Профессор Никлаус Вирт был прав. Создатель языка Pascal, соавтор технологии структурного программирования, лауреат премии Тьюринга в 1995 году заметил:
С тех пор это высказывание считается законом Вирта. Он фактически нивелирует закон Мура, согласно которому количество транзисторов в процессорах удваивается примерно с 1965 года. Вот что пишет Вирт в статье «Призыв к стройному софту»:
С этим трудно не согласиться.
Проблема разработки современного программного обеспечения стоит очень остро. Вирт указывает на один важный аспект: время. Он предполагает, что главной причиной появления раздутого программного обеспечения является нехватка времени на разработку.
Сегодня появилась ещё одна причина ожирения софта — абстракция. И это гораздо более серьёзная проблема. Разработчики никогда не писали программы с нуля, но раньше это не вызывало осложнений.
Дейкстра и Вирт пытались улучшить качество кода и разработали концепцию структурированного программирования. Они хотели вывести программирование из кризиса, и в течение некоторого времени программирование рассматривалось как настоящее ремесло для настоящих профессионалов. Программисты заботились о качестве программ, ценили ясность и эффективность кода.
Те времена прошли.
С появлением языков более высокого уровня, таких как Java, Ruby, PHP и Javascript, к 1995 году, когда Вирт написал свою статью, программирование стало более абстрактным. Новые языки значительно облегчали программирование и многое брали на себя. Они были объектно-ориентированными и поставлялись в комплекте с с такими вещами, как IDE и сборка мусора.
Программистам стало легче жить, но за всё приходится платить. Чем легче жить, тем меньше думать. Примерно в середине 90-х программисты перестали думать о качестве своих программ, пишет разработчик Робин Мартин в своей статье «Никлаус Вирт был прав, и в этом проблема». В то же время началось широкое использование библиотек, функциональность которых всегда намного больше, чем необходимо для конкретной программы.
Поскольку библиотека не создана для одного конкретного проекта, она, вероятно, имеет немного больше функциональных возможностей, чем действительно нужно. Никаких проблем, скажете вы. Однако всё накапливается довольно быстро. Даже люди, которые любят библиотеки, не хотят изобретать велосипед. Это приводит к тому, что называется адом зависимостей. Никола Дуза написал пост об этой проблеме в Javascript.
Проблема не кажется такой уж большой, но в реальности она серьёзнее, чем вы можете подумать. Например, Никола Дуза написал простое приложение для ведения списка дел. Оно работает в вашем браузере с HTML и Javascript. Как вы думаете, сколько зависимостей оно использовало? 13 000. Тринадцать. Тысяч. Пруф.
Цифры безумны, но проблема будет только расти. По мере создания новых библиотек число зависимостей в каждом проекте также будет увеличиваться.
Это означает, что проблема, о которой предупреждал Никлаус Вирт в 1995 году, со временем только усугубится.
Что делать?
Робин Мартин предполагает, что хороший способ приступить к решению проблемы — разделить библиотеки. Вместо того, чтобы создавать одну большую библиотеку, которая делает всё возможное, просто создать много библиотек.
Таким образом, программист должен только выбрать библиотеки, которые ему действительно нужны, игнорируя функциональные возможности, которые он не собирается использовать. Мало того, что он сам устанавливает меньше зависимостей, но и в используемых библиотеках тоже будет меньше своих зависимостей.
К сожалению, миниатюризация транзисторов не может продолжаться вечно и имеет свои физические пределы. Возможно, рано или поздно закон Мура прекратит действовать. Некоторые говорят, что это уже произошло. В последние десять лет тактовая частота и мощность отдельных ядер процессоров уже перестала расти, как раньше.
Хотя хоронить его рано. Есть ряд новых технологий, которые обещают прийти на смену кремниевой микроэлектронике. Например, Intel, Samsung и другие компании экспериментируют с транзисторами на углеродных наноструктурах (нанонитях), а также с фотонными чипами.

Эволюция транзисторов. Иллюстрация: Samsung
Но некоторые исследователи подходят с другой стороны. Они предлагают новые системные подходы к программированию, чтобы значительно повысить эффективность будущего программного обеспечения. Таким образом, можно «перезапустить» закон Мура программными методами, как бы фантастически это не звучало в свете наблюдений Никлауса Вирта об ожирении программ. Но вдруг у нас получится обернуть эту тенденцию вспять?
