Одним из наиболее частых требований-"хотелок" бизнеса является построение всяких разных рейтингов - "самые оборотистые клиенты", "самые продаваемые позиции", "самые активные сотрудники", … - любимая тема разных дашбордов.
Например, в нашем решении для автоматизации ресторанов и кафе Presto очень популярен такой:
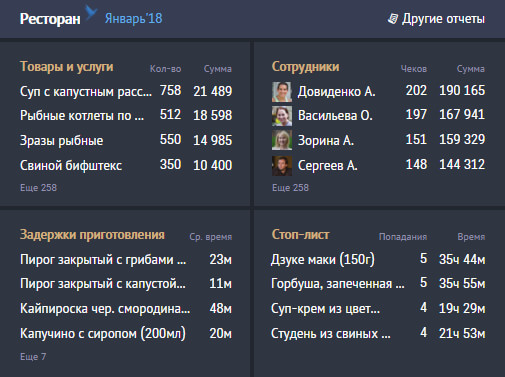
Но просто "самые" за весь доисторический период обычно неинтересны - продал ты 3 года назад вагон валенок, и теперь он у тебя в "самых" продажах вечно. Поэтому обычно хочется видеть "топ" на каком-то ограниченном последнем интервале - например, "за последний год" (точнее, за последние 12 календарных месяцев).
Традиционно, есть два подхода к этой задаче: запрос по требованию по "сырым" данным или предварительная агрегация. И если "просто посчитать" такой отчет по первичке - упражнение для SQL-новичка, но очень "тяжелое" для производительности СУБД, то вариант сделать так, чтобы он строился практически мгновенно при большом количестве активных аккаунтов независимых бизнесов, как у нас в СБИС, без необходимости пересчитывать агрегированную статистику каждого 1-го числа месяца судорожно по всем клиентам - интересная задача.
Структура хранения
Для начала поймем, что "быстро" может быть только в том случае, когда мы можем просто пройти по "верхушке" нужного индекса и извлечь искомые TOP-10 записей - без всяких суммирований и пересортировок.
То есть для решения задачи нам достаточно таблицы с единственным индексом (рассмотрим только вариант сортировки по сумме, для количества все будет аналогично):
CREATE TABLE item_stat(
item -- товар
integer
, sum
numeric(32,2)
);
CREATE INDEX ON item_stat(sum DESC);Наполнять ее данными мы можем легко и просто - инкрементом в триггере при проведении продажи. Но как все-таки сделать эффективное "вычитание" данных при завершении месяца?..
"Нужно больше золота"
Чтобы быстро что-то вычесть, нужно четко понимать, что именно.
В нашем случае - это продажи за 12-й месяц "назад" при пересечении границы. То есть наступил июнь - из общих счетчиков нужно вычесть все данные за июнь прошлого года. А для этого их нам нужно хранить отдельно от "годичных", из-за чего таблица принимает структуру:
CREATE TABLE item_stat(
interval_id -- 0 - текущие счетчики, 202001 - январь 2020, 202002 - февраль, ...
integer
, item
integer
, sum
numeric(32,2)
, UNIQUE(interval_id, item)
);
CREATE INDEX ON item_stat(interval_id, sum DESC);Момент обновления
Чтобы понять, что вот прямо сейчас надо "вычесть" какой-то месяц, достаточно оперировать единственным дополнительным параметром типа "месяц последней актуализации рейтинга продаж". Хранить его можно даже в служебной записи в этой же таблице (если это не помешает Foreign Key, который вы можете захотеть добавить на item):
INSERT INTO item_stat(
interval_id
, item
, sum
)
VALUES
(0, 0, 202012) -- служебный ключ (0, 0), значение - 2020'12 вместо суммы
ON CONFLICT(interval_id, item)
DO UPDATE SET
sum = EXCLUDED.sum; -- всегда заменяем значениеТеперь при операции над продажей (отгрузка/аннулирование) вызываем, можно асинхронно, инкремент/декремент сразу для двух записей - "годичной" и текущего месяца:
INSERT INTO item_stat(
interval_id
, item
, sum
)
VALUES
(202001, 1, 100) -- + в рейтинг за январь 2020
, ( 0, 1, 100) -- + в текущий рейтинг
ON CONFLICT(interval_id, item)
DO UPDATE SET
sum = item_stat.sum + EXCLUDED.sum; -- всегда добавляем в сумму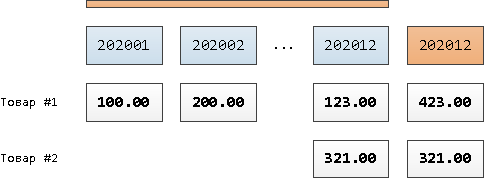
Если текущий месяц операции разошелся с месяцем из параметра, асинхронно стартуем пересчет "годовых" значений, вычитая показатели за ставшие избыточными месяцы, и переактуализируем значение параметра:
-- "новый" месяц актуальности
WITH next AS (
SELECT 202101
)
-- предыдущий месяц актуальности
, prev AS (
SELECT
sum::integer
FROM
item_stat
WHERE
(interval_id, item) = (0, 0)
)
-- все продажи за период, ставший неактуальным, в разрезе товаров
, diff AS (
SELECT
item
, sum(sum) sum
FROM
item_stat
WHERE
interval_id BETWEEN (TABLE prev) - 100 AND (TABLE next) - 100
GROUP BY
1
)
UPDATE
item_stat dst
SET
sum = dst.sum - diff.sum
FROM
diff
WHERE
(dst.interval_id, dst.item) = (0, diff.item);
UPDATE
item_stat
SET
sum = 202101
WHERE
(interval_id, item) = (0, 0);
При построении отчета
Если текущий месяц совпадает с месяцем из параметра, то все значения в "годичном" интервале актуальны - просто выводим топ по индексу:
SELECT
*
FROM
item_stat
WHERE
interval_id = 0 -- текущий "годичный" интервал
ORDER BY
sum DESC
LIMIT 10;Если не совпадает (то есть наступил новый месяц, но продаж еще не было) - синхронно пересчитываем, как было описано выше (немного потупит, но всего один раз за месяц) и потом показываем, как описано выше.
