Привет, Хабрахабр!
В данной статье, я, как и обещал, продолжу описание разработки компилятора для языка Cool, начатое в этой статье.
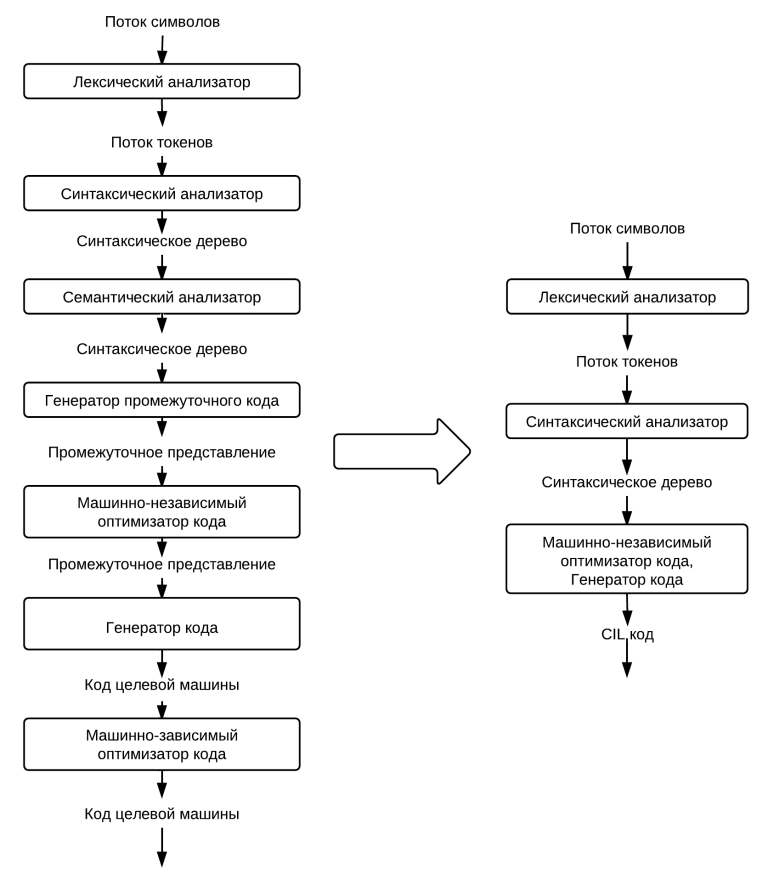
Напомню, что процесс компиляциипо фен-шую включает в себя несколько этапов, которые изображены на рисунке ниже слева. Мой же компилятор содержит только три этапа, которые изображены на этом же рисунке справа.
О лексическом и синтаксическом анализаторах было сказано в первой статье.
Главная задача семантического анализатора — это проверка исходной программы на семантическую согласованность с определением языка. Главным образом это проверка типов, т.е. когда компилятор проверяет, имеет ли каждый оператор операнды соответствующего типа.
Генерация промежуточного кода нужна для генерации промежуточного представления исходного кода, которое должно легко генерироваться и легко транслироваться в целевой машинный язык. В качестве такого представления используется например трехадресный код.
Фаза машинно-независимой оптимизации кода используется для того, чтобы сделать промежуточный код более качесвтенным (более быстрым или, реже, коротким).
Генерация кода — это непосредственно трансляция промежуточного представление в набор команд ассемблера или виртуальной машины.
Фаза машинно-зависимой оптимизации аналогична машинно-независимой оптимизации за исключением того, что здесь используются специальные инструкции целевой машины (например SSE) для оптимизации кода. Понятно, что в нашем случае эти обязанности на себя берет CLR.
Как видно из диаграммы, в одном этапе у меня совмещено целых три этапа из схемы слева. Это объясняется как невозможностью генерации промежуточного кода с помощью инструмента System.Reflection.Emit (так как генерируется последовательность инструкций CIL, которую нельзя изменить), так и непродуманностью архитектуры в целом.
Ух, прям и не знаю с чего начать!
Опишу этапы моего кодогенератора, которые будут рассмотрены:
Известно, что исходный код на языке Cool представляет собой набор классов. Естественно, при этом должна существовать точка входа, а то ничего и выполняться не будет.
Так вот, точкой входом является функция main в классе Main. И класс и функцию нужно прописывать вручную. Но подробнее об этом чуть позже.
В System.Reflection.Emit есть специальные классы AssemblyBuilder и ModuleBuilder, которые используются для построения динамической сборки и генерации CIL кода.
Для объявления описания любого класса используется метод
В котором className — имя класса, attr — его аттрибуты и parent — родитель (если имеется).
TypeBuilder — динамический тип, который будет потом использоваться при генерации кода (например для оператора new).
Итак, на данном этапе в синтаксическом дереве, полученным из парсера, обходятся узлы с типом «class», как это показано на рисунке ниже и определяются все классы, которые есть в исходном коде, с помощью упомянутого выше метода.
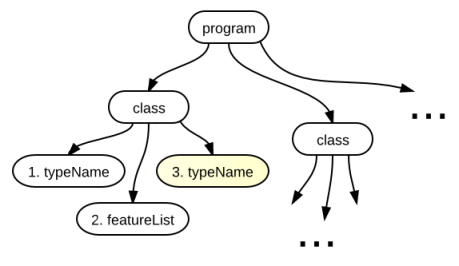
Желтым цветом отображаются необязательные символы языка (Здесь это имя родительского класса. Если родителя нет, то класс наследуется от Object).
Хочу отметить, что на этом этапе создаются только определения классов, без их описания функций и полей внутри них. Если же функции и поля описывать сразу, то можно столкнуться с ошибкой, что класс не определен, хотя он просто позже описан.
Также хочу сказать, что правильнее было бы перед определением классов сортировать их описания в исходном коде в правильном порядке (например идет описание класса B, который наследуется от A, а потом описание класса A). Но это у меня, к сожалению, не реализовано, поэтому все классы нужно описывать в таком порядке, в котором они используются.
Итак, на данном этапе получен словарь
в котором ключем является имя класса, а значением — его builder.
В заключении хочу сказать, что на после генерации всего кода, динамические типы нужно финализировать с помощью метода CreateType (это производится в функции FinalAllClasses).