Недавно в журнале Science была опубликована интересная статья учёных из лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института (CSAIL MIT). Они выделяют три приоритетные области для дальнейшего ускорения вычислений:
Ведущий автор научной работы Чарльз Лейзерсон подтверждает тезис об ожирении ПО. Он говорит, что выгоды миниатюризации транзисторов были настолько велики, что на протяжении десятилетий программисты могли уделять приоритетное внимание упрощению написания кода, а не ускорению его выполнения. С неэффективностью можно было смириться, потому что более быстрые компьютерные чипы всегда компенсировали ожирение ПО.
«Но в настоящее время для достижения дальнейших успехов в таких областях, как машинное обучение, робототехника и виртуальная реальность, потребуются огромные вычислительные мощности, которые миниатюризация уже не может обеспечить, — говорит Лейзерсон. — Если мы хотим использовать весь потенциал этих технологий, мы должны изменить наш подход к вычислениям».
В части программного обеспечения предлагается пересмотреть стратегию использования библиотек с излишней функциональностью, потому что это является источником неэффективности. Авторы рекомендуют сконцентрироваться на главной задаче — повышении скорости выполнения программ, а не на скорости написания кода.
Во многих случаях производительность действительно можно повысить в тысячи раз, и это не преувеличение. В качестве примера исследователи приводят перемножение двух матриц 4096×4096. Они начали с реализации на Python как одного из самых популярных языков высокого уровня. Например, вот реализация в четыре строки на Python 2:
В коде три вложенных цикла, а алгоритм решения основан на школьной программе по алгебре.
Но оказывается, что этот наивный подход слишком неэффективно использует вычислительную мощность. На современном компьютере он будет выполняться около семи часов, как показано в таблице ниже.
Переход на более эффективный язык программирования уже кардинально повышает скорость выполнения кода. Например, программа на Java будет выполняться в 10,8 раз быстрее, а программа на С — ещё в 4,4 раза быстрее, чем на Java. Таким образом, переход с Python на C означает повышение скорости выполнения программы в 47 раз.
И это только начало оптимизации. Если писать код с учётом особенностей аппаратного обеспечения, на котором он будет выполняться, то можно повысить скорость ещё в 1300 раз. В данном эксперименте код сначала запустили параллельно на всех 18 ядрах CPU (версия 4), затем использовали иерархию кэшей процессора (версия 5), добавили векторизацию (версия 6) и применили специфические инструкции Advanced Vector Extensions (AVX) в версии 7. Последняя оптимизированная версия кода выполняется уже не 7 часов, а всего 0,41 секунды, то есть более чем в 60 000 раз быстрее оригинального кода на Python.
Более того, на графической карте AMD FirePro S9150 тот же код выполняется всего за 70 мс, то есть в 5,4 раза быстрее, чем самая оптимизированная версия 7 на процессоре общего назначения, и в 360 000 раз быстрее, чем версия 1.
Что касается алгоритмов, исследователи предлагают трёхсторонний подход, который включает в себя изучение новых проблемных областей, масштабирование алгоритмов и их адаптацию к лучшему использованию преимуществ современного оборудования.
Например, алгоритм Штрассена для перемножения матриц ещё на 10% ускоряет самую быструю версию кода номер 7. Для других проблем новые алгоритмы обеспечивают ещё большую прибавку в производительности. Например, на следующей диаграмме показан прогресс в эффективности алгоритмов для решения задачи о максимальном потоке, достигнутый в 1975−2015 годы. Каждый новый алгоритм увеличивал скорость вычислений буквально на несколько порядков, а в последующие годы ещё оптимизировался.
