку на сервер и повышая в целом производительность веб-приложения: nginx раздает кучу файлов, apache или php-fpm обрабатывают запросы к серверу приложений.
Такие веб-приложения живут хорошо, пока объем файлов не увеличивается до, скажем десятков гигабайт — когда несколько сотен клиентов начинают одновременно скачивать файлы с сервера, а памяти для кэширования файлов в ОЗУ недостаточно — диск, а потом и RAID — просто умрет.
Примерно на этом этапе нередко начинают сначала фиктивно, затем физически раздавать статические файлы с другого, желательно не отдающего много лишних cookies, домена. И это правильно — всем известно, что браузер клиента имеет ограничение на число коннектов в одному домену сайта и когда сайт вдруг начинает отдавать себя с двух и более доменов — скорость его загрузки в браузер клиента существенно возрастает.
Делают что-то типа:
Чтобы более эффективно раздавать статику с разных доменов, ее выносят на отдельный сервер(а) статики:
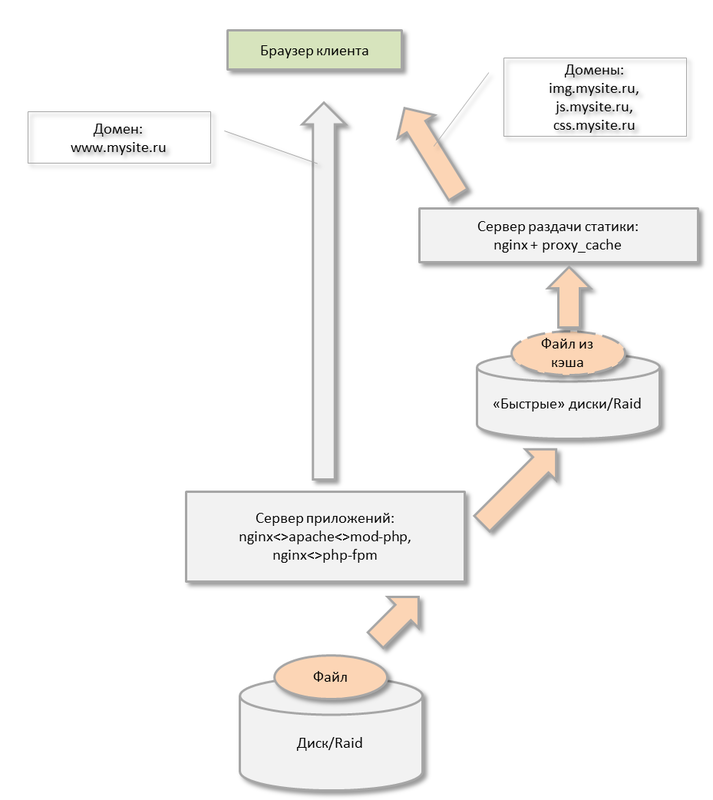
Полезно на этом сервере использовать режим кэширования nginx и «быстрый» RAID (чтобы побольше клиентов требовалось для постановки диска «на колени»).
На этом этапе организаторы веб-проекта начинают понимать, что раздавать из своего датацентра даже с очень быстрых дисков или даже SAN — не всегда эффективно:
В общем все понимают, что нужно быть как можно ближе к клиенту и отдавать клиенту столько статики, сколько он хочет, на максимально возможной быстрой скорости, а не сколько мы можем отдавать со своего сервера(ов).
Эти задачи в последнее время начала эффективно решать технология CDN.
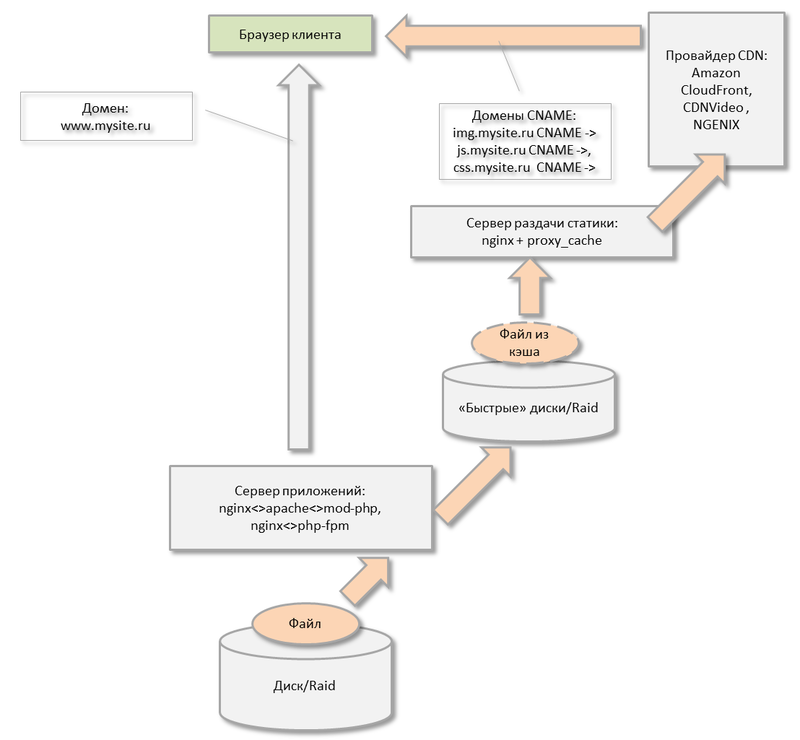
Ваши файлы действительно становятся доступны клиенту на расстоянии вытянутой руки, откуда бы он их не начал качать: с Красной площади или с Сахалина — файлы будут отдаваться с ближайших ему серверов провайдера CDN.
На этом этапе веб-проект — постепенно распухает. Вы копите все больше и больше файлов для раздачи, храня их, можно сказать, централизованно в одном ДЦ на одном или группе серверов. Делать резервную копию такого количества файлов становится все дороже, дольше и сложнее. Полный бэкап делается неделю, приходится делать снепшоты, инкременты и прочие вещи, увеличивающие риск суицида.

Вы боитесь подумать о следующем:
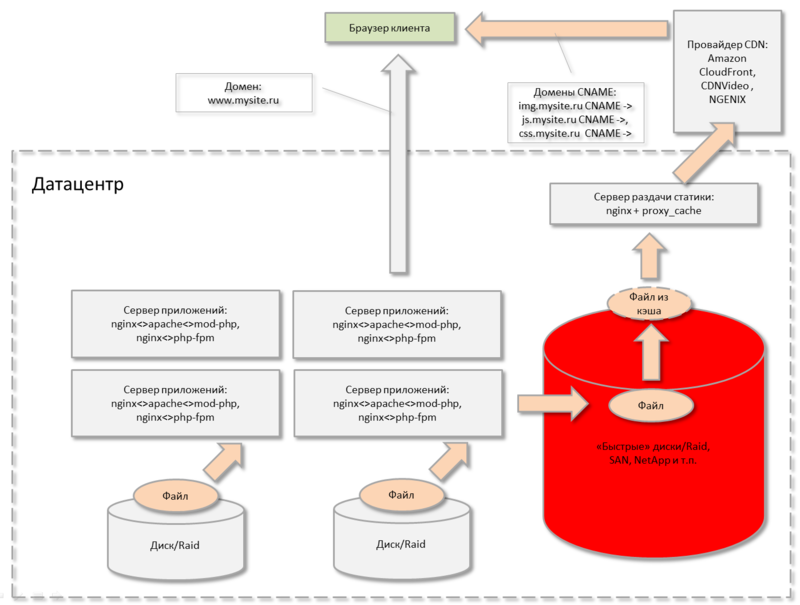
Да и вообще, вы вложили в инфраструктуру уже столько денег, а риски, причем немалые — остаются. Как-то нечестно получается.