После определения классов, в каждом классе нужно определить его функции и методы для дальнейшего использования. Это делается с помощью методов
и
соответственно.
В конце данного этапа заполняется двухмерные словари
Ключем словаря первого измерения является имя класса, второго — имя функции или поля. Значением же являются описатели функции или поля соответственно (Об этих классах будет сказано чуть позже).
Проблема сортировки описаний функций и полей в исходном коде здесь нет, как это есть при определении классов. Потому что на этапе определения классов, информация о других классах используется для определения наследственности, и она используется прямо в функции DefineType. Но, поскольку для определения функции не нужна информация о других функциях (здесь не происходит генерации кода), то и ссылок на другие функции не нужны. А значит генерировать определения функций и полей можно в любом порядке.
А вот и дошли до самого интересного. Здесь происходит непосредственно рекурсивный обход тел функций и конструкторов всех классов.
Итак, из предыдущего этапа был получен словарь всех описателей методов (MethodBuilder) для всех классов.
Чтобы добавить инструкцию CIL в метода, нужно сначала получить специальный объект ILGenerator с помощью
Существует множество форм у метода Emit:
OpCode — это инструкция виртуальной .NET машины. Хороший список инструкций с описаниями перечислен здесь.
А вторым аргументом (он не всегда есть) как раз идет «билдер» или описатель класса или метода, который был получен на предыдущих двух этапах.
Текущая фукнция и текущий класс — соответственно функция и класс, в котором в данный момент происходит генерация кода (при обходе синтаксического дерева).
Для начала я объясню какие классы в своем кодогенераторе я ввел для описания аргументов функций, локальных переменных, временных локальных переменных и полей классов. Базовым классом является ObjectDef, который содержит абстрактные методы Load(), Remove() для загрузки, и освобождения соответствующего объекта.
Как вы уже заметили, в языке Cool каждый результат является выражением. И внутри каждого конструктора и каждой функции тоже всего навсего одно expr. Это является самым главным моментом моего кодогенератора и для обработки данной конструкции была введена функция EmitExpression(ITree expressionNode). Код приведен ниже (я сократил его, заменив некоторые куски на закоммеченные троеточия):
Как видим, в зависимости от типа узла дерева (expressionNode), из длинного case вызывается функция, отвечающая за генерацию инструкций данного оператора.
Для возврата результата в генерируемой функции, используется простая инструкция OpCodes.Ret после генерации кода выражения (Если функция ничего не возвращает, например Main, нужно перед Ret добавить OpCodes.Pop, чтобы стек не переполнялся).
Для того, чтобы определить точку входа, используется метод SetEntryPoint(MethodInfo entryMethod), который определен в AssemblyBuilder. Также методу точки входа нужно задать аттрибут STAThreadAttribute, который указывает на то, что приложение выполняется в одном потоке. Код для определения функций и точки входа находится у меня в DefineFunction.
Вопрос: как сгенерировать код для конструкций типа таких:
math: Math ← new Math; (присваивание полю какого-то выражения, здесь new Math).
Ответ: Прежде всего нужно понимать, что компилятор C# и, соответственно наш компилятор, не генерирует никакие вычисления налету — это невозможно. Т.е. я хочу сказать, что выражение справа будет вычислено в конструкторе по-умолчанию.
А после того, как код выражения (здесь new Math) будет сгенерирован, в тело этого конструктора добавляется инструкция OpCodes.Stfld или OpCodes.Stsfld для нестатических и статических полей соответственно.
CIL является стековым языком, а значит все операции производятся с использованием стека. Например вызов функции для подсчета числа Фибоначчи из класса Math кодируется следующим образом:
Здесь сначала в стек загружается дескриптор экземпляра math, затем передаваемый аргумент типа int. После этого происходит вызов функции fibonacci с помощью инструкции OpCodes.callvirt (Обычная инструкция OpCodes.call используется при вызове внутренней функции класса, тогда дескриптор класса передавать не нужно). Последняя инструкция stloc.0 сохраняет возвращаемое значение в локальной переменной под номером 0.
Ну и в соответствии с вышесказанным хочу отметить, что первым аргументом у любой функции идет указатель на экземпляр класса, из которого она вызвана (this), даже если аргументов никаких нет в явной форме.
Более подробное описание CIL можно посмотреть например на википедии
, а я же лучше опишу как кодировать некоторые синтаксических конструкций с помощью Reflection.Emit.
Данные операции кодируются просто — сначала в стек помещаются
операнды, а затем код операции: для арифметических операций это OpCodes.Add, OpCodes.Sub, OpCodes.Mul, OpCodes.Div, а для операций сравнения — OpCodes.Ceq, OpCodes.Clt, OpCodes.Cgt.
Хочу отметить, что в CIL нет инструкции для сравнений «меньше либо равно» или «больше либо равно», поэтому для генерации таких сравнений используется три инструкции, вместо одной (здесь "<=" эквивалентно «not >»):
OpCodes.Ceq производит сравнение двух элементов в стеке и возвращает 1 в случае, если они равны, а 0 — если не равны.
По сравнению с кодированием арифметических операций, в кодировании этой инструкции есть сложность, которая заключается в том, что нужно как-то обозначить метки услового и безусловного переходов. Однако делается это легко. С помощью метода DefineLabel в ILGenerator создаются метки, которые затем нужно использовать для маркировки кода с помощью метода MarkLabel. Эти метки затем используются при кодировании инструкций условных и безусловных переходов. Соответственно OpCodes.Brfalse — условный переход, происходящий при равенстве значения вершины стека нулю. А OpCodes.Br — безусловный переход. Для наглядности я привел код:
Данная конструкция во многом напоминает If. Только не стоит забывать, что внутри тела данного конструкции нужно всегда делать Pop, т.к. внутреннее выражение вычисляется, а его результат не используется. (В Cool данный оператор всегда возвращает void).
Оператор @ по сути соответствует выражению (a as B).methodName в C# коде, а в операторе Case используется динамическая проверка типов и она соответствует выражению a is B в C#.
Данные операторы у меня, к сожалению, не были реализованы.
