
Распознавание некоторых современных CAPTCHA
15 мин
Именно так называлась работа, представленная мной на Балтийском научно-инженерном конкурсе, и принёсшая мне очаровательную бумажку с римской единичкой, а также новенький ноутбук.
Работа заключалась в распознавании CAPTCHA, используемых крупными операторами сотовой связи в формах отправки SMS, и демонстрации недостаточной эффективности применяемого ими подхода. Чтобы не задевать ничью гордость, будем называть этих операторов иносказательно: красный, жёлтый, зелёный и синий.
Работа заключалась в распознавании CAPTCHA, используемых крупными операторами сотовой связи в формах отправки SMS, и демонстрации недостаточной эффективности применяемого ими подхода. Чтобы не задевать ничью гордость, будем называть этих операторов иносказательно: красный, жёлтый, зелёный и синий.
 Эта статья представляет собой описание компонента HexaPath, реализующего поиск пути по алгоритму А* в гексагональной сетке. В сети мной было найдено большое количество описаний алгоритма на примере квадратной сетки и некоторое количество реализаций, но ни одного упоминания о шестиугольной сетке. И я написал свою реализацию. Выкладываю исходники. Вдруг кому-нибудь понадобится это, а писать самому будет лень.
Эта статья представляет собой описание компонента HexaPath, реализующего поиск пути по алгоритму А* в гексагональной сетке. В сети мной было найдено большое количество описаний алгоритма на примере квадратной сетки и некоторое количество реализаций, но ни одного упоминания о шестиугольной сетке. И я написал свою реализацию. Выкладываю исходники. Вдруг кому-нибудь понадобится это, а писать самому будет лень.
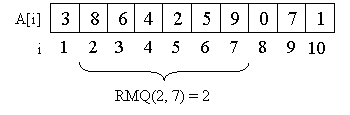



 Судоку — популярная головоломка, основной задачей которой является размещение цифр в правильном порядке.
Судоку — популярная головоломка, основной задачей которой является размещение цифр в правильном порядке.