 Клонирование объектов в JavaScript довольно частая операция. К сожалению, JS не предоставляет быстрых нативных методов для решения этой задачи.
Клонирование объектов в JavaScript довольно частая операция. К сожалению, JS не предоставляет быстрых нативных методов для решения этой задачи.К примеру, популярная Node.JS ORM Sequelize, которую мы используем на backend-е нашего проекта, значительно теряет в производительности на предвыборке большого (1000+) количества строк, только на одном клонировании. Если вместе с этим, к примеру, в бизнес-логике использовать метод
clone известной библиотеки lodash — производительность падает в десятки раз.Но, как оказалось, не всё так плохо и современные JS-движки, такие как, например, V8 JavaScript Engine, могут успешно справляться с этой задачей, если правильно использовать их архитектурные решения. Желающим узнать как клонировать 1 млн. объектов за 30 мс — добро пожаловать под кат, все остальные могут сразу посмотреть реализацию.
Сразу хочется оговориться, что на эту тему уже немного писали. Коллега с Хабра даже делал нативное расширение node-v8-clone, но оно не собирается под свежие версии ноды, сфера его применения ограничена только бэкэндом, да и скорость его ниже предлагаемого решения.
Давайте разберемся на что тратится процессорное время во время клонирования — это две основных операции выделение памяти и запись. В целом, их реализации для многих JS-движков схожи, но далее пойдет речь о V8, как основного для Node.js. Прежде всего, чтобы понять на что уходит время, нужно разобраться в том, что из себя представляют JavaScript объекты.
Представление JavaScript объектов
JS очень гибкий язык программирования и свойства его объектам могут добавляться на лету, большинство JS-движков используют хэш-таблицы для их представления — это дает необходимую гибкость, но замедляет доступ к его свойствам, т.к. требует динамического поиска хэша в словаре. Поэтому оптимизационный компилятор V8, в погоне за скоростью, может на лету переключаться между двумя видами представления объекта — словарями (hash tables) и скрытыми классами (fast, in-object properties).
V8 везде, где это возможно, старается использовать скрытые классы для быстрого доступа к свойствам объекта, в то время как хэш-таблицы используются для представления «сложных» объектов. Скрытый класс в V8 — это ничто иное, как структура в памяти, которая содержит таблицу дескрипторов свойств объекта, его размер и ссылки на конструктор и прототип. Для примера, рассмотрим классическое представление JS-объекта:
function Point(x, y) {
this.x = x;
this.y = y;
}
Если выполнить
new Point(x, y) — создастся новый объект Point. Когда V8 делает это впервые, он создает базовый скрытый класс для Point, назовем его C0 для примера. Т.к. для объекта пока ещё не определено ни одного свойства, скрытый класс C0 пуст.
Выполнение первого выражения в
Point (this.x = x;) создает новое свойство x в объекте Point. При этом, V8:- создает новый скрытый класс
C1, на базеC0, и добавляет вC1информацию о том что у объекта есть одно свойствоx, значение которого хранится в0(нулевом) офсете объектаPoint. - обновляет C0 записью о переходе (a class transition), информирующей о том, что если свойство
xдобавлено в объект описанныйC0тогда скрытый классC1должен использоваться вместоC0. Скрытый класс объектаPointустанавливается вC1.
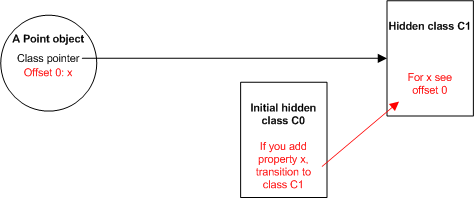
Выполнение второго выражения в
Point (this.y = y;) создает новое свойство y в объекте Point. При этом, V8:- создает новый скрытый класс
C2, на базеC1, и добавляет вC2информацию о том что у объекта также есть свойствоy, значение которого хранится в1(первом) офсете объектаPoint. - обновляет C1 записью о переходе, информирующей о том, что если свойство
yдобавлено в объект описанныйC1тогда скрытый классC2должен использоваться вместоC1. Скрытый класс объектаPointустанавливается вC2.