Однако могу сказать, что приведение к определенному типу реализуется с помощью инструкции castclass <class> (Приведение к типу и вызов метода сразу реализуется с помощью constrained. <thisType> [prefix])
А проверка динамических типов реализуется с помощью инструкции isinst <class>.
Если тип узла дерева соответствует типу Id, то производятся следующие действия (в функции EmitIdValue):
В этом разделе я описал инструкции CIL и генерацию кода для синтаксических конструкций, которые кажутся наиболее интересными сложными. По всем остальным инструкциям CIL вы можете обратиться к вики-странице, ссылка на которую размещена в конце топика. А генерацию кода вы можете посмотреть более подробно в исходниках.
Ошибки в компиляторе бывают разные:черные, белые, красные лексические, синтаксические, семантические и общего вида.
Для всех них был создан абстрактный класс CompilerError, содержащий номер ошибки, позицию в коде (строку и колонку), тип ошибки и ее описание.
Лексические и синтаксические ошибки контролировать невозможно (по крайней мере в этом проекте я не стал в ANTLR разбираться с восстановлением после ошибок на уровне лексера и парсера). Здесь просто ловятся исключения и создаются соответствующие для них экземпляры ошибок. Это все можно посмотреть в файле CoolCompier.cs
А вот проверка на семантические ошибки, главным образом проверка типов, реализуется во всех функциях «эмитах». Проверка на соответствие типов реализуется банальным способом. Тем не менее данный подход позволяет достичь распознавания нескольких семантических ошибок за один проход. Вот пример: арифметическая операция, если даже ошибка была обнаружена, то обход синтаксического дерева продолжается:
Ну а к ошибкам общего рода я отнес ошибки типа «Файл занят другим процессом», «Не найдена точка входа» и др. О них рассказывать не особо интересно.
В качестве компонента для работы с кодом я, как уже говорил, использовал AvalonEdit под WPF.
Для подсветки синтаксиса используется специальный файл с расширением .xshd, в котором описаны стили шрифтов для различных слов и правил.
Например, комментарии обозначаются так:
Ключевые слова вот так:
Также существуют правила, которые нужны для того, чтобы определить какая последовательность символов является числом или строкой и как их нужно подсвечивать:
Все остальные правила подсветки можно посмотеть в файле CoolHighlighting.xshd.
Сворачивание и разворачивание блоков возможно в этом редакторе и реализовано в CoolFoldingStrategy.cs. Код не мой, так что от его комментариев воздержусь. Скажу лишь что благодаря ему все, что находится между фигурными скобками, можно свернуть или развернуть. Может кому-то это покажется не очень правильным, поскольку у циклов такой возможности быть не должно.
Также с помощью этого компонента можно сделать автодополнение, но я не стал этим заниматься, потому что для этого нужно было делать в самом начале другую архитектуру, которая позволяла бы генерировать семантическое дерево независимо от генерации кода.
Напоследок по части интерфейса опишу, как связать найденные ошибки со строками кода. В показанном ниже коде происходит скролл и перевод каретки в место, где возникла определенная ошибка:
tbEditor — экземпляр компонента-редактора;
compilerError — ошибка (описание представлено в предыдущем разделе);
Ну и конечно же этот раздел будет не полным без скрина самого компилятора:
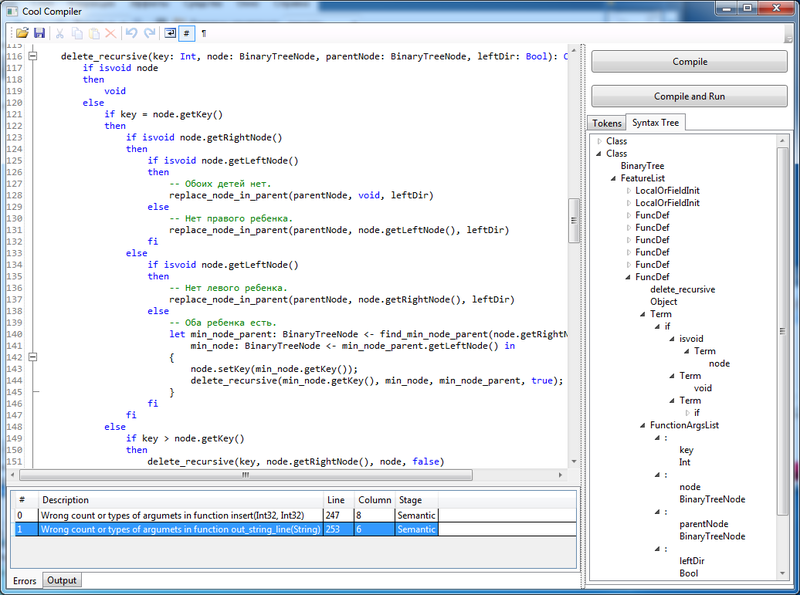
Редактор кода находится слева вверху, лог и список ошибок — слева внизу. Справа же находятся кнопки для компиляции кода (также можно просто нажимать F5 для компиляции и запуска, а F6 просто для компиляции).
Для наглядности в программе выводится список токенов и синтаксическое дерево (справа). При двойном клике на токене или синтаксической конструкции, происходит скорол и перевод каретки на нужное место.
Если бы я начал писать компилятор для языка Cool заново с теми знаниями, которые у меня сейчас есть, и с достаточной мотивацией, то я наверное выделил бы еще две стадии компиляции — построение семантического дерева и генерация трех- или четырехадресного промежуточного кода.
Семантическое дерево, как я уже и говорил, позволит реализовать автоподстановку и проверку семантических ошибок в реальном времени до генерации кода.
Трехадресный промежуточный код позволит применить техники оптимизации, которые невозможно применить при текущем подходе. Например свертку команд такого рода и другие оптимизации:
Я решил выложитьсборник быдлокода все лабы, которые у меня были по курсу «Конструирование Компиляторов» в 2011 году в МГТУ им. Н.Э.Баумана (11 вариант). Думаю, они кому-нибудь пригодятся.
Описание всех лабораторных:
Хочу заметить, что в некоторых моих лабах используется чудесная, но закрытая и платная библиотека для отрисовки графов Microsoft.GLEE. Судя по этой статье, в этой библиотеке используются какие-то умные алгоритмы и эвристики, чтобы отрисовываемый граф выглядел так, как будто его нарисовал человек и занимал наименьшую площадь при наибольших размерах узлов. (Странно, что на хабре почти никто не упоминал о ней).
