Введение
Добрый день!
В своем первом посте я хотел бы поделитьcя опытом использования такой утилиты как logman, с помощью которой можно собирать информацию о потреблении ресурсов (и не только) приложением под Windows.
В один из дней на работе была поставлена задача снятия метрик производительности для одного приложения под Windows. Главным условием было использовать по минимуму какие-либо сторонние утилиты, и так как опыта в подобных вещах у меня к тому времени не было, немного покопавшись, выбор пал на logman. Особой точности не требовалось и надо было лишь понять характер потребления ресурсов приложением, для чего logman с первого взгляда вполне подходил.
Итак, перейдем непосредственно к сути поста.
Что же такое logman?
Многие из вас скорее всего в работе или для домашних нужд использовали нативную Windows утилиту Performance monitor (perfmon). Так вот logman — это грубо говоря command line представление perfmon'а. Он позволяет создавать, запускать, останавливать счетчики производителности, писать результат во внешние файлы и много чего еще. Мне был необходим только базовый функционал, который я и опишу ниже.
Основные операции
Небольшое замечание: для выполнения нижеследующих операций необходимо обладать правами администратора, иначе может вылететь такая ошибка.
Ошибка:
Отказано в доступе.
Используется ограниченный токен, используйте расширенный.
Просмотр созданных и запущенных счетчиков
Посмотреть список сборщиков данных можно командой
logmanВ результате чего будет получен примерно такой вывод:
Группа сборщиков данных Тип Состояние
-------------------------------------------------------------------------------
cpu Счетчик Остановлено
Команда выполнена успешно.
Создание счетчика производительности
Для создания счетчика я использовал следующую команду (с полным списком опций можно ознакомиться в официальной документации.):
logman create counter "counter_name" -f csv -si "interval" --v -o "output_file" -c counter
- counter_name — имя счетчика. Может быть любым, например «explorer_cpu»
- -f — формат файла с результатами измерений
- --v — эта опция подавляет вывод версии в выходном файле
- -si — интервал. с которым будут записываться измерения
- -o — файл с результатами измерений
- -c — идентификатор счетчика производительности
Остановимся подробнее на последней опции. Чтобы понять, что вписывать в поле «counter», можно проследовать в perfmon, создать группу сборщиков данных и выбрать «Создать -> Сборщик данных». Далее выбрать «Добавить счетчик» и в появившемся окне найти интересующий нас тип счетчика.
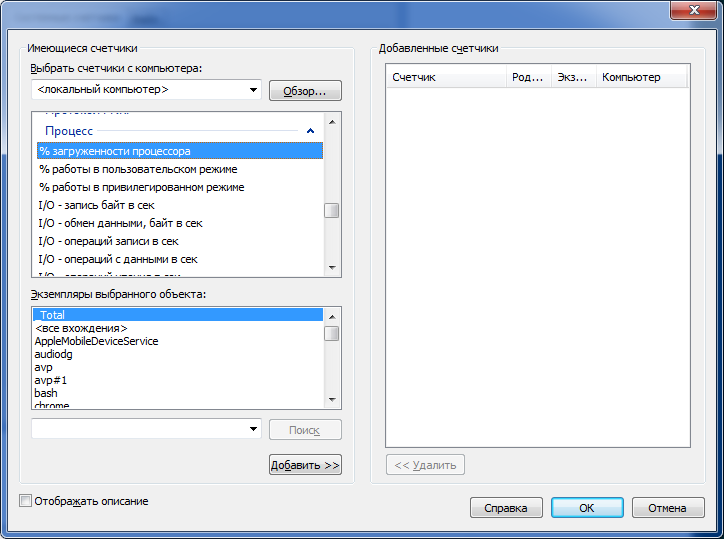
Меня интересовало потребление cpu и памяти конкретным процессом, поэтому я использовал для измерений следующие счетчики (в расчете CPU мне помог следующий пост):
- "\Processor(_Total)\% User time" — процент CPU в пользовательском режиме
- "\Process(application_name)\% Processor time" — доля CPU приложения от пользовательского режима
- "\Process(application_name)\Working Set" — использование оперативной памяти процессом
Процент потребления CPU процессом можно расчитать как ("\Processor(_Total)\% User time" * "\Process(application_name)\% Processor time") / (количество_процессоров * 100)
Счетчики можно записывать через пробел, тогда в выходном файле значения будут каждый в своем столбце.