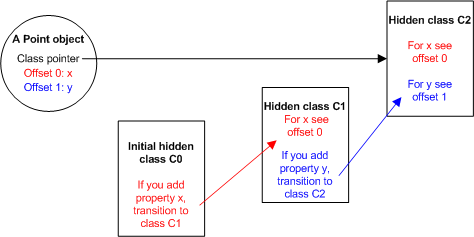
Создание скрытого класса, каждый раз когда добавляется новое свойство может быть не эффективным, но т.к. для новых экземпляров этого же объекта скрытые классы буду переиспользованны — V8 страется использовать их вместо словарей. Механизм скрытых классов помогает избежать поиска по словарю при доступе к свойствам, а также позволяет использовать различные оптимизации основанные на классах, в т.ч. inline caching.
В связи с этим, идеальным объектом для компилятора будет объект — с конструктором в котором четко определен набор его свойств, не изменяющийся в процессе выполнения. Поэтому самой важной оптимизацией для ускорения доступа к свойствам объектов при клонировании является правильное описание его конструктора. Второй важной частью является непосредственно оптимизация самого процесса чтения-записи, о чем и пойдет речь дальше.
Динамическая генерация кода
V8 компилирует JavaScript код напрямую в машинный во время первого исполнения, без промежуточного кода или интерпретатора. Доступ к свойствам объектов при этом оптимизируется inline cache-м, машинные инструкции которого V8 может изменять прямо во время выполнения.
Рассмотрим чтение свойства объекта, в течении первоначального выполнения кода, V8 определяет его текущий скрытый класс и оптимизирует будущие обращения к нему, предсказывая что в этой секции кода объекты будут с тем же скрытым классом. Если V8 удалось предсказать корректно, то значение свойства присваивает (или получается) одной операцией. Если же предсказать верно не удалось, V8 изменяет код и удаляет оптимизацию.
Для примера, возьмем JavaScript код получающий свойство
x объекта Point:point.x
V8 генерирует следующий машинный код для чтения
x:# ebx = the point object
cmp [ebx,<hidden class offset>],<cached hidden class>
jne <inline cache miss>
mov eax,[ebx, <cached x offset>]
Если скрытый класс объекта не соответствует закешированному, выполнение переходит к коду V8 который обрабатывает отсутствие inline cache-а и изменяет его. Если же классы соответствуют, что происходит в большинстве случаев, значение свойства
x просто получается в одну операцию.При обработке множества объектов с одинаковым скрытым классом достигаются те же преимущества что и у большинства статических языков. Комбинация использования скрытых классов для доступа к свойствам объектов и использования кэша значительно увеличивает производительность JavaScript-кода. Именно этими оптимизациями мы и воспользуемся для ускорения процесса клонирования.
Клонирование
Как мы выяснили из теории выше, клонирование будет наиболее быстрым если выполняется два условия:
- все поля объекта описаны в конструкторе — используются скрытые классы, вместо режима словаря (хэш-таблицы)
- явно перечислены все поля для клонирования — присваивание проходит в одну операцию благодаря использованию inline cache-а
Другими словами, для быстрого клонирования объекта
Point нам нужно создать конструктор, который принимает объект этого типа и создает на его основе новый:function Clone(point) {
this.x = point.x;
this.y = point.y;
}
var clonedPoint = new Clone(point);
В принципе и всё, если бы ни одно но — писать такие конструкторы для всех видов объектов в системе достаточно накладно, так же, объекты могут иметь сложную вложенную структуру. Для того чтобы упростить работу с этими оптимизациями мною была написана библиотека создающая конструкторы клонирования для переданного объекта любой вложенности.
Принцип работы библиотеки очень прост — она получает на вход объект, генерирует по его структуре конструктор клонирования, который в дальнейшем можно использовать для клонирования объектов этого типа.
var Clone = FastClone.factory(point);
var clonedPoint = new Clone(point);
Функция генерируется через eval и операция это не дешевая, поэтому преимущество в производительности достигаются в основном при необходимости повторного клонирования объектов с одинаковой структурой. Результаты сравнительного теста производительности для браузера Chromium 50.0.2661.102 Ubuntu 14.04 (64-bit) при помощи benchmark.js:
| библиотека | операций/сек. |
|---|---|
| FastClone | 16 927 673 |
| Object.assign | 535 911 |
| lodash | 66 313 |
| JQuery | 62 164 |
В целом, мы получаем такие же результаты на реальной системе, клонирование ускоряется в 100 — 200 раз на объектах с повторяющейся структурой.
Спасибо за внимание!
Библиотека — github.com/ivolovikov/fastest-clone
Материалы по теме:
jayconrod.com/posts/52/a-tour-of-v8-object-representation
developers.google.com/v8/design