Преимуществом является также и то, что пользоваться данной библиотекой просто. Например добавление ребра между узлами выполняется с помощью функции
Т.е. узлы для добавления связи между ними, создавать предварительно не надо.
Если же нужно просто добавить одиночный узел, то используется функция
В качестве результата функции возвращается экземпляр объекта Edge, у которого можно менять аттрибуты (цвет текста, цвет узла, отступ и др.)
Что бы вы не подумали, но я не являюсь приверженцем Microsoft :)
Для создания и редактирования всех схем я использовал удобный онлайн сервис lucidchart.com.
Я согласен с автором данного тописка с тем, что по изучаемого предмета не нужно читать много книг, а достаточно одной, но хорошей.
Я рекомендую «Компиляторы. Принципы, технологии и инструментарий, 2008, Альфред В. Ахо, Моника С. Лам, Рави Сети, Джеффри Д. Ульман».
Также выкладываю ссылку на List of CIL instructions, который часто использовался мной.
Всё!
Введение
В данной статье, я, как и обещал, продолжу описание разработки компилятора для языка Cool, начатое в этой статье.
Напомню, что процесс компиляции
О лексическом и синтаксическом анализаторах было сказано в первой статье.
Главная задача семантического анализатора — это проверка исходной программы на семантическую согласованность с определением языка. Главным образом это проверка типов, т.е. когда компилятор проверяет, имеет ли каждый оператор операнды соответствующего типа.
Генерация промежуточного кода нужна для генерации промежуточного представления исходного кода, которое должно легко генерироваться и легко транслироваться в целевой машинный язык. В качестве такого представления используется например трехадресный код.
Фаза машинно-независимой оптимизации кода используется для того, чтобы сделать промежуточный код более качесвтенным (более быстрым или, реже, коротким).
Генерация кода — это непосредственно трансляция промежуточного представление в набор команд ассемблера или виртуальной машины.
Фаза машинно-зависимой оптимизации аналогична машинно-независимой оптимизации за исключением того, что здесь используются специальные инструкции целевой машины (например SSE) для оптимизации кода. Понятно, что в нашем случае эти обязанности на себя берет CLR.
Как видно из диаграммы, в одном этапе у меня совмещено целых три этапа из схемы слева. Это объясняется как невозможностью генерации промежуточного кода с помощью инструмента System.Reflection.Emit (так как генерируется последовательность инструкций CIL, которую нельзя изменить), так и непродуманностью архитектуры в целом.
Архитектура
Ух, прям и не знаю с чего начать!
Опишу этапы моего кодогенератора, которые будут рассмотрены:
- Определение классов
- Определение функций и полей
- Генерация кода конструкторов и функций
Определение классов
Известно, что исходный код на языке Cool представляет собой набор классов. Естественно, при этом должна существовать точка входа, а то ничего и выполняться не будет.
Так вот, точкой входом является функция main в классе Main. И класс и функцию нужно прописывать вручную. Но подробнее об этом чуть позже.
В System.Reflection.Emit есть специальные классы AssemblyBuilder и ModuleBuilder, которые используются для построения динамической сборки и генерации CIL кода.
Для объявления описания любого класса используется метод
TypeBuilder ModuleBuilder.DefineType(string className, TypeAttributes attr, Type parent)
В котором className — имя класса, attr — его аттрибуты и parent — родитель (если имеется).
TypeBuilder — динамический тип, который будет потом использоваться при генерации кода (например для оператора new).
Итак, на данном этапе в синтаксическом дереве, полученным из парсера, обходятся узлы с типом «class», как это показано на рисунке ниже и определяются все классы, которые есть в исходном коде, с помощью упомянутого выше метода.
Желтым цветом отображаются необязательные символы языка (Здесь это имя родительского класса. Если родителя нет, то класс наследуется от Object).
Хочу отметить, что на этом этапе создаются только определения классов, без их описания функций и полей внутри них. Если же функции и поля описывать сразу, то можно столкнуться с ошибкой, что класс не определен, хотя он просто позже описан.
Также хочу сказать, что правильнее было бы перед определением классов сортировать их описания в исходном коде в правильном порядке (например идет описание класса B, который наследуется от A, а потом описание класса A). Но это у меня, к сожалению, не реализовано, поэтому все классы нужно описывать в таком порядке, в котором они используются.
Итак, на данном этапе получен словарь
Dictionary<string, TypeBuilder> ClassBuilders_;
в котором ключем является имя класса, а значением — его builder.
В заключении хочу сказать, что на после генерации всего кода, динамические типы нужно финализировать с помощью метода CreateType (это производится в функции FinalAllClasses).
Определение функций и полей
После определения классов, в каждом классе нужно определить его функции и методы для дальнейшего использования. Это делается с помощью методов
public FieldBuilder DefineField(string fieldName, Type type, FieldAttributes attributes)
и
public MethodBuilder DefineMethod(string name, MethodAttributes attributes, Type returnType, Type[] parameterTypes);
соответственно.
В конце данного этапа заполняется двухмерные словари
protected Dictionary<string, Dictionary<string, FieldObjectDef>> Fields_;
protected Dictionary<string, Dictionary<string, MethodDef>> Functions_;
Ключем словаря первого измерения является имя класса, второго — имя функции или поля. Значением же являются описатели функции или поля соответственно (Об этих классах будет сказано чуть позже).
Проблема сортировки описаний функций и полей в исходном коде здесь нет, как это есть при определении классов. Потому что на этапе определения классов, информация о других классах используется для определения наследственности, и она используется прямо в функции DefineType. Но, поскольку для определения функции не нужна информация о других функциях (здесь не происходит генерации кода), то и ссылок на другие функции не нужны. А значит генерировать определения функций и полей можно в любом порядке.
Генерация кода конструкторов и функций
А вот и дошли до самого интересного. Здесь происходит непосредственно рекурсивный обход тел функций и конструкторов всех классов.
Итак, из предыдущего этапа был получен словарь всех описателей методов (MethodBuilder) для всех классов.
Чтобы добавить инструкцию CIL в метода, нужно сначала получить специальный объект ILGenerator с помощью
var ilGenerator = methodBuilder.GetILGenerator(), а затем уже воспользоваться методом Emit у этого генератора.Существует множество форм у метода Emit:
void Emit(OpCode opcode);
void Emit(OpCode opcode, int arg);
void Emit(OpCode opcode, double arg);
void Emit(OpCode opcode, ConstructorInfo con);
void Emit(OpCode opcode, LocalBuilder local);
void Emit(OpCode opcode, FieldInfo field);
void Emit(OpCode opcode, MethodInfo meth);
void Emit(OpCode opcode, Type cls);
OpCode — это инструкция виртуальной .NET машины. Хороший список инструкций с описаниями перечислен здесь.
А вторым аргументом (он не всегда есть) как раз идет «билдер» или описатель класса или метода, который был получен на предыдущих двух этапах.
Текущая фукнция и текущий класс — соответственно функция и класс, в котором в данный момент происходит генерация кода (при обходе синтаксического дерева).
Для начала я объясню какие классы в своем кодогенераторе я ввел для описания аргументов функций, локальных переменных, временных локальных переменных и полей классов. Базовым классом является ObjectDef, который содержит абстрактные методы Load(), Remove() для загрузки, и освобождения соответствующего объекта.
- FieldObjectDef — используется для описания поля любого класса (в Cool поле — это feature). При генерации кода для функций и конструкторов текущего класса, используется массив из описаний полей, который был описан выше.
- LocalObjectDef — используется для описания всех локальных переменных в теле текущей функции или конструктора (В Cool локальные переменные объявляются с помощью оператора let).
- ValueObjectDef — разновидность локальной переменной для хранения данных, передающихся по значениям. В Cool такие классы — это Int, String, Bool.
- ArgObjectDef — аргумент текущей функции. Содержит номер, название и тип аргумента.
Как вы уже заметили, в языке Cool каждый результат является выражением. И внутри каждого конструктора и каждой функции тоже всего навсего одно expr. Это является самым главным моментом моего кодогенератора и для обработки данной конструкции была введена функция EmitExpression(ITree expressionNode). Код приведен ниже (я сократил его, заменив некоторые куски на закоммеченные троеточия):
ObjectDef result;
switch (expressionNode.Type)
{
case CoolGrammarLexer.ASSIGN:
result = EmitAssignOperation(expressionNode);
break;
// Другие типы...
case CoolGrammarLexer.EQUAL:
result = EmitEqualOperation(expressionNode);
break;
case CoolGrammarLexer.PLUS:
case CoolGrammarLexer.MINUS:
case CoolGrammarLexer.MULT:
case CoolGrammarLexer.DIV:
result = EmitArithmeticOperation(expressionNode);
break;
//...
case CoolGrammarLexer.Term:
if (expressionNode.ChildCount == 1)
result = EmitExpression(expressionNode.GetChild(0));
else
result = EmitExplicitInvoke(expressionNode);
break;
case CoolGrammarLexer.ImplicitInvoke:
result = EmitInplicitInvoke(expressionNode);
break;
case CoolGrammarLexer.IF:
result = EmitIfBranch(expressionNode);
break;
case CoolGrammarLexer.Exprs:
for (int i = 0; i < expressionNode.ChildCount - 1; i++)
{
var objectDef = EmitExpression(expressionNode.GetChild(i));
objectDef.Remove();
}
result = EmitExpression(expressionNode.GetChild(expressionNode.ChildCount - 1));
break;
//...
case CoolGrammarLexer.INTEGER:
result = EmitInteger(expressionNode);
break;
}
return result;
Как видим, в зависимости от типа узла дерева (expressionNode), из длинного case вызывается функция, отвечающая за генерацию инструкций данного оператора.
Для возврата результата в генерируемой функции, используется простая инструкция OpCodes.Ret после генерации кода выражения (Если функция ничего не возвращает, например Main, нужно перед Ret добавить OpCodes.Pop, чтобы стек не переполнялся).
Для того, чтобы определить точку входа, используется метод SetEntryPoint(MethodInfo entryMethod), который определен в AssemblyBuilder. Также методу точки входа нужно задать аттрибут STAThreadAttribute, который указывает на то, что приложение выполняется в одном потоке. Код для определения функций и точки входа находится у меня в DefineFunction.
Вопрос: как сгенерировать код для конструкций типа таких:
math: Math ← new Math; (присваивание полю какого-то выражения, здесь new Math).
Ответ: Прежде всего нужно понимать, что компилятор C# и, соответственно наш компилятор, не генерирует никакие вычисления налету — это невозможно. Т.е. я хочу сказать, что выражение справа будет вычислено в конструкторе по-умолчанию.
А после того, как код выражения (здесь new Math) будет сгенерирован, в тело этого конструктора добавляется инструкция OpCodes.Stfld или OpCodes.Stsfld для нестатических и статических полей соответственно.
Описание некоторых CIL инструкций и конструкций
CIL является стековым языком, а значит все операции производятся с использованием стека. Например вызов функции для подсчета числа Фибоначчи из класса Math кодируется следующим образом:
ldsfld class Math Main::math ldsfld int32 Main::i callvirt instance int32 Math::fibonacci(int32) stloc.0
Здесь сначала в стек загружается дескриптор экземпляра math, затем передаваемый аргумент типа int. После этого происходит вызов функции fibonacci с помощью инструкции OpCodes.callvirt (Обычная инструкция OpCodes.call используется при вызове внутренней функции класса, тогда дескриптор класса передавать не нужно). Последняя инструкция stloc.0 сохраняет возвращаемое значение в локальной переменной под номером 0.
Ну и в соответствии с вышесказанным хочу отметить, что первым аргументом у любой функции идет указатель на экземпляр класса, из которого она вызвана (this), даже если аргументов никаких нет в явной форме.
Более подробное описание CIL можно посмотреть например на википедии
, а я же лучше опишу как кодировать некоторые синтаксических конструкций с помощью Reflection.Emit.
Арифметически операции и операции сравнения
Данные операции кодируются просто — сначала в стек помещаются
операнды, а затем код операции: для арифметических операций это OpCodes.Add, OpCodes.Sub, OpCodes.Mul, OpCodes.Div, а для операций сравнения — OpCodes.Ceq, OpCodes.Clt, OpCodes.Cgt.
Хочу отметить, что в CIL нет инструкции для сравнений «меньше либо равно» или «больше либо равно», поэтому для генерации таких сравнений используется три инструкции, вместо одной (здесь "<=" эквивалентно «not >»):
OpCodes.Cgt
OpCodes.Ldc_I4_0
OpCodes.Ceq
OpCodes.Ceq производит сравнение двух элементов в стеке и возвращает 1 в случае, если они равны, а 0 — если не равны.
Конструкция If
По сравнению с кодированием арифметических операций, в кодировании этой инструкции есть сложность, которая заключается в том, что нужно как-то обозначить метки услового и безусловного переходов. Однако делается это легко. С помощью метода DefineLabel в ILGenerator создаются метки, которые затем нужно использовать для маркировки кода с помощью метода MarkLabel. Эти метки затем используются при кодировании инструкций условных и безусловных переходов. Соответственно OpCodes.Brfalse — условный переход, происходящий при равенстве значения вершины стека нулю. А OpCodes.Br — безусловный переход. Для наглядности я привел код:
protected ObjectDef EmitIfBranch(ITree expressionNode)
{
var checkObjectDef = EmitExpression(expressionNode.GetChild(0));
checkObjectDef.Load();
checkObjectDef.Remove();
var exitLabel = CurrentILGenerator_.DefineLabel();
var elseLabel = CurrentILGenerator_.DefineLabel();
CurrentILGenerator_.Emit(OpCodes.Brfalse, elseLabel);
var ifObjectDef = EmitExpression(expressionNode.GetChild(1));
ifObjectDef.Load();
ifObjectDef.Remove();
CurrentILGenerator_.Emit(OpCodes.Br, exitLabel);
CurrentILGenerator_.MarkLabel(elseLabel);
var elseObjectDef = EmitExpression(expressionNode.GetChild(2));
elseObjectDef.Load();
elseObjectDef.Remove();
CurrentILGenerator_.MarkLabel(exitLabel);
return LocalObjectDef.AllocateLocal(GetMostNearestAncestor(ifObjectDef.Type, elseObjectDef.Type));
}
Конструкция While
Данная конструкция во многом напоминает If. Только не стоит забывать, что внутри тела данного конструкции нужно всегда делать Pop, т.к. внутреннее выражение вычисляется, а его результат не используется. (В Cool данный оператор всегда возвращает void).
Операторы '@' и 'Case'
Оператор @ по сути соответствует выражению (a as B).methodName в C# коде, а в операторе Case используется динамическая проверка типов и она соответствует выражению a is B в C#.
Данные операторы у меня, к сожалению, не были реализованы.
Однако могу сказать, что приведение к определенному типу реализуется с помощью инструкции castclass <class> (Приведение к типу и вызов метода сразу реализуется с помощью constrained. <thisType> [prefix])
А проверка динамических типов реализуется с помощью инструкции isinst <class>.
Обработка Id токенов
Если тип узла дерева соответствует типу Id, то производятся следующие действия (в функции EmitIdValue):
- Поиск идентификатора в локальных переменных, если не найден, то
- Поиск идентификатора в аргументах функции, если не найден, то
- Поиск идентификатора в полях текущего класса, если не найден, то
- Сгенерировать ошибку, что Id не определен
В этом разделе я описал инструкции CIL и генерацию кода для синтаксических конструкций, которые кажутся наиболее интересными сложными. По всем остальным инструкциям CIL вы можете обратиться к вики-странице, ссылка на которую размещена в конце топика. А генерацию кода вы можете посмотреть более подробно в исходниках.
Обработка ошибок
Ошибки в компиляторе бывают разные:
Для всех них был создан абстрактный класс CompilerError, содержащий номер ошибки, позицию в коде (строку и колонку), тип ошибки и ее описание.
Лексические и синтаксические ошибки контролировать невозможно (по крайней мере в этом проекте я не стал в ANTLR разбираться с восстановлением после ошибок на уровне лексера и парсера). Здесь просто ловятся исключения и создаются соответствующие для них экземпляры ошибок. Это все можно посмотреть в файле CoolCompier.cs
А вот проверка на семантические ошибки, главным образом проверка типов, реализуется во всех функциях «эмитах». Проверка на соответствие типов реализуется банальным способом. Тем не менее данный подход позволяет достичь распознавания нескольких семантических ошибок за один проход. Вот пример: арифметическая операция, если даже ошибка была обнаружена, то обход синтаксического дерева продолжается:
protected ObjectDef EmitArithmeticOperation(ITree expressionNode)
{
var returnObject1 = EmitExpression(expressionNode.GetChild(0));
var returnObject2 = EmitExpression(expressionNode.GetChild(1));
if (returnObject1.Type != IntegerType || returnObject1.Type != returnObject2.Type)
CompilerErrors.Add(new ArithmeticOperatorError(
returnObject1.Type, returnObject2.Type,
CompilerErrors.Count, expressionNode.Line,
expressionNode.GetChild(1).CharPositionInLine,
expressionNode.GetChild(0).CharPositionInLine));
...
}
Ну а к ошибкам общего рода я отнес ошибки типа «Файл занят другим процессом», «Не найдена точка входа» и др. О них рассказывать не особо интересно.
Интерфейс
Подсветка синтаксиса
В качестве компонента для работы с кодом я, как уже говорил, использовал AvalonEdit под WPF.
Для подсветки синтаксиса используется специальный файл с расширением .xshd, в котором описаны стили шрифтов для различных слов и правил.
Например, комментарии обозначаются так:
<Span color="Comment" begin="--" /> <Span color="Comment" multiline="true" begin="\(\*" end="\*\)" />
Ключевые слова вот так:
<Color name="Keywords" foreground="Blue" /> ... <Keywords color="Keywords"> <Word>classWord> <Word>elseWord> <Word>falseWord> ... Keywords>
Также существуют правила, которые нужны для того, чтобы определить какая последовательность символов является числом или строкой и как их нужно подсвечивать:
<Rule foreground="DarkBlue"> \b0[xX][0-9a-fA-F]+ # hex number |\b ( \d+(\.[0-9]+)? #number with optional floating point | \.[0-9]+ #or just starting with floating point ) ([eE][+-]?[0-9]+)? # optional exponent Rule>
Все остальные правила подсветки можно посмотеть в файле CoolHighlighting.xshd.
Фолдинг и автодополнение
Сворачивание и разворачивание блоков возможно в этом редакторе и реализовано в CoolFoldingStrategy.cs. Код не мой, так что от его комментариев воздержусь. Скажу лишь что благодаря ему все, что находится между фигурными скобками, можно свернуть или развернуть. Может кому-то это покажется не очень правильным, поскольку у циклов такой возможности быть не должно.
Также с помощью этого компонента можно сделать автодополнение, но я не стал этим заниматься, потому что для этого нужно было делать в самом начале другую архитектуру, которая позволяла бы генерировать семантическое дерево независимо от генерации кода.
Напоследок по части интерфейса опишу, как связать найденные ошибки со строками кода. В показанном ниже коде происходит скролл и перевод каретки в место, где возникла определенная ошибка:
tbEditor.ScrollTo((int)compilerError.Line, (int)compilerError.ColumnStart);
int offset = tbEditor.Document.GetOffset((int)compilerError.Line, (int)compilerError.ColumnStart);
tbEditor.Select(offset, 0);
tbEditor.Focus();
tbEditor — экземпляр компонента-редактора;
compilerError — ошибка (описание представлено в предыдущем разделе);
Ну и конечно же этот раздел будет не полным без скрина самого компилятора:
Редактор кода находится слева вверху, лог и список ошибок — слева внизу. Справа же находятся кнопки для компиляции кода (также можно просто нажимать F5 для компиляции и запуска, а F6 просто для компиляции).
Для наглядности в программе выводится список токенов и синтаксическое дерево (справа). При двойном клике на токене или синтаксической конструкции, происходит скорол и перевод каретки на нужное место.
Дальнейшее улучшение архитектуры
Если бы я начал писать компилятор для языка Cool заново с теми знаниями, которые у меня сейчас есть, и с достаточной мотивацией, то я наверное выделил бы еще две стадии компиляции — построение семантического дерева и генерация трех- или четырехадресного промежуточного кода.
Семантическое дерево, как я уже и говорил, позволит реализовать автоподстановку и проверку семантических ошибок в реальном времени до генерации кода.
Трехадресный промежуточный код позволит применить техники оптимизации, которые невозможно применить при текущем подходе. Например свертку команд такого рода и другие оптимизации:
stloc.0
ldloc.0Описание исходников (Бонусы)
Я решил выложить
Описание всех лабораторных:
- Задача 1. Расщепление грамматики. В данной лабе реализуется алгоритм расщепления грамматики. Подробное описание и последовательность шагов можно прочитать в учебнике «Ахо А., Ульман Дж. Теория синтаксического анализа, перевода и компиляции» во втором томе на странице 102. Могу только добавить, что там используются алгоритмы для удаления бесполезных (RemoveUselessSymbols) и недостижимых (RemoveUnreachableSymbols) символов из грамматики.
Помню, что я в то время еще игрался с LINQ. Так что код в этих функциях получился далеко не эффективным и красивым, зато довольно коротким. :)
- Задача 2. Распознавание цепочек регулярного языка. Здесь реализуются следующие подзадачи:
- Решение стандартной системы с регулярными коэффициентами.
Пояснение: нужно построить из левосторонней грамматики регулярное выражение. Т.е. «решить» систему с регулярными коэффициентами (СРК). Коэффициентами являются терминалы, а неизвестные — нетерминалы.
Например для такой грамматики:
Σ = {0, 1}
N = {S, A, B}
P = {S → 0∙A|1∙S|λ, A → 0∙B|1∙A, B → 0∙S|1∙B}
S = S
Получается следующее выражения (там есть небольшая ошибка, но не суть):
S = 1*+1*∙0∙1*∙0∙1*∙0∙1*+1*∙0∙1*∙0∙(0∙1*∙0∙1*∙0)*∙0∙1*
A = 1*∙0∙1*∙0∙1*+1*∙0∙(0∙1*∙0∙1*∙0)*∙0∙1*
B = 1*∙0∙1*+(0∙1*∙0∙1*∙0)*∙0∙1*
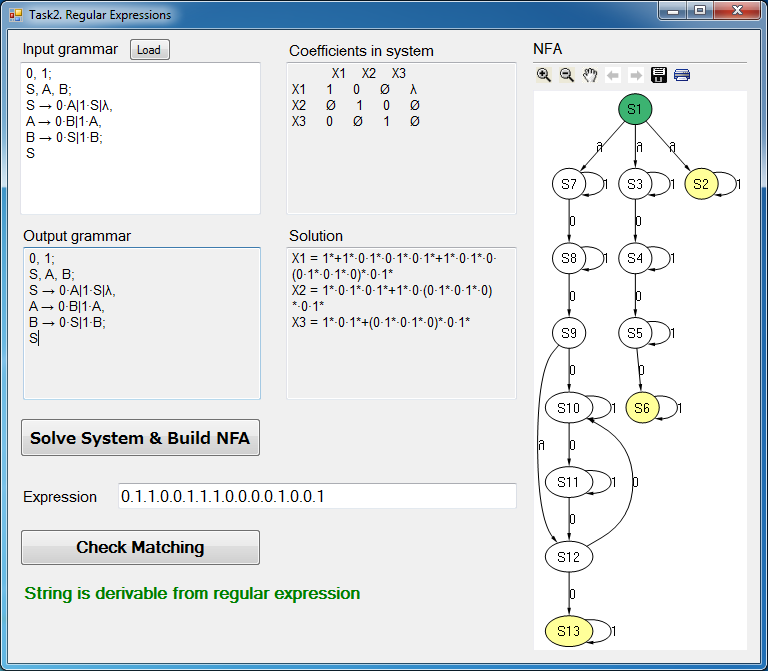
При работе над этой лабой меня поразило, что путем перегрузки привычных в алгебре операций '+', '*', '/', на соответствующие операции 'или', 'конкатенация' и 'итерация' в контексте регулярных выражений, можно решить СРК методом Гаусса также, как мы решаем и обычную СЛАУ! Единственно, что все-таки в целях оптимизации было кое-что изменено.
Однако перегрузка этих операций тоже нетривиальная задача, ведь это не числа, а строки и правила здесь другие: при конкатенации нужно «склеивать» строки, при операции 'или' нужно просто оставлять их в таком же виде, нулем является пустое множество (Ø), единицей — лямбда (λ). Соответственно оптимизировать эти строки в случае умножения или сложения на 0 или 1 тоже надо, а то они быстро «разбухнут».
- По регулярному выражению, являющемся решением стандартной системой уравнений с регулярными коэффициентами, построить НКА (Недетерминированный Конечный Автомат).
- Детерминировано смоделировать НКА. Если кратко — то это модифицированный поиск в глубину
- Решение стандартной системы с регулярными коэффициентами.
- Задача 3. Алгоритм Кока-Янгера-Касами
Здесь требовалось реализовать синтаксический разбор с помощью алгоритма Кока-Янгера-Касами
Данный алгоритм требует, чтобы грамматика была задана в Нормальной форме Хомского, что конечно доставляет определенные неудобства. Также неудобство доставляет и отсутствие лексера, так все токены должны быть разделены пробелом, чтобы парсер распознал их.
Результатом в данной лабе является таблица синтаксического разбора и собственно определение принадлежности введенной строки заданной грамматике.
- Задача 4. Метод рекурсивного спуска
Здесь требовалось реализовать метод рекурсивного спуска. Примерно по такому же принципу генерируют код все LL(*) кодогенераторы (например ANTLR). Только здесь все реализовано вручную. Для наглядности здесь также строится дерево разбора.
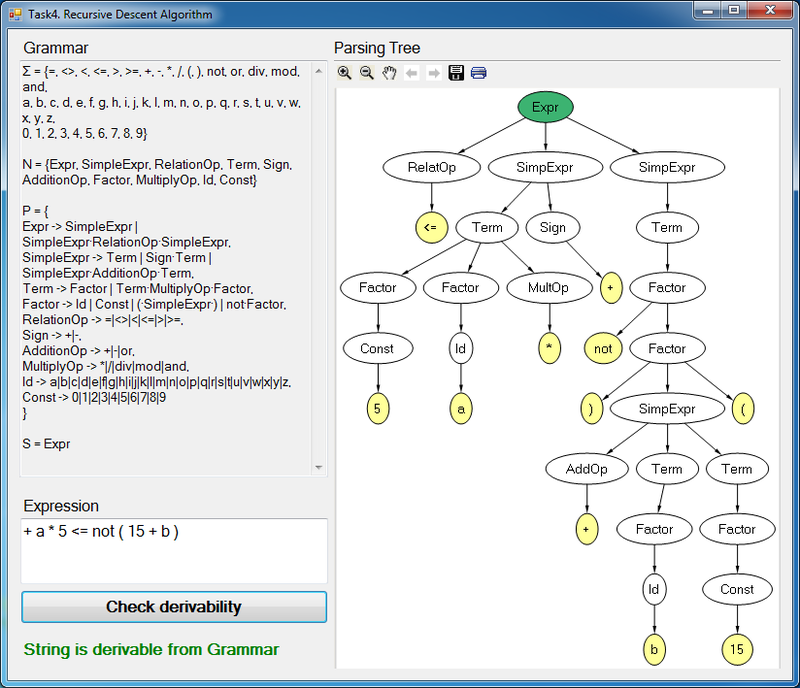
- Задачи 5-8. Компилятор для языка Cool
Ну собственно венцом и предметом гордости является мойлексер-парсер-кодогенератор-ошибкочекатор-синтаксисоподсвечивателькомпилятор для языка Cool под платформу .NET, о котором я уже все расписал подробным образом.
Единственно, хочу сказать, что мной были написаны две программы на языке Cool, которые, о чудо, работают:
- Example1.cool — Демонстрация корректности исполнения программы (приоритеты операторов, правильная работа рекурсивных функций, таких как факториал и вычисление числа Фибоначчи).
- BinaryTree.cool — Более сложная программа, которая даже имеет практическое применение — работа с бинарным деревом поиска (добавление, удаление узлов, отображение сгенерированного дерева). В качестве примера здесь генерируется двоичное дерево поиска как в примере в русской википедии
- Рубежные контроли, которые были сделаны на скорую руку (подробные описания находятся в соответствующих файлах .pdf):
- Evaluating Simple C Expressions — вычисление Си-подобного результата выражения и переменных с инкрементами и декрементами.
- iFlop — интерпретатор некой многопоточной системы iFlop со специфическим языком.
Хочу заметить, что в некоторых моих лабах используется чудесная, но закрытая и платная библиотека для отрисовки графов Microsoft.GLEE. Судя по этой статье, в этой библиотеке используются какие-то умные алгоритмы и эвристики, чтобы отрисовываемый граф выглядел так, как будто его нарисовал человек и занимал наименьшую площадь при наибольших размерах узлов. (Странно, что на хабре почти никто не упоминал о ней).
Преимуществом является также и то, что пользоваться данной библиотекой просто. Например добавление ребра между узлами выполняется с помощью функции
Edge AddEdge(string source, string target), в которой source — название одного узла, target — название другого узла.Т.е. узлы для добавления связи между ними, создавать предварительно не надо.
Если же нужно просто добавить одиночный узел, то используется функция
Edge AddNode(string nodeId)В качестве результата функции возвращается экземпляр объекта Edge, у которого можно менять аттрибуты (цвет текста, цвет узла, отступ и др.)
Что бы вы не подумали, но я не являюсь приверженцем Microsoft :)
Для создания и редактирования всех схем я использовал удобный онлайн сервис lucidchart.com.
Литература
Я согласен с автором данного тописка с тем, что по изучаемого предмета не нужно читать много книг, а достаточно одной, но хорошей.
Я рекомендую «Компиляторы. Принципы, технологии и инструментарий, 2008, Альфред В. Ахо, Моника С. Лам, Рави Сети, Джеффри Д. Ульман».
Также выкладываю ссылку на List of CIL instructions, который часто использовался мной.
Проект на GitHub
Всё!

{kind=link}