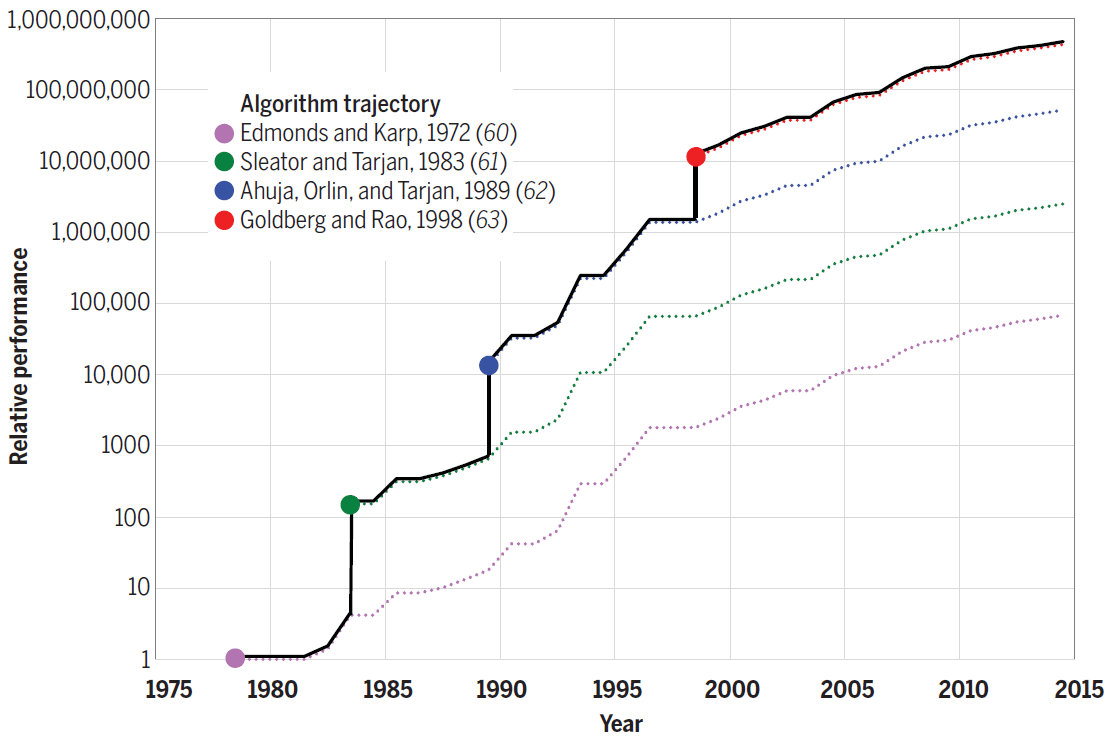
Эффективность алгоритмов для решения задачи о максимальном потоке на графе с n=1012 вершин и m=n11 рёбер
Таким образом, улучшение алгоритмов тоже вносит свой вклад в то, чтобы «эмулировать» закон Мура программным путём.
Наконец, с точки зрения аппаратной архитектуры, исследователи выступают за оптимизацию аппаратного обеспечения таким образом, чтобы проблемы можно было решить с меньшим количеством транзисторов. Оптимизация включает в себя использование более простых процессоров и создание аппаратного обеспечения, адаптированного к конкретным приложениям, как графический процессор адаптирован для компьютерной графики.
«Оборудование, настроенное для конкретных областей, может быть гораздо более эффективным и использовать гораздо меньше транзисторов, позволяя приложениям работать в десятки и сотни раз быстрее, — говорит Тао Шардль, соавтор научной работы. — В более общем плане оптимизация аппаратного обеспечения будет ещё больше стимулировать параллельное программирование, создавая на микросхеме дополнительные области для параллельного использования».
Тренд на параллелизацию виден уже сейчас. Как показано на диаграмме, в последние годы производительность CPU растёт исключительно благодаря увеличению количества ядер.
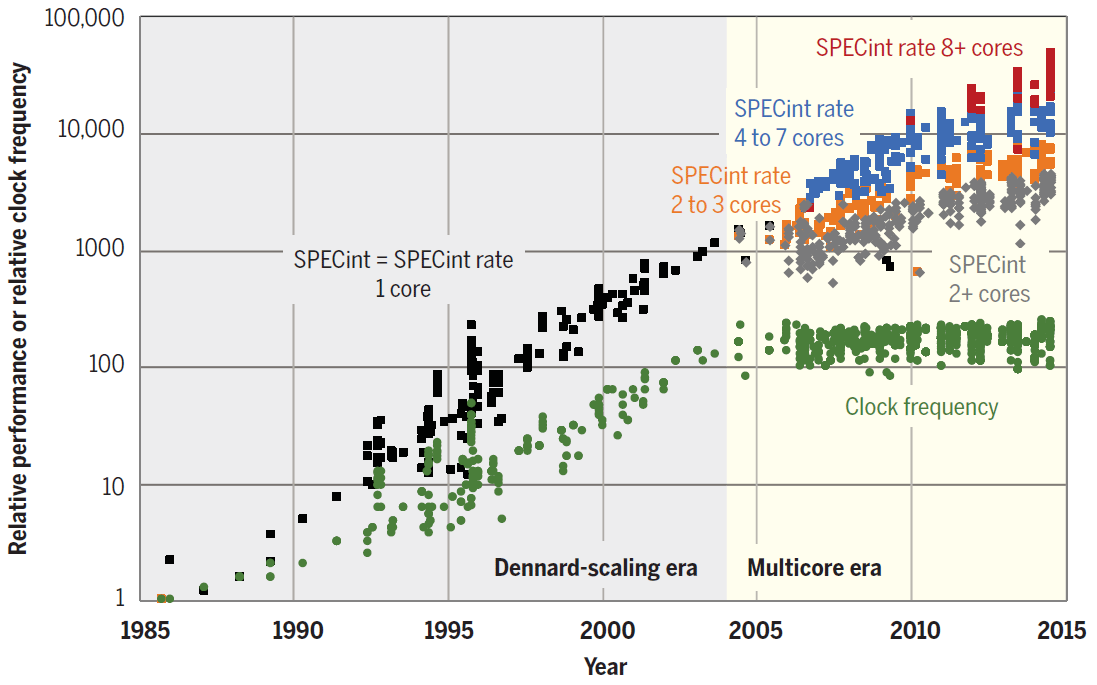
Производительность по тесту SPECint отдельных ядер, а также одно- и многоядерных процессоров с 1985 по 2015 годы. В качестве базовой единицы взят микропроцессор 80386 DX образца 1985 года
Для операторов дата-центров даже минимальное улучшение производительности ПО может означать большую финансовую выгоду. Неудивительно, что сейчас инициативы по разработке собственных специализированных CPU ведут такие компании как Google и Amazon. Первая выпустила тензорные (нейронные) процессоры Google TPU, а в дата-центрах Amazon работают чипы AWS Graviton.
За лидерами отрасли со временем могут последовать владельцы других ЦОД, чтобы не проиграть конкурентам в эффективности.
Исследователи пишут, что раньше стремительный рост производительности процессоров общего назначения ограничивал возможности для развития специализированных процессоров. Сейчас такого ограничения нет.
«Рост производительности потребует новых инструментов, языков программирования и аппаратного обеспечения, чтобы обеспечить более эффективное проектирование с прицелом на скорость, — говорит профессор Чарльз Лейзерсон, соавтор научной работы. — Это также означает, что программистам следует лучше понимать, как сочетается софт, алгоритмы и аппаратное обеспечение, а не рассматривать их по отдельности».
С другой стороны, инженеры экспериментируют с технологиями, которые могут обеспечить дальнейший рост производительности CPU. Это квантовые вычисления, 3D-компоновка, микросхемы со сверхпроводимостью, нейроморфные вычисления, использование графена вместо кремния и др. Но пока эти технологии на стадии экспериментов.
Если производительность CPU в самом деле перестанет расти, то мы окажемся в совершенно другой реальности. Возможно, нам в действительно придётся пересмотреть наши приоритеты в программировании, а специалисты по ассемблеру станут на вес золота.
Нужен мощный сервер? Наша компания предлагает эпичные серверы - виртуальные серверы с CPU AMD EPYC, частота ядра CPU до 3.4 GHz. Максимальная конфигурация впечатлит любого — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe.

