“Даже если гарантированное логарифмическое время поиска вас устраивает, стандартные ассоциативные контейнеры не всегда являются лучшим выбором. Как ни странно, стандартные ассоциативные контейнеры по быстродействию нередко уступают банальному контейнеру vector” — C. Мейерс «Эффективное использование STL».
Многих возможно интересует практическая сторона этого совета, насколько же в действительности сортированный vector может быть быстрее ассоциативных контейнеров. Меня тоже интересовал данный вопрос и я решил провести небольшой тест и нарисовать пару графиков чтобы все встало на свои места.
Немного теории, для начала (тем, кто знает что такое vector и map читать не нужно). Map в STL это ассоциативный контейнер для хранения пар ключ-значение. Данные в нем хранятся в сортированном виде, хотя стандарт С++ не оговаривает реализацию, чаще всего map реализуется как красно-черное дерево, в которым каждый элемент хранит указатели на двух потомков. Vector в STL — это просто контейнер элементов, который обеспечивает, что хранимые в нем данные не фрагментированы. Эффективный поиск в нем можно организовать за счет сортировки и дальнейшего двоичного поиска. Как и в первом случае, сложность поиска равна O(ln(n)). Разница в скорости будет различаться за счет лучшего кеширования во втором случае (данные расположены локально, и памяти для хранения нужно меньше).
Для сравнения скорости вставки и поиска была написана тестовая программа, которая производит замеры двух типов — запись случайных значений (random(3)) в контейнеры, при этом замеряя время (с помощью gettimeofday), и поиск случайных значений в контейнере в течение определенного времени (10 с). Таким образом, измеряется время вставки данных в контейнер и количество поисков в контейнере за интервал времени.
Инструментарий:
Аппаратное обеспечение: Двухпроцессорный (Intel Xeon E5420) сервер без swap файла.
Программное обеспечение: Ubuntu server c ядром 2.6.28, gcc 4.3.3.
Компиляция проекта с ключами: -O3 -felide-constructors -fno-exceptions -fno-rtti -funroll-loops -ffast-math -fomit-frame-pointer -march=core2
Каждый тест запускался несколько раз (N=10), при этом фиксировалось минимальное, максимальное и среднее значения некоторого параметра. При проведении тестов производилась минимизация разности получаемых значений (уменьшение нагрузки на сервер, установка cpu affinity).
Данные полученные при вставке элементов в контейнеры
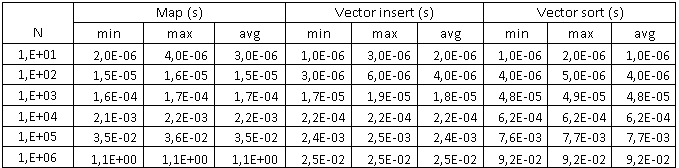

Первый график показывается зависимость времени вставки и сортировки для контейнеров в зависимости от количества элементов. Обе шкалы логарифмические, поэтому для наглядности была построена еще одна кривая, показывающая сумму времени вставки и сортировки для вектора – она показана пунктиром. Горизонтальные черные линии показывают погрешность для каждого эксперимента – максимальное и минимальное значения. Как можно видеть для 1 млн. записей время вставки и сортировки вектора приблизительно в 10 раз меньше (0,11 с) чем для map (1,1 с).
Данные полученные при поиске элементов в контейнерах
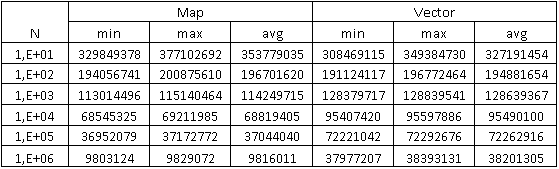

На втором графике показана зависимость количества произведенных поисков за единицу времени (10 секунд) от количества элементов в контейнере. Можно видеть, что скорость поиска в векторе больше, как и предполагалось выше, причем на 1 млн. записей количество поисков в vector приблизительно в 3.9 раза больше чем в map.
