Многие сталкивались с головоломкой про пять разноцветных домов, в каждом из которых живет человек со своими любимыми животным, напитком и сигаретами. Эта загадка приписывается Эйнштейну, хотя прямых подтверждений этому нет. Полный текст этой головоломки есть на википедии.

Ее можно решить на бумаге или в уме, последовательно исключая неподходящие варианты. Однако, ее также можно решить более технично. Один из способов — написать программку на прологе. Но здесь я хочу ее решить используя более простые механизмы — регулярные выражения. А именно, перевести условия загадки на язык регекспов и свести задачу к поиску подходящей строки во всем допустимом наборе строк. Кстати, этот набор строк показан на рисунке.
Сама идея не моя, услышал ее в одной видеолекции. Однако, там ее решали слишком уж изощренно. Я попытался решить ее более просто и прямолинейно.
Для удобства приведу здесь текст загадки:
Вопрос: кто разводит рыбок?
Чтобы решить задачу нужно найти такую последовательность домов, цветов, национальностей, напитков и сигарет, чтобы они удовлетворяли правилам выше
И так, что и где мы будем искать. Для начала нужно каким-то образом формализовать правила. У нас пять домов, цветов, национальностей, напитков, животных и сигарет. Произвольный вариант дома с «жильцами» может выглядеть так:
Но этого недостаточно, так как у нас есть правила, которые учитывают взаимное расположение домов и предметов в них (к примеру, правила: 1, 3, 5...). Учтем это, расположив в строке пять домов последовательно:
Строка выше — один из вариантов расположения предметов. В данном случае, неверный. Если же мы составим все возможные варианты, и поместим это в один текст, получится следующее:
Где n — nation, c — color, a — animal, d — drink, s — cigarettes. И каждая из этих букв может принимать одно из пяти своих значений.
Замечательно. То, что остается сделать — перевести правила на язык регулярных выражений:
И если строка подойдет ко всем правилам, то мы нашли решение! Останется только посмотреть национальность в доме с рыбой. Это и является главной идеей поиска: построить текст и пройтись по нему регулярными выражениями.
Но есть плохая новость. Текст, по которому будет проходить поиск может быть ОЧЕНЬ большим. Если точнее, он будет размером (5!)^5 строк (~24 миллиардов). Его не то чтобы проверить, его будет сложно даже сгенерировать. Но есть и хорошая новость. Мы можем не генерировать весь этот текст, а воспользоваться операцией пересечения регулярных выражений. То есть найдем все общие строки регулярного выражения * (все возможные строки), с теми строками, которые дают регулярные выражения правил задачи. Та строка (а может и строки) что останется после пересечения и будет решением задачи.
К сожалению я не знаю движков, способных пересекать регулярные выражения. По этому придется использовать напрямую конечные автоматы, лежащие в основе любого регекспа.
Конечные автоматы буду строить с помощью библиотечки openfst. Она дает все что мне необходимо для построения автоматов, плюс удобный способ работы из шелла. Чтобы сделать программирование еще более «ненормальным», я вообще не буду программировать :). За исключением простых bash-скриптов кода не будет.
Создадим текстовый файл со списком всех объектов. Это будет наш алфавит.
Построим базовые автоматы, каждый из которых допускает только одно слово из алфавита.
fstcompile — команда пакета openfst, компилирующая текстовое представление автомата в бинарное. Это нужно для того, чтобы потом применять к этому автомату различные операции.
И так, у нас появился список файлов-автоматов. Они очень тривиальны. К примеру, автомат beer будет выглядить так:
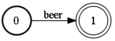
Он эквивалентен регулярному выражению «beer». Пока все довольно просто. Кроме того нам понадобятся еще два базовых автомата — пустое множество, и любая строка, т.е. звездочка *. Строим.
Пустая строка, автомат 'empty':
Звездочка, автомат 'star':
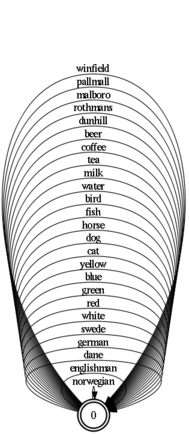
Последний делается простым объединением базовых автоматов и замыканием. В регулярных выражениях это всего лишь (englishman|dane|...|cat|dog|...)*. Этот автомат будет таким:
Правила будет удобней описывать, если создать более комплексные автоматы, такие как национальность, цвет и т.д. Опять, использую несложный скрипт:
Правила 5, 9 и 12 являются составными. Я определяю каждую часть отдельно, а потом делаю объединение. Скрипт concat.sh всего лишь делает конкатинацию автоматов, переданных в аргументах:
Итак, на выходе получим автоматы r1,r2...,r15. Все готово для финального шага.
Где intersect.sh — пересечение автоматов в аргументах.