В итоге приведу пример готовой команды для создания счетчика:
logman create counter "explorer-cpu.usage" -f csv -si 1 --v -o "d:\logman-test\raw\explorer-cpu.usage.csv" -c "\Processor(_Total)\% User time" "\Process(explorer)\% Processor time"
Запуск и остановка счетчика
Выполняются соответствующими командами:
logman start "counter_name"
logman stop "counter_name"
Удаление счетчика
Удалить счетчик можно следующей командой (он обязательно должен быть перед этим остановлен):
logman delete "counter_name"
Обертка на Python
Прежде чем перейти к коду, хотелось бы рассказать о небольшой (хотя для меня она стала довольно существенной) проблеме, которая возникла в ходе сбора метрик.
Так как собирать данные предполагалось за довольно небольшой промежуток времени (5-15 секунд), то стало понятно, что интервал сбора в 1 с (задаваемый через опцию "-si") слишком большой. Поискав на просторах интернета и в оф. документации, мне не удалось найти способ, которым этот интервал можно было уменьшить, а количество получаемых точек на графике очень хотелось увеличить. Немного поразмыслив, я решил пойти от противного — если нельзя уменьшить интервал, то можно увеличить количетство счетчиков. Таким образом, запуская подряд несколько сборщиков с интервалом в 100-500 миллисекунд, можно получить за одну секунду сколько нужно данных.
Процесс сбора данных должен был быть интегрирован в существующий автоматический тест и в конечном была написана небольшая вспомогательная обертка для выполения всех вышеуказанных действий.
Ниже представлен исходный код модуля, собирающий данные по CPU и оперативной памяти для указанного приложения с требуемой точностью.
pylogman.py
import os
import logging
import random
import time
import subprocess
import glob
import multiprocessing
CPU_USER_COUNTER = '"\Processor(_Total)\% User time"'
CPU_APP_COUNTER = '"\Process({app})\% Processor time"'
MEMORY_COUNTER = '"\Process({app})\Working Set"'
APP_PLACEHOLDER = '{app}'
class PerflogManager(object):
def __init__(self, app_name, precision, results_dir, max_mem=1, interval=1):
"""
Args:
app_name: name of the application without "exe" extention
precision: amount of
results_dir: output folder
max_mem: this value is used to calculate % from total avaliable memory for further plotting
interval: interval which will be used as "-si" logman option value
"""
self._app_name = app_name
self._precision = precision
self._counters = { 'cpu.usage': '{cpu_user} {cpu_app}'.format(cpu_user=CPU_USER_COUNTER,
cpu_app=CPU_APP_COUNTER).replace(APP_PLACEHOLDER, app_name),
'mem.usage': MEMORY_COUNTER.replace(APP_PLACEHOLDER, app_name) }
self._results_dir = os.path.normpath(results_dir)
self._raw_dir = os.path.join(self._results_dir, 'raw')
self._final_dir = os.path.join(self._results_dir, 'csv')
self._interval = interval
self._max_mem = max_mem
self._collectors = []
if not os.path.exists(self._results_dir):
os.makedirs(self._results_dir)
os.makedirs(self._raw_dir)
os.makedirs(self._final_dir)
logging.info('Directory "{path}" for logman results has been created.'.format(path=self._results_dir))
logging.info('Performance logman manager has been created for "{}" application.'.format(self._app_name))
def init_collectors(self):
"""
Creates collectors by "logman create" command
"""
logging.info('Creating collectors set...')
for lang in self._counters:
for idx in range(self._precision):
collector = '{app}-{collector}-{id}'.format(app=self._app_name,
collector=lang,
id=idx)
output = os.path.join(self._raw_dir, collector + '.csv')
self.__create(collector, self._counters[lang], output)
self._collectors.append(collector)
def start_all(self):
"""
Starts all the collectors from self._collectors list
"""
for collector in self._collectors:
self.__start(collector)
time.sleep(random.uniform(0.1, 0.9))
def stop_all(self):
"""
Stops and deletes all initiated collectors from self._collectors list
"""
for collector in self._collectors:
self.__stop(collector)
self.__delete(collector)
def cleanup(self):
"""
Cleans raw_dir directory which contains unprocessed csv file from logman
"""
logging.info('Cleaning results directory from unnecessary files.')