Из данных тестов видно, что производительность vector может быть существенно (в 3.9 раза) выше, чем map, при этом однократное заполнение vector и его сортировка тоже производиться быстрее (в 10 раз) чем в map. Таким образом, сортированные вектора стоит использовать в ситуациях редких изменений данных и частых поисков, например для данных, загружаемых во время старта программы и в дальнейшем редко меняющихся. И как всегда, не нужно забывать, что преждевременная оптимизация – зло.
Многих возможно интересует практическая сторона этого совета, насколько же в действительности сортированный vector может быть быстрее ассоциативных контейнеров. Меня тоже интересовал данный вопрос и я решил провести небольшой тест и нарисовать пару графиков чтобы все встало на свои места.
Немного теории, для начала (тем, кто знает что такое vector и map читать не нужно). Map в STL это ассоциативный контейнер для хранения пар ключ-значение. Данные в нем хранятся в сортированном виде, хотя стандарт С++ не оговаривает реализацию, чаще всего map реализуется как красно-черное дерево, в которым каждый элемент хранит указатели на двух потомков. Vector в STL — это просто контейнер элементов, который обеспечивает, что хранимые в нем данные не фрагментированы. Эффективный поиск в нем можно организовать за счет сортировки и дальнейшего двоичного поиска. Как и в первом случае, сложность поиска равна O(ln(n)). Разница в скорости будет различаться за счет лучшего кеширования во втором случае (данные расположены локально, и памяти для хранения нужно меньше).
Для сравнения скорости вставки и поиска была написана тестовая программа, которая производит замеры двух типов — запись случайных значений (random(3)) в контейнеры, при этом замеряя время (с помощью gettimeofday), и поиск случайных значений в контейнере в течение определенного времени (10 с). Таким образом, измеряется время вставки данных в контейнер и количество поисков в контейнере за интервал времени.
Инструментарий:
Аппаратное обеспечение: Двухпроцессорный (Intel Xeon E5420) сервер без swap файла.
Программное обеспечение: Ubuntu server c ядром 2.6.28, gcc 4.3.3.
Компиляция проекта с ключами: -O3 -felide-constructors -fno-exceptions -fno-rtti -funroll-loops -ffast-math -fomit-frame-pointer -march=core2
Каждый тест запускался несколько раз (N=10), при этом фиксировалось минимальное, максимальное и среднее значения некоторого параметра. При проведении тестов производилась минимизация разности получаемых значений (уменьшение нагрузки на сервер, установка cpu affinity).
Данные полученные при вставке элементов в контейнеры
Первый график показывается зависимость времени вставки и сортировки для контейнеров в зависимости от количества элементов. Обе шкалы логарифмические, поэтому для наглядности была построена еще одна кривая, показывающая сумму времени вставки и сортировки для вектора – она показана пунктиром. Горизонтальные черные линии показывают погрешность для каждого эксперимента – максимальное и минимальное значения. Как можно видеть для 1 млн. записей время вставки и сортировки вектора приблизительно в 10 раз меньше (0,11 с) чем для map (1,1 с).
Данные полученные при поиске элементов в контейнерах
На втором графике показана зависимость количества произведенных поисков за единицу времени (10 секунд) от количества элементов в контейнере. Можно видеть, что скорость поиска в векторе больше, как и предполагалось выше, причем на 1 млн. записей количество поисков в vector приблизительно в 3.9 раза больше чем в map.
Из данных тестов видно, что производительность vector может быть существенно (в 3.9 раза) выше, чем map, при этом однократное заполнение vector и его сортировка тоже производиться быстрее (в 10 раз) чем в map. Таким образом, сортированные вектора стоит использовать в ситуациях редких изменений данных и частых поисков, например для данных, загружаемых во время старта программы и в дальнейшем редко меняющихся. И как всегда, не нужно забывать, что преждевременная оптимизация – зло.