На этом можно было бы и закончить — посмотреть автомат и узнать у кого рыба. Но я с самого начала не учел одну вещь — в моих правилах каждое из слов может повторятся. К примеру, два человека могут пить одно пиво и заводить одно животное. Это неверно по условиям задачи. Создавать такой фильтр крайне неудобно, используя регулярные языки, т.к. у нас нет способа «запомнить», что такое слово уже было. Но ограничить как-то нужно. По этому подвергаем финальный результат следующему скрипту.
Этот скрипт формирует специальный авотомат для каждого слова из алфавита, и применяет его к результату. Таким образом, отметаются пути с повторяющимися словами. В итоге, финальный результат (а по сути, автомат 'out') выглядит так:

Это частичное изображение автомата (все не влезло). Каждые пять слов определяют дом. Как видно из рисунка, немец разводит рыбок.
Вот такой вот необычный способ решения задачи. Но кроме всего прочего он показывает, что регулярные языки — это довольно мощная штука. Более того, если верить Ульману, любую математическую проблему можно представить как нахождения строки в определенном языке. Что и было показано.
ps и да, мьсе действительно знает толк в извращениях :)
Ее можно решить на бумаге или в уме, последовательно исключая неподходящие варианты. Однако, ее также можно решить более технично. Один из способов — написать программку на прологе. Но здесь я хочу ее решить используя более простые механизмы — регулярные выражения. А именно, перевести условия загадки на язык регекспов и свести задачу к поиску подходящей строки во всем допустимом наборе строк. Кстати, этот набор строк показан на рисунке.
Идея
Сама идея не моя, услышал ее в одной видеолекции. Однако, там ее решали слишком уж изощренно. Я попытался решить ее более просто и прямолинейно.
Для удобства приведу здесь текст загадки:
- Норвежец живёт в первом доме.
- Англичанин живёт в красном доме.
- Зелёный дом находится слева от белого, рядом с ним.
- Датчанин пьёт чай
- Тот, кто курит Marlboro, живёт рядом с тем, кто выращивает кошек.
- Тот, кто живёт в жёлтом доме, курит Dunhill.
- Немец курит Rothmans.
- Тот, кто живёт в центре, пьёт молоко.
- Сосед того, кто курит Marlboro, пьёт воду.
- Тот, кто курит Pall Mall, выращивает птиц.
- Швед выращивает собак.
- Норвежец живёт рядом с синим домом.
- Тот, кто выращивает лошадей, живёт в синем доме.
- Тот, кто курит Winfield, пьет пиво.
- В зелёном доме пьют кофе.
Вопрос: кто разводит рыбок?
Чтобы решить задачу нужно найти такую последовательность домов, цветов, национальностей, напитков и сигарет, чтобы они удовлетворяли правилам выше
И так, что и где мы будем искать. Для начала нужно каким-то образом формализовать правила. У нас пять домов, цветов, национальностей, напитков, животных и сигарет. Произвольный вариант дома с «жильцами» может выглядеть так:
german white cat beer malboro
Но этого недостаточно, так как у нас есть правила, которые учитывают взаимное расположение домов и предметов в них (к примеру, правила: 1, 3, 5...). Учтем это, расположив в строке пять домов последовательно:
german white cat beer malboro englishman red dog water pallmall norwegian green fish milk winfield dane blue bird tea dunhill swede horse yellow coffee rothmans
Строка выше — один из вариантов расположения предметов. В данном случае, неверный. Если же мы составим все возможные варианты, и поместим это в один текст, получится следующее:
n c a d s n c a d s n c a d s n c a d s n c a d s
n c a d s n c a d s n c a d s n c a d s n c a d s
n c a d s n c a d s n c a d s n c a d s n c a d s
...
Где n — nation, c — color, a — animal, d — drink, s — cigarettes. И каждая из этих букв может принимать одно из пяти своих значений.
Замечательно. То, что остается сделать — перевести правила на язык регулярных выражений:
- ^norwegian \w+
- \w+ englishman red \w+
- \w+ dane \w \w tea \w+
- ...
И если строка подойдет ко всем правилам, то мы нашли решение! Останется только посмотреть национальность в доме с рыбой. Это и является главной идеей поиска: построить текст и пройтись по нему регулярными выражениями.
Но есть плохая новость. Текст, по которому будет проходить поиск может быть ОЧЕНЬ большим. Если точнее, он будет размером (5!)^5 строк (~24 миллиардов). Его не то чтобы проверить, его будет сложно даже сгенерировать. Но есть и хорошая новость. Мы можем не генерировать весь этот текст, а воспользоваться операцией пересечения регулярных выражений. То есть найдем все общие строки регулярного выражения * (все возможные строки), с теми строками, которые дают регулярные выражения правил задачи. Та строка (а может и строки) что останется после пересечения и будет решением задачи.
К сожалению я не знаю движков, способных пересекать регулярные выражения. По этому придется использовать напрямую конечные автоматы, лежащие в основе любого регекспа.