В этот момент у многих отключается левое, ответственное за логику, полушарие и их тянет к таинственным монстроподобным решениям — развернуть в нескольких датацентрах свою распределенную файловую систему. Возможно для проекта с большим бюджетом это будет выходом…
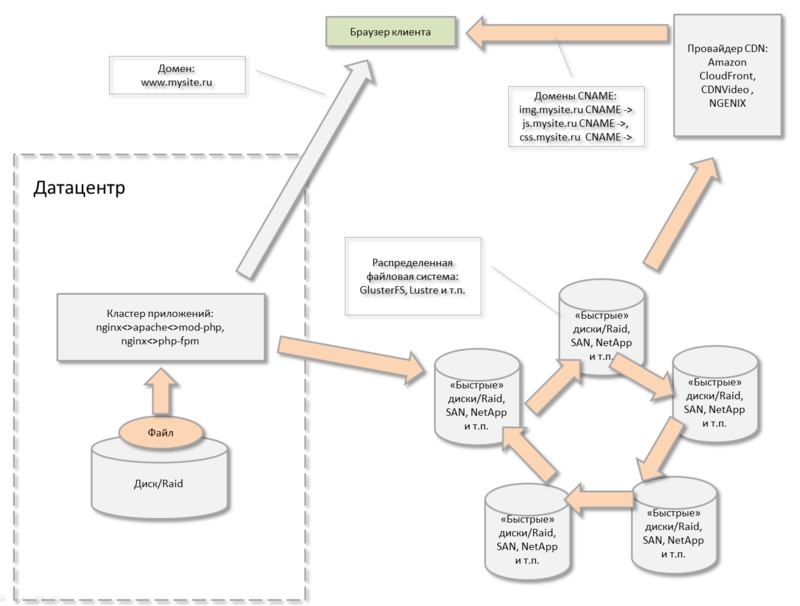
Тогда придется все это хозяйство администрировать самостоятельно, что потребует наличие видимо целого отдела эксплуатации :-)
Одним из наиболее эффективных и, что важно, дешевых решений, является использование возможностей известных облачных провайдеров, дающих в аренду по очень вкусным, особенно при большом объеме данных, ценам, способ хранить неограниченный объем ваших файлов в облаке с очень высокой надежностью (гигантский DropBox). Провайдеры организовали на своих мощностях описанные выше распределенные файловые системы, высоконадежные и размещенные в нескольких датацентрах, разделенных территориально. Более того, эти сервисы, как правило, тесно интегрированы в сеть CDN данного провайдера. Т.е. вы будете не просто удобно и дешево хранить свои файлы, но и их максимально удобно для клиента раздавать.
Дело за малым — нужно настроить на своем веб-проекте прослойку или виртуальную файловую систему (или аналог облачного диска). Среди бесплатных решений можно выделить FUSE-инструменты (для linux) типа s3fs.

Однако, чтобы перевести текущее веб-приложение на эту дешевую и очень эффективную с точки зрения бизнеса технологию, нужно попрограммировать и внести ряд изменений в существующий код и логику приложения.
В нашем продукте мы тщательно проанализировали вышеописанные кейсы веб-проектов, которым нужно быстро доставлять файлы клиентам, а иногда файлов — терабайты и более и реализовали данные возможности «из коробки» в модуле «Облачные хранилища».
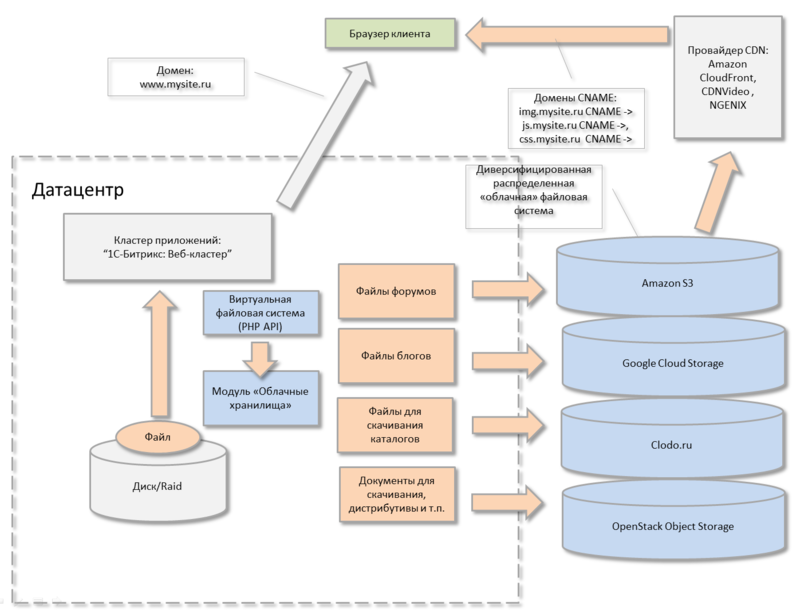
Мне честно нравится, что можно хранить данные отдельных модулей системы… в разных облачных хранилищах :-). Это реально диверсифицирует ваше файловое хранилище. Можно их раскидать в зависимости от адреса или типа клиента. Либо от типа информации — кто-то эффективно отдает легкую статику, кто-то тяжелый контент.
Не важно, на чем вы пишите веб-проект — рано или поздно обязательно столкнетесь с леденящей душу проблемой лавинообразного увеличения объема файлов для хранения и раздачи и должны будете принять верное архитектурное решение.