for collector in self._collectors:
csv = os.path.join(self._raw_dir, '{}.csv'.format(collector))
if os.path.isfile(csv):
os.remove(csv)
def process_csv(self):
"""
Composes and formats data from all counters for further plotting
"""
for lang in self._counters:
final_output = os.path.join(self._final_dir, '{}.csv'.format(lang))
self.__compose_csv(final_output, lang)
self.__format_data(final_output)
def __compose_csv(self, output, counter):
"""
Concatenates gathered csv data to one file
"""
logging.info('Composing file "{}".'.format(output))
try:
with open(output, 'a') as outfile:
for csv in glob.glob(os.path.join(self._raw_dir, '*{}*'.format(counter))):
with open(csv, 'r') as file:
outfile.writelines(file.readlines()[1:]) # Get rid of a file header with service info
logging.info('File {} successfully created.'.format(output))
except (FileNotFoundError, IOError) as e:
logging.error('Failed to compose file {file}: {exception}'.format(file=output,
exception=e))
def __format_data(self, file):
"""
Sorts data after self.__compose_csv function and calculates % of CPU and Memory
"""
try:
with open(file, 'r') as csv:
raw_data = csv.readlines()
with open(file, 'w') as csv:
sorted_data = [line.replace('"', '').replace(',', ';')
for line in sorted(raw_data)
if '" "' not in line]
csv_data = []
if 'cpu' in file:
for line in sorted_data:
time, cpu_user, cpu_app = line.split(';')
cpu = (float(cpu_user) * float(cpu_app)) / (multiprocessing.cpu_count() * 100)
csv_data.append('{};{:.2f}\n'.format(time, cpu))
if 'mem' in file:
for line in sorted_data:
time, total_memory = line.split(';')
mem = float(total_memory) / (self._max_mem * 10000)
csv_data.append('{};{:.2f}\n'.format(time, mem))
csv.writelines(csv_data)
except (FileNotFoundError, IOError) as e:
logging.error('Failed to process file "{file}": {exception}'.format(file=file,
exception=e))
def __logman(self, cmd):
"""
Default wrapper for logman commands
Args:
cmd: windows command to be executed
"""
try:
logging.debug('Running {}'.format(cmd))
subprocess.check_call(cmd)
except (subprocess.CalledProcessError, OSError) as e:
logging.error('Failed to execute command "{}": {}.'.format(cmd, e))
def __create(self, name, counter, output):
"""
Creates logman counter
Args:
name: uniq name of a collector
counter: type of the counter (can be taken from perfmon)
output: csv file for results
"""
logging.info('Creating collector "{}"'.format(name))
cmd = 'logman create counter "{name}" -f csv -si {interval} ' \
'--v -o "{output}" -c {counter}'.format(name=name,
interval=str(self._interval),
output=output,
counter=counter)
self.__logman(cmd)
def __start(self, name):
"""
Starts logman collector
Args:
name: uniq name of a collector
"""
logging.info('Starting collector "{}".'.format(name))
cmd = 'logman start {}'.format(name)
self.__logman(cmd)
def __stop(self, name):
"""
Stops logman collector
Args:
name: uniq name of a collector
"""
logging.info('Stopping collector "{}".'.format(name))
cmd = 'logman stop {}'.format(name)
self.__logman(cmd)
def __delete(self, name):
"""
Deletes logman collector
Args:
name: uniq name of a collector
"""
logging.info('Deleting collector "{}".'.format(name))
cmd = 'logman delete {}'.format(name)
self.__logman(cmd)
if __name__ == '__main__':
logging.basicConfig(level=logging.DEBUG)
app = 'skype'
start_time = time.strftime('%Y%m%d-%H%M%S', time.gmtime())
logman = PerflogManager(app, 3, 'd:/logman-test/')
logman.init_collectors()
logman.start_all()
time.sleep(20)
logman.stop_all()
logman.process_csv()
Заключение
В заключении хотелось бы сказать, что logman — довольно полезная утилита, если небходимо с минимальными затратами автоматизировать сбор метрик производительности под Windows. В сжатые сроки мне не удалось найти более удобного способа, так что буду рад узнать о других путях и подходах в решении такого рода задач в комментариях.