Реализация
Конечные автоматы буду строить с помощью библиотечки openfst. Она дает все что мне необходимо для построения автоматов, плюс удобный способ работы из шелла. Чтобы сделать программирование еще более «ненормальным», я вообще не буду программировать :). За исключением простых bash-скриптов кода не будет.
Шаг 1 — Строим базовые автоматы
Создадим текстовый файл со списком всех объектов. Это будет наш алфавит.
norwegian
englishman
dane
german
swede
white
red
...
Построим базовые автоматы, каждый из которых допускает только одно слово из алфавита.
j=1
for i in `cat alph`; do
echo -e "0 1 $j\n1" | fstcompile --acceptor > $i
((j=$j+1))
done
fstcompile — команда пакета openfst, компилирующая текстовое представление автомата в бинарное. Это нужно для того, чтобы потом применять к этому автомату различные операции.
И так, у нас появился список файлов-автоматов. Они очень тривиальны. К примеру, автомат beer будет выглядить так:
Он эквивалентен регулярному выражению «beer». Пока все довольно просто. Кроме того нам понадобятся еще два базовых автомата — пустое множество, и любая строка, т.е. звездочка *. Строим.
Шаг 2 — Строим пустой автомат и звездочку
Пустая строка, автомат 'empty':
echo '0' | fstcompile --acceptor > empty Звездочка, автомат 'star':
cp empty star
for i in `cat alph`; do
fstunion star $i star
done
fstclosure star star
Последний делается простым объединением базовых автоматов и замыканием. В регулярных выражениях это всего лишь (englishman|dane|...|cat|dog|...)*. Этот автомат будет таким:
Шаг 3 — Строим дома
Правила будет удобней описывать, если создать более комплексные автоматы, такие как национальность, цвет и т.д. Опять, использую несложный скрипт:
c="./concat.sh"
$c norwegian star > r1
$c star englishman red star > r2
$c star animal drink cigarette nation star > r3
$c star dane color animal tea star > r4
$c star malboro nation color cat star > r5_0
$c star cat drink cigarette nation color animal drink malboro star > r5_1
$c star yellow animal drink dunhill star > r6
$c star german color animal drink rothmans > r7
$c house house nation color animal milk cigarette house house > r8
$c star malboro nation color animal water star > r9_0
$c star water cigarette nation color animal drink malboro star > r9_1
$c star bird drink pallmall star > r10
$c star swede color dog star > r11
$c star norwegian color animal drink cigarette nation blue star > r12_0
$c star blue animal drink cigarette norwegian star > r12_1
$c star blue horse star > r13
$c star beer winfield star > r14
$c star green animal coffee star > r15
fstunion r5_0 r5_1 > r5
fstunion r9_0 r9_1 > r9
fstunion r12_0 r12_1 > r12
Правила 5, 9 и 12 являются составными. Я определяю каждую часть отдельно, а потом делаю объединение. Скрипт concat.sh всего лишь делает конкатинацию автоматов, переданных в аргументах:
cp empty _c
for i in $*; do
fstconcat _c $i _c
done;
cat _c; rm _c;
Итак, на выходе получим автоматы r1,r2...,r15. Все готово для финального шага.
Шаг последний — Пересечение
./intersect.sh r1 r2 r3 r4 r5 r6 r7 r8 r9 r10 r11 r12 r13 r14 r15 > result
Где intersect.sh — пересечение автоматов в аргументах.
cp cl _c
for i in $*; do
fstintersect _c $i _c
done;
cat _c; rm _c;
На этом можно было бы и закончить — посмотреть автомат и узнать у кого рыба. Но я с самого начала не учел одну вещь — в моих правилах каждое из слов может повторятся. К примеру, два человека могут пить одно пиво и заводить одно животное. Это неверно по условиям задачи. Создавать такой фильтр крайне неудобно, используя регулярные языки, т.к. у нас нет способа «запомнить», что такое слово уже было. Но ограничить как-то нужно. По этому подвергаем финальный результат следующему скрипту.
i="./intersect.sh"
d="fstdifference"
for i in `cat alph`; do
fstdifference cl $i > differ
fstconcat differ $i | fstconcat - differ | fstrmepsilon - | fstdeterminize - | fstminimize - > ${i}_cont
done
cp result out
for i in `ls *_cont`; do
echo $i
fstintersect $i out | fstrmepsilon - | fstdeterminize - | fstminimize - out
done
rm differ
rm *_cont
Этот скрипт формирует специальный авотомат для каждого слова из алфавита, и применяет его к результату. Таким образом, отметаются пути с повторяющимися словами. В итоге, финальный результат (а по сути, автомат 'out') выглядит так:
Это частичное изображение автомата (все не влезло). Каждые пять слов определяют дом. Как видно из рисунка, немец разводит рыбок.
Заключение
Вот такой вот необычный способ решения задачи. Но кроме всего прочего он показывает, что регулярные языки — это довольно мощная штука. Более того, если верить Ульману, любую математическую проблему можно представить как нахождения строки в определенном языке. Что и было показано.
ps и да, мьсе действительно знает толк в извращениях :)
