Colossus (или GFS2) – это проприетарная распределенная файловая система от Google, запущенная на production-серверах в 2009 году. Colossus является эволюционным развитием GFS. Как и ее предшественник GFS, Colossus оптимизирована для работы с большими наборами данных, прекрасно масштабируется, является высокодоступной и отказоустойчивой системой, а также позволяет надежно хранить данные.
В то же время, Colossus решает часть задач, с которыми GFS не справлялась, и устраняет некоторые узкие места предшественника.

Одним из таких принципиальных ограничений связки «GFS + Google MapReduce», как и аналогичной связки «HDFS + Hadoop MapReduce (Classic)» (до появления YARN), была ориентированность исключительно на пакетную обработку данных. В то время как все больше сервисов Google – социальные сервисы, облачное хранилище, картографические сервисы – требовали значительно меньших задержек, чем те, которые свойственны пакетной обработке данных.
Таким образом, в Google столкнулись с необходимостью поддержки near-real-time ответов для некоторых типов запросов.
Кроме того, в GFS chunk имеет размер 64 Мб (хотя размер chunk конфигурируемый), что, в общем случае, не подходит для сервисов Gmail, Google Docs, Google Cloud Storage — бОльшая часть места выделенного под chunk остается незанятой.
Уменьшение размера chunk автоматически привело бы к увеличению таблицы метаданных, в которой хранится file-to-chunk маппинг. А так как:
Кроме того, современные сервисы являются географически распределенными. Геораспределенность позволяет как остаться сервису доступным во время форс-мажоров, так и сокращает время доставки контента до пользователя, который его запрашивает. Но архитектура GFS, описанная в [1], как классическая «Master-Slave»-архитектура, не предполагает реализацию географической распределенности (во всяком случае без существенных издержек).
(Disclaimer: я не нашел ни одного достоверного источника, в полной мере описывающего архитектуру Colossus, поэтому в описании архитектуры имеются как пробелы, так и предположения.)
Colossus был призван решить проблемы GFS, описанные выше. Так размер chunk'а был уменьшен до 1 Мб (по умолчанию), хотя по-прежнему остался конфигурируемым. Возрастающие требования Master-серверов к объему оперативной памяти, необходимой для поддержания таблицы метаданных, были удовлетворены новой «multi cell»-ориентированной архитектурой Colossus.
Так в Colossus есть пул Master-серверов и пул chunk-серверов, разделенных на логические ячейки. Отношение ячейки Master-серверов (до 8 Master-серверов в ячейке) к ячейкам Сhunk-серверов является один ко многим, то есть одна ячейка Master-серверов обслуживает одну и более ячейку Сhunk-серверов.
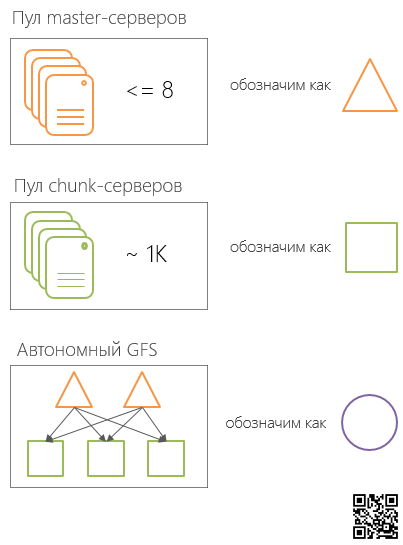
Внутри ЦОД группа ячейка Master-серверов и управляемые ей ячейки Chunk-серверов образуют некоторую автономную — не зависящую от других групп такого типа – файловую систему (далее для краткости SCI, Stand-alone Colossus Instance). Такие SCI расположены в нескольких ЦОД Google и взаимодействуют друг с другом посредством специально разработанного протокола.
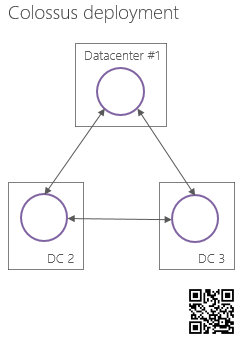
Т.к. в открытом доступе нет подробного описанного инженерами Google внутреннего устройства Colossus, то не ясно, как решается проблема конфликтов, как между SCI, так и внутри ячейки Master-серверов.
Один из традиционных способов решения конфликтов между равнозначными узлами – это кворум серверов. Но если в кворуме четное количество участников, то не исключены ситуации, когда кворум ни к чему и не придет – половина «за», половина «против». А так как в информации о Colossus очень часто звучит, что в ячейке Master-серверов может находится до 8 узлов, то решение конфликтов с помощью кворума ставится под сомнение.
Также совершенно не ясно, каким образом одна SCI знает, какими данными оперирует другая SCI. Если предположить, что такими званиями SCI и не обладает, то это означает, что этими знаниями должен обладать:
В общем Colossus в целом пока скорее «черный ящик», чем «ясная архитектура» построения геораспределенных файловых систем, оперирующих петабайтами данных.
Заключение
Как видно, изменения в Colossus коснулись почти всех элементов файловой системы предшественника (GFS) – от chunk, до композиции кластера; вместе с тем, сохранена преемственность идей и концепций, заложенных в GFS.
Одним из наиболее «звездных» клиентов Colossus является Caffeine — новейшая инфраструктура поисковых сервисов Google.
[1] Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung. The Google File System. ACM SIGOPS Operating Systems Review, 2003.
[10] Andrew Fikes. Storage Architecture and Challenges. Google Faculty Summit, 2010.
* Полный список источников, используемый для подготовки цикла.
Дмитрий Петухов,
MCP,PhD Student, IT-зомби,
человек с кофеином вместо эритроцитов.
В то же время, Colossus решает часть задач, с которыми GFS не справлялась, и устраняет некоторые узкие места предшественника.
Зачем понадобился GFS2? Ограничения GFS
Одним из таких принципиальных ограничений связки «GFS + Google MapReduce», как и аналогичной связки «HDFS + Hadoop MapReduce (Classic)» (до появления YARN), была ориентированность исключительно на пакетную обработку данных. В то время как все больше сервисов Google – социальные сервисы, облачное хранилище, картографические сервисы – требовали значительно меньших задержек, чем те, которые свойственны пакетной обработке данных.
Таким образом, в Google столкнулись с необходимостью поддержки near-real-time ответов для некоторых типов запросов.
Кроме того, в GFS chunk имеет размер 64 Мб (хотя размер chunk конфигурируемый), что, в общем случае, не подходит для сервисов Gmail, Google Docs, Google Cloud Storage — бОльшая часть места выделенного под chunk остается незанятой.
Уменьшение размера chunk автоматически привело бы к увеличению таблицы метаданных, в которой хранится file-to-chunk маппинг. А так как:
- доступ, поддержка актуальности и репликация метаданных – это зона ответственности Master сервера;
- в GFS, как и в HDFS, метаданные полностью загружаются в оперативную память сервера,
Кроме того, современные сервисы являются географически распределенными. Геораспределенность позволяет как остаться сервису доступным во время форс-мажоров, так и сокращает время доставки контента до пользователя, который его запрашивает. Но архитектура GFS, описанная в [1], как классическая «Master-Slave»-архитектура, не предполагает реализацию географической распределенности (во всяком случае без существенных издержек).
Архитектура
(Disclaimer: я не нашел ни одного достоверного источника, в полной мере описывающего архитектуру Colossus, поэтому в описании архитектуры имеются как пробелы, так и предположения.)
Colossus был призван решить проблемы GFS, описанные выше. Так размер chunk'а был уменьшен до 1 Мб (по умолчанию), хотя по-прежнему остался конфигурируемым. Возрастающие требования Master-серверов к объему оперативной памяти, необходимой для поддержания таблицы метаданных, были удовлетворены новой «multi cell»-ориентированной архитектурой Colossus.
Так в Colossus есть пул Master-серверов и пул chunk-серверов, разделенных на логические ячейки. Отношение ячейки Master-серверов (до 8 Master-серверов в ячейке) к ячейкам Сhunk-серверов является один ко многим, то есть одна ячейка Master-серверов обслуживает одну и более ячейку Сhunk-серверов.
Внутри ЦОД группа ячейка Master-серверов и управляемые ей ячейки Chunk-серверов образуют некоторую автономную — не зависящую от других групп такого типа – файловую систему (далее для краткости SCI, Stand-alone Colossus Instance). Такие SCI расположены в нескольких ЦОД Google и взаимодействуют друг с другом посредством специально разработанного протокола.
Т.к. в открытом доступе нет подробного описанного инженерами Google внутреннего устройства Colossus, то не ясно, как решается проблема конфликтов, как между SCI, так и внутри ячейки Master-серверов.
Один из традиционных способов решения конфликтов между равнозначными узлами – это кворум серверов. Но если в кворуме четное количество участников, то не исключены ситуации, когда кворум ни к чему и не придет – половина «за», половина «против». А так как в информации о Colossus очень часто звучит, что в ячейке Master-серверов может находится до 8 узлов, то решение конфликтов с помощью кворума ставится под сомнение.
Также совершенно не ясно, каким образом одна SCI знает, какими данными оперирует другая SCI. Если предположить, что такими званиями SCI и не обладает, то это означает, что этими знаниями должен обладать:
- либо клиент (что еще менее вероятно);
- либо (условно) Supermaster (который опять же является единичной точкой отказа);
- либо это информация (по сути critical state) должна находится в разделяемом всеми SCI хранилище. Тут ожидаемо возникают проблемы блокировок, транзакций, репликации. С последними успешно справляется PaxosDB, либо хранилище реализующее алгоритм Paxos (или аналогичный).
В общем Colossus в целом пока скорее «черный ящик», чем «ясная архитектура» построения геораспределенных файловых систем, оперирующих петабайтами данных.
Заключение
Как видно, изменения в Colossus коснулись почти всех элементов файловой системы предшественника (GFS) – от chunk, до композиции кластера; вместе с тем, сохранена преемственность идей и концепций, заложенных в GFS.
Одним из наиболее «звездных» клиентов Colossus является Caffeine — новейшая инфраструктура поисковых сервисов Google.
Список источников*
[1] Sanjay Ghemawat, Howard Gobioff, Shun-Tak Leung. The Google File System. ACM SIGOPS Operating Systems Review, 2003.
[10] Andrew Fikes. Storage Architecture and Challenges. Google Faculty Summit, 2010.
* Полный список источников, используемый для подготовки цикла.
Дмитрий Петухов,
MCP,
человек с кофеином вместо эритроцитов.
