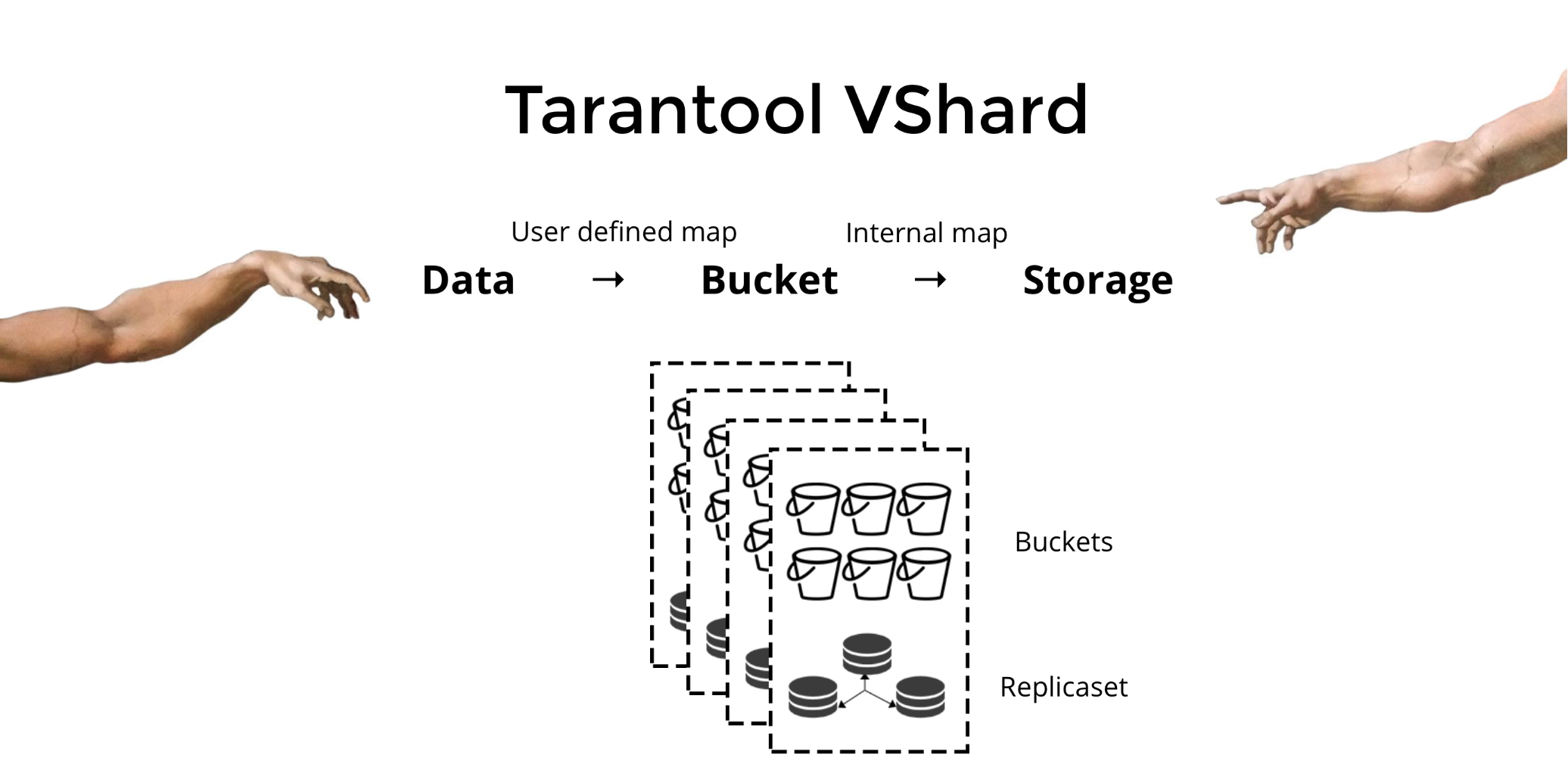
[Because my extension got a lot of attention from the foreign audience, I translated my original article into English].
Limit
Being a top-rated professional network, LinkedIn, unfortunately, for free accounts, has such a limitation as
Commercial Use Limit (CUL). Most likely, you, same as me until recently, have never encountered and never heard about this thing.