«Замедление программ происходит куда быстрее, чем ускорение компьютеров»
С тех пор это высказывание считается законом Вирта. Он фактически нивелирует закон Мура, согласно которому количество транзисторов в процессорах удваивается примерно с 1965 года. Вот что пишет Вирт в статье «Призыв к стройному софту»:
«Около 25 лет назад интерактивный текстовый редактор умещался всего в 8000 байт, а компилятор в 32 килобайта, тогда как их современные потомки требуют мегабайтов. Стало ли всё это раздутое программное обеспечение быстрее? Нет, совсем наоборот. Если бы не в тысячу раз более быстрое железо, то современное программное обеспечение было бы совершенно непригодным».
С этим трудно не согласиться.
Ожирение софта
Проблема разработки современного программного обеспечения стоит очень остро. Вирт указывает на один важный аспект: время. Он предполагает, что главной причиной появления раздутого программного обеспечения является нехватка времени на разработку.
Сегодня появилась ещё одна причина ожирения софта — абстракция. И это гораздо более серьёзная проблема. Разработчики никогда не писали программы с нуля, но раньше это не вызывало осложнений.
Дейкстра и Вирт пытались улучшить качество кода и разработали концепцию структурированного программирования. Они хотели вывести программирование из кризиса, и в течение некоторого времени программирование рассматривалось как настоящее ремесло для настоящих профессионалов. Программисты заботились о качестве программ, ценили ясность и эффективность кода.
Те времена прошли.
С появлением языков более высокого уровня, таких как Java, Ruby, PHP и Javascript, к 1995 году, когда Вирт написал свою статью, программирование стало более абстрактным. Новые языки значительно облегчали программирование и многое брали на себя. Они были объектно-ориентированными и поставлялись в комплекте с с такими вещами, как IDE и сборка мусора.
Программистам стало легче жить, но за всё приходится платить. Чем легче жить, тем меньше думать. Примерно в середине 90-х программисты перестали думать о качестве своих программ, пишет разработчик Робин Мартин в своей статье «Никлаус Вирт был прав, и в этом проблема». В то же время началось широкое использование библиотек, функциональность которых всегда намного больше, чем необходимо для конкретной программы.
Поскольку библиотека не создана для одного конкретного проекта, она, вероятно, имеет немного больше функциональных возможностей, чем действительно нужно. Никаких проблем, скажете вы. Однако всё накапливается довольно быстро. Даже люди, которые любят библиотеки, не хотят изобретать велосипед. Это приводит к тому, что называется адом зависимостей. Никола Дуза написал пост об этой проблеме в Javascript.
Проблема не кажется такой уж большой, но в реальности она серьёзнее, чем вы можете подумать. Например, Никола Дуза написал простое приложение для ведения списка дел. Оно работает в вашем браузере с HTML и Javascript. Как вы думаете, сколько зависимостей оно использовало? 13 000. Тринадцать. Тысяч. Пруф.
Цифры безумны, но проблема будет только расти. По мере создания новых библиотек число зависимостей в каждом проекте также будет увеличиваться.
Это означает, что проблема, о которой предупреждал Никлаус Вирт в 1995 году, со временем только усугубится.
Что делать?
Робин Мартин предполагает, что хороший способ приступить к решению проблемы — разделить библиотеки. Вместо того, чтобы создавать одну большую библиотеку, которая делает всё возможное, просто создать много библиотек.
Таким образом, программист должен только выбрать библиотеки, которые ему действительно нужны, игнорируя функциональные возможности, которые он не собирается использовать. Мало того, что он сам устанавливает меньше зависимостей, но и в используемых библиотеках тоже будет меньше своих зависимостей.
Конец закона Мура
К сожалению, миниатюризация транзисторов не может продолжаться вечно и имеет свои физические пределы. Возможно, рано или поздно закон Мура прекратит действовать. Некоторые говорят, что это уже произошло. В последние десять лет тактовая частота и мощность отдельных ядер процессоров уже перестала расти, как раньше.
Хотя хоронить его рано. Есть ряд новых технологий, которые обещают прийти на смену кремниевой микроэлектронике. Например, Intel, Samsung и другие компании экспериментируют с транзисторами на углеродных наноструктурах (нанонитях), а также с фотонными чипами.
Эволюция транзисторов. Иллюстрация: Samsung
Но некоторые исследователи подходят с другой стороны. Они предлагают новые системные подходы к программированию, чтобы значительно повысить эффективность будущего программного обеспечения. Таким образом, можно «перезапустить» закон Мура программными методами, как бы фантастически это не звучало в свете наблюдений Никлауса Вирта об ожирении программ. Но вдруг у нас получится обернуть эту тенденцию вспять?
Методы ускорения программного обеспечения
Недавно в журнале Science была опубликована интересная статья учёных из лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института (CSAIL MIT). Они выделяют три приоритетные области для дальнейшего ускорения вычислений:
- лучшее программное обеспечение;
- новые алгоритмы;
- более оптимизированное железо.
Ведущий автор научной работы Чарльз Лейзерсон подтверждает тезис об ожирении ПО. Он говорит, что выгоды миниатюризации транзисторов были настолько велики, что на протяжении десятилетий программисты могли уделять приоритетное внимание упрощению написания кода, а не ускорению его выполнения. С неэффективностью можно было смириться, потому что более быстрые компьютерные чипы всегда компенсировали ожирение ПО.
«Но в настоящее время для достижения дальнейших успехов в таких областях, как машинное обучение, робототехника и виртуальная реальность, потребуются огромные вычислительные мощности, которые миниатюризация уже не может обеспечить, — говорит Лейзерсон. — Если мы хотим использовать весь потенциал этих технологий, мы должны изменить наш подход к вычислениям».
В части программного обеспечения предлагается пересмотреть стратегию использования библиотек с излишней функциональностью, потому что это является источником неэффективности. Авторы рекомендуют сконцентрироваться на главной задаче — повышении скорости выполнения программ, а не на скорости написания кода.
Во многих случаях производительность действительно можно повысить в тысячи раз, и это не преувеличение. В качестве примера исследователи приводят перемножение двух матриц 4096×4096. Они начали с реализации на Python как одного из самых популярных языков высокого уровня. Например, вот реализация в четыре строки на Python 2:
for i in xrange(4096):
for j in xrange(4096):
for k in xrange(4096):
C[i][j] += A[i][k] * B[k][j]В коде три вложенных цикла, а алгоритм решения основан на школьной программе по алгебре.
Но оказывается, что этот наивный подход слишком неэффективно использует вычислительную мощность. На современном компьютере он будет выполняться около семи часов, как показано в таблице ниже.
| Версия | Реализация | Время выполнения (с) | GFLOPS | Абсолютное ускорение | Относительное ускорение | Процент от пиковой производительности |
|---|---|---|---|---|---|---|
| 1 | Python | 25552,48 | 0,005 | 1 | — | 0,00 |
| 2 | Java | 2372,68 | 0,058 | 11 | 10,8 | 0,01 |
| 3 | C | 542,67 | 0,253 | 47 | 4,4 | 0,03 |
| 4 | Параллельные циклы | 69,80 | 1,97 | 366 | 7,8 | 0,24 |
| 5 | Парадигма «Разделяй и властвуй» | 3,80 | 36,18 | 6727 | 18,4 | 4,33 |
| 6 | + векторизация | 1,10 | 124,91 | 23224 | 3,5 | 14,96 |
| 7 | + интристики AVX | 0,41 | 337,81 | 52806 | 2,7 | 40,45 |
Переход на более эффективный язык программирования уже кардинально повышает скорость выполнения кода. Например, программа на Java будет выполняться в 10,8 раз быстрее, а программа на С — ещё в 4,4 раза быстрее, чем на Java. Таким образом, переход с Python на C означает повышение скорости выполнения программы в 47 раз.
И это только начало оптимизации. Если писать код с учётом особенностей аппаратного обеспечения, на котором он будет выполняться, то можно повысить скорость ещё в 1300 раз. В данном эксперименте код сначала запустили параллельно на всех 18 ядрах CPU (версия 4), затем использовали иерархию кэшей процессора (версия 5), добавили векторизацию (версия 6) и применили специфические инструкции Advanced Vector Extensions (AVX) в версии 7. Последняя оптимизированная версия кода выполняется уже не 7 часов, а всего 0,41 секунды, то есть более чем в 60 000 раз быстрее оригинального кода на Python.
Более того, на графической карте AMD FirePro S9150 тот же код выполняется всего за 70 мс, то есть в 5,4 раза быстрее, чем самая оптимизированная версия 7 на процессоре общего назначения, и в 360 000 раз быстрее, чем версия 1.
Что касается алгоритмов, исследователи предлагают трёхсторонний подход, который включает в себя изучение новых проблемных областей, масштабирование алгоритмов и их адаптацию к лучшему использованию преимуществ современного оборудования.
Например, алгоритм Штрассена для перемножения матриц ещё на 10% ускоряет самую быструю версию кода номер 7. Для других проблем новые алгоритмы обеспечивают ещё большую прибавку в производительности. Например, на следующей диаграмме показан прогресс в эффективности алгоритмов для решения задачи о максимальном потоке, достигнутый в 1975−2015 годы. Каждый новый алгоритм увеличивал скорость вычислений буквально на несколько порядков, а в последующие годы ещё оптимизировался.
Эффективность алгоритмов для решения задачи о максимальном потоке на графе с n=1012 вершин и m=n11 рёбер
Таким образом, улучшение алгоритмов тоже вносит свой вклад в то, чтобы «эмулировать» закон Мура программным путём.
Наконец, с точки зрения аппаратной архитектуры, исследователи выступают за оптимизацию аппаратного обеспечения таким образом, чтобы проблемы можно было решить с меньшим количеством транзисторов. Оптимизация включает в себя использование более простых процессоров и создание аппаратного обеспечения, адаптированного к конкретным приложениям, как графический процессор адаптирован для компьютерной графики.
«Оборудование, настроенное для конкретных областей, может быть гораздо более эффективным и использовать гораздо меньше транзисторов, позволяя приложениям работать в десятки и сотни раз быстрее, — говорит Тао Шардль, соавтор научной работы. — В более общем плане оптимизация аппаратного обеспечения будет ещё больше стимулировать параллельное программирование, создавая на микросхеме дополнительные области для параллельного использования».
Тренд на параллелизацию виден уже сейчас. Как показано на диаграмме, в последние годы производительность CPU растёт исключительно благодаря увеличению количества ядер.
Производительность по тесту SPECint отдельных ядер, а также одно- и многоядерных процессоров с 1985 по 2015 годы. В качестве базовой единицы взят микропроцессор 80386 DX образца 1985 года
Для операторов дата-центров даже минимальное улучшение производительности ПО может означать большую финансовую выгоду. Неудивительно, что сейчас инициативы по разработке собственных специализированных CPU ведут такие компании как Google и Amazon. Первая выпустила тензорные (нейронные) процессоры Google TPU, а в дата-центрах Amazon работают чипы AWS Graviton.
За лидерами отрасли со временем могут последовать владельцы других ЦОД, чтобы не проиграть конкурентам в эффективности.
Исследователи пишут, что раньше стремительный рост производительности процессоров общего назначения ограничивал возможности для развития специализированных процессоров. Сейчас такого ограничения нет.
«Рост производительности потребует новых инструментов, языков программирования и аппаратного обеспечения, чтобы обеспечить более эффективное проектирование с прицелом на скорость, — говорит профессор Чарльз Лейзерсон, соавтор научной работы. — Это также означает, что программистам следует лучше понимать, как сочетается софт, алгоритмы и аппаратное обеспечение, а не рассматривать их по отдельности».
С другой стороны, инженеры экспериментируют с технологиями, которые могут обеспечить дальнейший рост производительности CPU. Это квантовые вычисления, 3D-компоновка, микросхемы со сверхпроводимостью, нейроморфные вычисления, использование графена вместо кремния и др. Но пока эти технологии на стадии экспериментов.
Если производительность CPU в самом деле перестанет расти, то мы окажемся в совершенно другой реальности. Возможно, нам в действительно придётся пересмотреть наши приоритеты в программировании, а специалисты по ассемблеру станут на вес золота.
На правах рекламы
Нужен мощный сервер? Наша компания предлагает эпичные серверы - виртуальные серверы с CPU AMD EPYC, частота ядра CPU до 3.4 GHz. Максимальная конфигурация впечатлит любого — 128 ядер CPU, 512 ГБ RAM, 4000 ГБ NVMe.
