Продолжение статьи «Взаимодействие звеньев и их изоляция.» часть 1
Хочу извиниться перед общественностью за то, что разбил статью на две части. Но в последнее время большие тексты перестали приниматься Хабром. Если кто-то подскажет как с этой напастью справиться: буду благодарен.
От старых привычек тяжело избавляться, потому многим командам будет тяжело перейти к изолированному подходу. Для внедрения изолированного подхода хорошо подойдет распределение ролей. Кроме того, от распределения ролей будут получены дополнительные выгоды, в т.ч. более быстрая и качественная разработка.
Для того чтобы предотвратить некорректное распределение работы в звеньях, разработчики привязываются к определенному слою. Работа над определенным слоем называется ролью.

Хотя разработчики и должны быть привязаны к определенной роли, им нужно иметь возможность мигрировать между различными ролями.
В малых командах передача ролей может позволить лучше распределить ресурсы. Передача ролей в больших командах позволит разработчикам понять систему целиком, осознать влияние их разработок на реализацию соседних звеньев, и обезопасить систему от влияния отдельного разработчика, заболевшего или покинувшего компанию.
Передача ролей, тем не менее, не должна осуществляться как придется и требует контроля. Разработчики должны принимать определенные роли в определенное время. По возможности, разработчик не должен принимать более одной роли в пределах одного модуля. Если в системе есть модуль «Покупатель», каждому разработчику не должно быть назначено более одной роли в пределах модуля «Покупатель». Однако, если разработчик работает над слоем бизнес-логики в модуле «Покупатель», а потом переключается на разработку слоя представления в модуле «Поставщик», это допустимо и позволяет более эффективно распределить ресурсы.
Следующий рисунок демонстрирует пример правильного распределения ролей.

Следующий рисунок показывает неверное распределение ролей. И Джо, и Адам работают в разных ролях в пределах одного модуля. Такие нарушения приводят к тесной связи и потере изолированности между слоями.

Предыдущий пример очень прост для описания и использует только одного разработчика на модуль и звено. Однако, такой случай довольно редок, и в реальности множество разработчиков распределяют нагрузку. Тем не менее, пока ни один из разработчиков не перемещается между звеньями в пределах одного модуля, принцип соблюдается.

В этих примерах Петя занимается исключительно разработкой слоя хранения данных. Это не является обязательным, и в реальности Петя может работать и над другими слоями. Прочие разработчики тоже могут работать над слоем хранением данных. Но обычно слоем хранения данных занимается DBA и только DBA, именно это я и изобразил.
В малых командах назначение одной роли одному разработчику приведет к нехватке ресурсов. В малых командах разработчики должны менять роли с большей частотой, т.к. роль может уйти в спящее состояние, когда завершены необходимые элементы. Хотя смена ролей происходит чаще, она, тем не менее, должна контролироваться. Смена роли должна быть четкой и производиться только, когда нет работы в покидаемой роли.
У сверхмалых команд и одиночек нет другого выбора, кроме как работать в разных ролях в пределах одного модуля. Разработчикам требуется оставаться в пределах слоя и совершать четкие перемещения между ними.
Типичный метод – завершить один модуль и перейти к следующему, когда предыдущий завершен. Допустим следующий подход:

Тем не менее, 2/3 перемещений разработчик будет совершать в горизонтали. Если что-то пошло не так, будет преобладать тенденция сделать шаг назад, создать компромиссное решение и вернуться:

Может оказаться полезным завершать слой за слоем, а не модуль за модулем. Так мы изолируем слои друг от друга. Такой подход, однако, не всегда возможен и требует завершить проектирование заранее. К тому же, некоторым разработчикам может показаться неудобным и сложным скакать между модулями, а не перемещаться последовательно по слоям:

Обратите внимание, что при таком подходе происходит только два горизонтальных шага:
Если вы используете описанный подход, вместо перемещения между слоями, не забудьте перемещаться и между модулями. Следующий рисунок отображает наилучший способ:

Хочу извиниться перед общественностью за то, что разбил статью на две части. Но в последнее время большие тексты перестали приниматься Хабром. Если кто-то подскажет как с этой напастью справиться: буду благодарен.
Распределение ролей
От старых привычек тяжело избавляться, потому многим командам будет тяжело перейти к изолированному подходу. Для внедрения изолированного подхода хорошо подойдет распределение ролей. Кроме того, от распределения ролей будут получены дополнительные выгоды, в т.ч. более быстрая и качественная разработка.
Для того чтобы предотвратить некорректное распределение работы в звеньях, разработчики привязываются к определенному слою. Работа над определенным слоем называется ролью.
Роль слоя хранения данных
- Создание представлений, по требованию разработчика в роле слоя бизнес-логики.
- Создание хранимых процедур для создания, удаления и обновления данных.
- Обработка и оптимизация представлений и SQL в соответствии с планом оптимизации, управления индексами и т.д.
Роль слоя бизнес-логики
- Создание и внедрение внешних интерфейсов, необходимых слою представления, с помощью веб-сервисов или других средств удаленного взаимодействия.
- Определение внешних интерфейсов, используемых слоем представления.
- Формирование требований к представлению данных и хранимым процедурам слоя хранения данных.
- Реализация всех преобразований данных между виртуальным и физическим слоем.
- Создание первичных регрессивных тестов для построения и тестирования слоя бизнес-логики.
Роль слоя представления
- Реализация пользовательского интерфейса
- Подключение пользовательского интерфейса к слою бизнес-логики, используя интерфейсы предоставляемые ролью слоя бизнес-логики.
- Разработка и предложение виртуальных наборов данных или другого контракта передачи данных слою бизнес-логики.
Передача ролей
Хотя разработчики и должны быть привязаны к определенной роли, им нужно иметь возможность мигрировать между различными ролями.
В малых командах передача ролей может позволить лучше распределить ресурсы. Передача ролей в больших командах позволит разработчикам понять систему целиком, осознать влияние их разработок на реализацию соседних звеньев, и обезопасить систему от влияния отдельного разработчика, заболевшего или покинувшего компанию.
Передача ролей, тем не менее, не должна осуществляться как придется и требует контроля. Разработчики должны принимать определенные роли в определенное время. По возможности, разработчик не должен принимать более одной роли в пределах одного модуля. Если в системе есть модуль «Покупатель», каждому разработчику не должно быть назначено более одной роли в пределах модуля «Покупатель». Однако, если разработчик работает над слоем бизнес-логики в модуле «Покупатель», а потом переключается на разработку слоя представления в модуле «Поставщик», это допустимо и позволяет более эффективно распределить ресурсы.
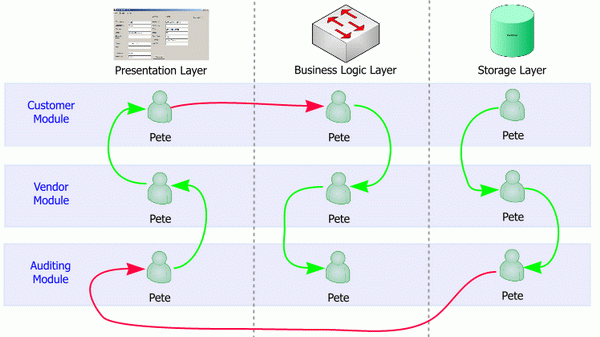
Следующий рисунок демонстрирует пример правильного распределения ролей.
Следующий рисунок показывает неверное распределение ролей. И Джо, и Адам работают в разных ролях в пределах одного модуля. Такие нарушения приводят к тесной связи и потере изолированности между слоями.
Предыдущий пример очень прост для описания и использует только одного разработчика на модуль и звено. Однако, такой случай довольно редок, и в реальности множество разработчиков распределяют нагрузку. Тем не менее, пока ни один из разработчиков не перемещается между звеньями в пределах одного модуля, принцип соблюдается.
В этих примерах Петя занимается исключительно разработкой слоя хранения данных. Это не является обязательным, и в реальности Петя может работать и над другими слоями. Прочие разработчики тоже могут работать над слоем хранением данных. Но обычно слоем хранения данных занимается DBA и только DBA, именно это я и изобразил.
Малые команды
В малых командах назначение одной роли одному разработчику приведет к нехватке ресурсов. В малых командах разработчики должны менять роли с большей частотой, т.к. роль может уйти в спящее состояние, когда завершены необходимые элементы. Хотя смена ролей происходит чаще, она, тем не менее, должна контролироваться. Смена роли должна быть четкой и производиться только, когда нет работы в покидаемой роли.
Сверхмалые команды и одиночки
У сверхмалых команд и одиночек нет другого выбора, кроме как работать в разных ролях в пределах одного модуля. Разработчикам требуется оставаться в пределах слоя и совершать четкие перемещения между ними.
Типичный метод – завершить один модуль и перейти к следующему, когда предыдущий завершен. Допустим следующий подход:
Тем не менее, 2/3 перемещений разработчик будет совершать в горизонтали. Если что-то пошло не так, будет преобладать тенденция сделать шаг назад, создать компромиссное решение и вернуться:
Может оказаться полезным завершать слой за слоем, а не модуль за модулем. Так мы изолируем слои друг от друга. Такой подход, однако, не всегда возможен и требует завершить проектирование заранее. К тому же, некоторым разработчикам может показаться неудобным и сложным скакать между модулями, а не перемещаться последовательно по слоям:
Обратите внимание, что при таком подходе происходит только два горизонтальных шага:
Если вы используете описанный подход, вместо перемещения между слоями, не забудьте перемещаться и между модулями. Следующий рисунок отображает наилучший способ: