Введение
Повышение качества обслуживания клиентов неизменно приводит к более высокой их лояльности. Причем не только в смысле приверженности определенному онлайн-продукту, но и в смысле терпимости к его недостаткам, при условии, конечно, что достоинства – скорость, юзабилити, функциональность и т.д. – их перевешивают.
Измерить качество обслуживания напрямую мы, конечно, не можем, однако даже такую эфемерную величину в принципе можно свести к набору количественных характеристик, так или иначе косвенно отражающихся на качестве. Прибыль, число клиентов, процент конвертированных лидов (leads – зарегистрировавшиеся или заинтересованные пользователи) и т.д. – все это вполне объективные показатели. Кроме того, эти величины могут быть включены в систему контроля эффективности работы в качестве KPI – ключевых показателей эффективности.
С нашей, инженерной точки зрения подобными характеристиками являются время ответа и HTTP-код ответа апстрима. Действительно, дизайн, функциональность продукта, маркетинговые усилия и прозвон клиентов находятся вне зоны нашей компетенции. Следовательно, нужно сфокусироваться на том, что находится в нашей власти – ускорение работы инфраструктуры приложения и обработки клиентских запросов.
Анализ отклика и HTTP-кодов удобно проводить на основе некоторой собранной статистической базы, и здесь мы плавно подходим к теме статьи.
Что и зачем измеряем
Как уже было сказано выше, нашей задачей является оценка качества работы приложения, а не фактическое измерение скорости его работы (профайлинг) или оптимизация. Для этого существуют специализированные инструменты. Основными показателями качества работы приложения являются время ответа апстрима и код HTTP-ответа, поскольку именно апстрим выполняет основную функцию генерации контента продукта и обработку пользовательских запросов.
С другой стороны, анализ скорости передачи сформированной апстримом страницы по каналам на компьютер клиента нас в данном контексте не интересует, т.к. ничего не говорит нам о качестве самого продукта. Клиентская сеть может имеет различную архитектуру и быстродействие, и низкая пропускная способность того или иного клиента может всего лишь означать, что он работает, например, через 3G-модем.
В этом же смысле малоприменимым на данном этапе является анализ скорости рендеринга страниц в браузере. Доля апстрима в процессе отображения той или иной страницы пользователю с момента получения запроса от него и до окончания загрузки всех компонентов страницы и рендеринга ее браузером составляет около 5-10%. Получается, что, приняв во внимание данные факторы, мы сведем весь результат измерения к значительно и трудно вычисляемой погрешности. Впрочем, это тема совершенно отдельного разговора.
Таким образом, статистику следует собирать по двум базовым параметрам:
- Время отклика апстрима на запрос.
Анализируя статистику по этому параметру, мы не только сможем оценить общее быстродействие апстрима, но и выявить те или иные паттерны (закономерности) в изменении нагрузки, варьировании среднего времени ответа в различное время суток и т.д. - Код HTTP-ответа
Понятно, что выявить и устранить все ошибки не удастся – кривые внешние ссылки еще никто не отменял. Однако стремиться к уменьшению числа ошибок, несомненно, стоит. Сохраняться и анализироваться должны как «средняя температура по больнице» (коды 2xx, 4xx), так и точный расклад по всем HTTP-кодам. Преобладание, например, кодов 5xx в статистике укажет на нашу ошибку (а значит, на снижение качества приложения), которую нужно исправить.
Особенности измерения
При анализе времени отклика неплохо было бы учитывать характер запроса, обрабатывая и анализируя статистику по различным видам запросов отдельно. Действительно, тяжелый SQL-запрос может значительно увеличить время формирования страницы, тогда как мелкие AJAX запросы, выполняемые пользователями, лишь незначительно «загружают» апстрим. В этой связи наиболее целесообразно было бы выделить категории запросов с различным предельным временем отклика, например:
- AJAX запрос – 200мс
- Генерация страницы – 1с
- Ошибка – 5с
- Timeout или отсутствие ответа – 7с
К сожалению, далеко не всегда можно явным образом разделить те или иные сценарии работы. Например, один и тот же скрипт может генерировать разный контент, в зависимости от условий работы, что приведет к неверному истолкованию результатов измерений.
В этом случае можно сформулировать общие правила оценки времени отклика на основе процентно-временных диапазонов. Например:
- 90% < 200мс
- 95% < 500мс
- 99% < 1с
- 100% < 2с
Таким образом, выход статистических значений за границу одного из диапазонов будет служить индикатором снижения качества работы приложения.
Как оценить результат измерения
Собрать статистику (о чем ниже) и получить результаты измерений времени отклика – это лишь полдела. Без последующего анализа и оценки результата (хорошо, плохо), все это не имеет никакого смысла. К счастью, здесь нам на помощь приходят промышленные стандарты на время отклика системы:
- ESD/MITRE (ESD-TR-86-278, «Guidelines for Designing User Interface Software», 1986, www.dfki.de/~jameson/hcida/papers/smith-mosier.pdf)
- TAFIM («Technical Architecture Framework for Information Management», 1996, том 8, «DoD Human Computer Interface Style Guide», www.everyspec.com/DoD/DOD-General/DISA_TAFIM_VOL8_7545)
- MIL-STD 1472 (ревизия G от 2012 г., www.everyspec.com/MIL-STD/MIL-STD-1400-1499/MIL-STD-1472F_208)
В соответствии с этим стандартами, максимальное время ожидания пользователя не должно превышать 10-15 секунд, среднее время обработки запроса должно быть не более 2-5 секунд, а время отклика системы – 0.2-0.5 секунды (стандарты писались из расчета возможностей техники тех времен, которая на сегодняшний день хорошо увеличила свою производительность).
Другой источник – «Designing and Engineering Time: The Psychology of Time Perception in Software» (2008, www.amazon.com/Designing-Engineering-Time-Psychology-Perception/dp/0321509188) – рассматривает подход, основанный на времени ожидания пользователя:
- Мгновенную реакцию (0.1 — 0.2 с) система должна показывать при нажатии кнопок, вызове меню, взаимодействии с другими элементами интерфейса.
- Незамедлительная реакция (0.5 — 1 с) должна следовать в ответ на простой запрос пользователя.
- Непрерывающаяся реакция (2 — 5 с) – это время, в течение которого пользователь сохраняет внимание на задаче, иначе говоря, время обратной связи.
- Вынуждающая реакция (7 — 10 с) – когда после 7 секунд пользователь переключается на другую задачу или уходит со страницы.
Таким образом, сопоставляя статистические данные с указанными величинами, мы можем осуществить преобразование количественной характеристики (время отклика апстрима) в качественную – соответствие реакции системы стандартам и субъективному восприятию пользователя.
Перейдем к непосредственному измерению.
Чем измерять
Рассмотрим решение задачи сбора статистики для популярного сервера nginx.
При использовании nginx в качестве front end, все необходимая нам информация доступна в логах. Классический способ сбора статистики через анализ логов подразумевает подробный разбор (парсинг) содержимого логов за выделенный промежуток времени. Данный путь имеет ряд недостатков:
- анализ логов сам по себе требует существенных затрат времени и ресурсов;
- анализаторы логов часто недешевы, а написание собственного решения требует дополнительного привлечения разработчиков;
- экспорт результатов парсинга для дальнейшего анализа затруднен.
Второй подход – использование дополнительных модулей. Рассмотрим ряд вариантов.
- nginx-statsd
Модуль для nginx, собирающий статистику и перенаправляющий ее демону StatsD по протоколу UDP. Такой подход, во-первых, требует отдельного сервера, а во-вторых, приводит к росту служебного трафика. Кроме того, StatsD завязан на Graphite, а интеграция с ним других систем мониторинга затруднена. - pinba
Модуль для nginx, собирающий статистические данные в момент завершения выполнения запроса и передающий их по протоколу UDP на отдельный сервер сбора статистики. Фактически, недостатки такого решения обусловлены самим принципом его работы: необходимость отдельного сервера, «лишний» UDP-трафик. Кроме того, модуль фактически фиксирует время от момента получения запроса до его завершения (shutdown), т.е. измеряет время выполнения запроса, а не время ответа апстрима, которое нам нужно. - nginx-sla
Модуль nginx-sla реализует сбор статистики апстрима без привлечения дополнительного сервера. Данные статистики формируются по запросу к nginx в обычном текстовом формате, следовательно, ни отдельный сервер, ни UDP не нужны.
Следует отметить, что описанные недостатки приведенных выше способов сбора статистики, конечно, никоим образом не ограничивают полезности данных подходов в целом. Однако именно для нашей задачи наиболее простым и гибким инструментом оказывается nginx-sla.
Преимущества nginx-sla
Как уже отмечалось, применение модуля nginx-sla не требует выделенного сервера для сбора и анализа статистики. Статистика собирается непосредственным анализом логов nginx и записывается в виде простого текста. Очевидно, что в контексте дальнейшего анализа, как стандартными инструментами, так и сторонними средствами (например, zabbix), такое представление статистики апстрима намного более выгодно.
Пример статистики, собранной nginx-sla, при конфигурации по умолчанию:
main.all.http = 1024
main.all.http_200 = 914
...
main.all.http_xxx = 2048
main.all.http_2xx = 914
...
main.all.time.avg = 125
main.all.time.avg.mov = 124
main.all.300 = 233
main.all.300.agg = 233
main.all.500 = 33
main.all.500.agg = 266
main.all.2000 = 40
main.all.2000.agg = 306
main.all.inf = 0
main.all.inf.agg = 306
main.all.25% = 124
main.all.75% = 126
main.all.90% = 126
main.all.99% = 130
Как видно, данные отображают статистику всех обработанных HTTP ответов с различными статусами. Например, значение main.all.http_200 (main.all.http_404, main.all.http_500) обозначает число обработанных ответов с соответствующим статусом.
А поле main.all.http_2xx содержит количество всех ответов апстрима, имеющих статус «Success».
Статистика по времени отклика собрана в переменных main.all.300 (main.all.200, main.all.500, main.all.2000). Например, число запросов, обработанных апстримом за время от 300 миллисекунд до 500 миллисекунд, равно 33. А аггрегатированное число запросов, обработанных за 500 мс и менее, равно 266.
Помимо явной статистики времени ответа апстрима, nginx-sla приводит информацию по перцентилям. В частности время, за которое апстрим отвечает на 90% запросов, составляет в данном примере 126 миллисекунд.
Перцентильное представление статистики, а также значения среднего (main.all.time.avg) и скользящего среднего (main.all.time.avg.mov) времени ответа позволяют проанализировать поведение апстрима при различных сценариях нагрузки. Например:
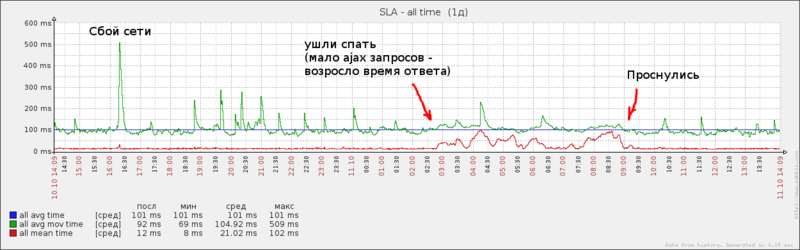

Заключение и выводы
Теперь настало время вернуться к началу статьи и вспомнить, что нашей целью являлось улучшение качества продукта. Какую информацию мы можем почерпнуть из собранной статистики? Анализируя статистику, полученную за определенный период, закономерно задаться вопросом: лучше стало или хуже? Ведь нашей целью, как мы ранее указали, является преобразование количественных характеристик в качественные.
Здесь уместно вспомнить два простых закона:
- Закон Вебера – Фехнера, утверждающий, что интенсивность ощущения пропорциональна логарифму интенсивности раздражителя. Или иначе: различие в ощущениях появляется, если раздражители отличаются на некую долю своей величины, а не на абсолютное значение.
- Абсолютный порог восприятия времени человеком составляет примерно 15 мс.
Для промежутков времени длительностью до 30 с, порог восприятия разницы составляет примерно 20%. Иными словами, регрессию или ускорение в пределах 20% от актуального значения пользователи не замечают. Разницу свыше 20% пользователь может и обнаружить, но если эта разница окажется меньше минимального порога восприятия времени, то и она пройдет незамеченной.
Выводы
- Качество работы приложения можно свести к набору количественных характеристик. В нашем случае, качество работы апстрима можно свести к времени отклика и HTTP-ответам с различными статусами.
- Анализ указанных характеристик удобно проводить модулями для nginx.
- В качестве рабочего инструмента используем nginx-sla как наиболее гибкий и нетребовательный модуль в сравнении с аналогами.
- nginx-sla позволяет сгруппировать статистическую информацию и, тем самым, преобразовать количественные данные в величины, пригодные для качественного анализа (среднее значение, плавающее среднее, квантили).
- Собранная статистика анализируется на предмет превышения предельных значений, заданных стандартом, и сопоставляется с порогом восприятия времени человеком. Делается вывод о необходимости дальнейших действий.
P.S. Модуль достаточное время без нареканий работает в продакшен среде. Отзывы, баги, pull-request'ы приветствуются.