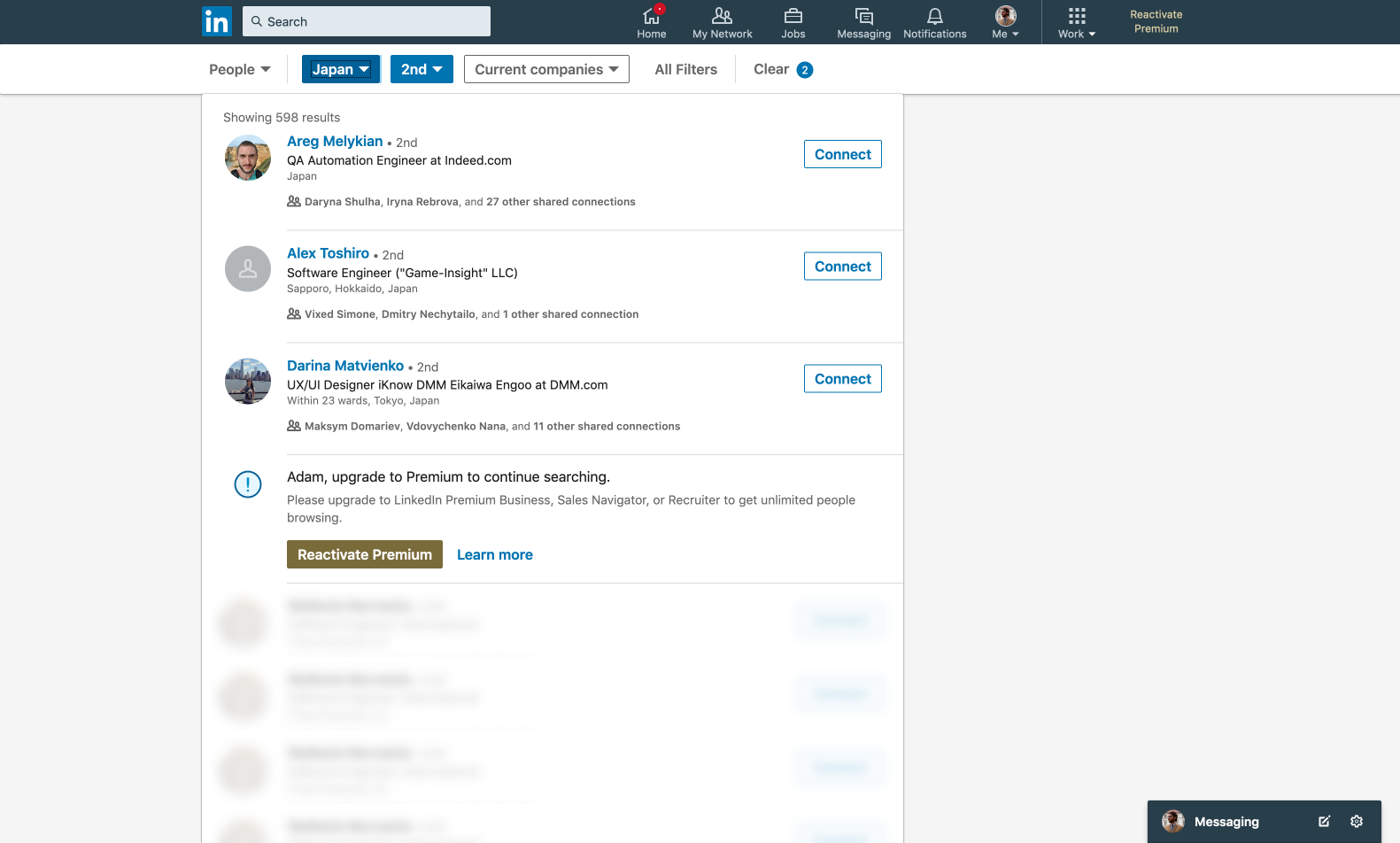
The point of the CUL is that when you search people outside your connections/network too often, your search results will be limited with only 3 profiles showing instead of 1000 (100 pages with 10 profiles per page by default). How ‘often’ is measured nobody knows, there are no precise metrics; the algorithm decides it based on your actions – how frequently you’ve been searching and how many connections you’ve been adding. The free CUL resets at midnight PST on the 1st of each calendar month, and you get your 1000 search results again, for who knows how long. Of course,
Premium accounts have no such limit in place.
However, not so long ago, I’ve started messing around with LinkedIn search for some pet-project, and suddenly got stuck with this CUL. Obviously, I didn’t like it that much; after all, I haven’t been using the search for any commercial purposes. So, my first thought was to explore this limit and try to bypass it.
[Important clarification — all source materials in this article are presented solely for informational and educational purposes. The author doesn't encourage their use for commercial purposes.]