В статье мы рассмотрели основные этапы и принципы организации раздачи файлов на веб-решениях любого размера, взвесили плюсы и минусы, посмотрели как это реализовано в платформе «1С-Битрикс». С учетом того, что объем раздаваемой веб-проектами информации очень быстро растет, данные знания актуальны и обязательно пригодятся как архитекторам веб-приложений, так и менеджерам проектов.
И конечно приглашаю всех на наш облачный сервис «Битрикс24», в котором мы активно используем вышеописанные технологии. Всем удачи!
В последнее время наметился интересный тренд — быстрое «распухание» веб-проектов до бесконечности. Объем данных многих популярных сайтов растет все быстрее и быстрее, их нужно куда-то девать, при этом эффективно бэкапить (весело будет, если файлы на 500Т потеряются :-) ), и конечно супербыстро раздавать клиентам, чтобы все их могли качать, качать, качать… на высокой скорости.
Для системного администратора задача даже редкого, ежедневного резервного копирования такого объема файлов навевает мысли о суициде, а менеджер веб-проекта просыпается в холодном поту от мысли о предстоящей профилактике датацентра на 6 часов (чтобы файлы перевести из одного датацентра в другой нужно пару раз загрузить багажник автомобиля винчестерами :-) ).
Коллеги с умным видом советуют приобрести одно из решений от NetApp, но, жаль, что бюджет у проекта в 1000 раз меньше, это вообще стартап… что делать будем?
В статье хочу разобрать частые кейсы дешевого и дорогого решения данной задачи — от простого к сложному. В конце статьи расскажу как задача решена в нашем флагманском продукте — всегда полезно сравнивать opensource-решения с коммерческими, мозгам нужна гимнастика.
Доступ в гардероб HighLoad
Если Вы хоть раз посещали конференцию HighLoad, то наверняка знаете, что на входе нужно обязательно ответить на вопрос — почему ставят nginx перед apache? Иначе дальше гардероба не пройти ;-)
Правильно, nginx или аналогичный обратный прокси позволяет эффективно раздавать файлы, особенно по медленным каналам, серьезно снижая нагрузку на сервер и повышая в целом производительность веб-приложения: nginx раздает кучу файлов, apache или php-fpm обрабатывают запросы к серверу приложений.
Такие веб-приложения живут хорошо, пока объем файлов не увеличивается до, скажем десятков гигабайт — когда несколько сотен клиентов начинают одновременно скачивать файлы с сервера, а памяти для кэширования файлов в ОЗУ недостаточно — диск, а потом и RAID — просто умрет.
Сервер статики
Примерно на этом этапе нередко начинают сначала фиктивно, затем физически раздавать статические файлы с другого, желательно не отдающего много лишних cookies, домена. И это правильно — всем известно, что браузер клиента имеет ограничение на число коннектов в одному домену сайта и когда сайт вдруг начинает отдавать себя с двух и более доменов — скорость его загрузки в браузер клиента существенно возрастает.
Делают что-то типа:
- www.mysite.ru
- img.mysite.ru
- js.mysite.ru
- css.mysite.ru
- download.mysite.ru
- и т.п.
Чтобы более эффективно раздавать статику с разных доменов, ее выносят на отдельный сервер(а) статики:
Полезно на этом сервере использовать режим кэширования nginx и «быстрый» RAID (чтобы побольше клиентов требовалось для постановки диска «на колени»).
CDN — раздача
На этом этапе организаторы веб-проекта начинают понимать, что раздавать из своего датацентра даже с очень быстрых дисков или даже SAN — не всегда эффективно:
- Ценный клиент начал качать файл с московского сервера из Владивостока, да не из города, а с борта своей яхты. Канал конечно получился узкий.
- Случилась беда и уборщица случайно выдернула шнур питания из сервера раздачи статики, оборвав 10000 клиентов, качающих новый дистрибутив. Ну или в датацентре началась и «неизвестно» когда окончится профилактика — а точнее работы по поиску причины одновременного выхода из строя трех дизельных генераторов из двух.
- Наоборот, мог случиться такой наплыв клиентов, что стало не хватать серверной мощности раздавать одновременно столько статики, либо уже каналы загружены до предела.
В общем все понимают, что нужно быть как можно ближе к клиенту и отдавать клиенту столько статики, сколько он хочет, на максимально возможной быстрой скорости, а не сколько мы можем отдавать со своего сервера(ов).
Эти задачи в последнее время начала эффективно решать технология CDN.
Ваши файлы действительно становятся доступны клиенту на расстоянии вытянутой руки, откуда бы он их не начал качать: с Красной площади или с Сахалина — файлы будут отдаваться с ближайших ему серверов провайдера CDN.
«Вертикальное» масштабирование раздачи статики
На этом этапе веб-проект — постепенно распухает. Вы копите все больше и больше файлов для раздачи, храня их, можно сказать, централизованно в одном ДЦ на одном или группе серверов. Делать резервную копию такого количества файлов становится все дороже, дольше и сложнее. Полный бэкап делается неделю, приходится делать снепшоты, инкременты и прочие вещи, увеличивающие риск суицида.
Вы боитесь подумать о следующем:
- Рассыпятся диски на файловом хранилище (рейд10 может умереть, забрав с собой сразу пару зеркальных дисков и это — случается не очень редко) и придется доставать файлы из бэкапа в течении… двух-трех недель.
- В датацентре наконец-то научились считать количество дизель-генераторов, однако вас с утра обрадовали сообщением, что диски рассыпались, а ваши бэкапы в результате ошибки софта — безвозвратно повреждены (такое в амазоне с нами один раз произошло).
- Пройдет рекламная акция и начнется наплыв клиентов из Дальнего Востока или из Европы — и вы не справитесь с эффективной раздачей такого количества статики.
Да и вообще, вы вложили в инфраструктуру уже столько денег, а риски, причем немалые — остаются. Как-то нечестно получается.
Кружочки и колесики — распределенная файловая система
В этот момент у многих отключается левое, ответственное за логику, полушарие и их тянет к таинственным монстроподобным решениям — развернуть в нескольких датацентрах свою распределенную файловую систему. Возможно для проекта с большим бюджетом это будет выходом…
Тогда придется все это хозяйство администрировать самостоятельно, что потребует наличие видимо целого отдела эксплуатации :-)
Виртуальная файловая система
Одним из наиболее эффективных и, что важно, дешевых решений, является использование возможностей известных облачных провайдеров, дающих в аренду по очень вкусным, особенно при большом объеме данных, ценам, способ хранить неограниченный объем ваших файлов в облаке с очень высокой надежностью (гигантский DropBox). Провайдеры организовали на своих мощностях описанные выше распределенные файловые системы, высоконадежные и размещенные в нескольких датацентрах, разделенных территориально. Более того, эти сервисы, как правило, тесно интегрированы в сеть CDN данного провайдера. Т.е. вы будете не просто удобно и дешево хранить свои файлы, но и их максимально удобно для клиента раздавать.
Дело за малым — нужно настроить на своем веб-проекте прослойку или виртуальную файловую систему (или аналог облачного диска). Среди бесплатных решений можно выделить FUSE-инструменты (для linux) типа s3fs.
Однако, чтобы перевести текущее веб-приложение на эту дешевую и очень эффективную с точки зрения бизнеса технологию, нужно попрограммировать и внести ряд изменений в существующий код и логику приложения.
Модуль «Облачные хранилища» платформы «1С-Битрикс»
В нашем продукте мы тщательно проанализировали вышеописанные кейсы веб-проектов, которым нужно быстро доставлять файлы клиентам, а иногда файлов — терабайты и более и реализовали данные возможности «из коробки» в модуле «Облачные хранилища».
Мне честно нравится, что можно хранить данные отдельных модулей системы… в разных облачных хранилищах :-). Это реально диверсифицирует ваше файловое хранилище. Можно их раскидать в зависимости от адреса или типа клиента. Либо от типа информации — кто-то эффективно отдает легкую статику, кто-то тяжелый контент.
Итоги
Не важно, на чем вы пишите веб-проект — рано или поздно обязательно столкнетесь с леденящей душу проблемой лавинообразного увеличения объема файлов для хранения и раздачи и должны будете принять верное архитектурное решение.
В статье мы рассмотрели основные этапы и принципы организации раздачи файлов на веб-решениях любого размера, взвесили плюсы и минусы, посмотрели как это реализовано в платформе «1С-Битрикс». С учетом того, что объем раздаваемой веб-проектами информации очень быстро растет, данные знания актуальны и обязательно пригодятся как архитекторам веб-приложений, так и менеджерам проектов.
И конечно приглашаю всех на наш облачный сервис «Битрикс24», в котором мы активно используем вышеописанные технологии. Всем удачи!
