Привет Хабр. В последнее время мне очень нравится читать статьи на тему deep learning, сверточные сети, обработка изображений и т.д. Действительно, тут есть очень крутые статьи, которые поражают и вдохновляют на собственные "более скромные" подвиги. Итак, хочу представить вниманию русскоязычной публики перевод статьи от Nvidia, написанной 11 августа 2016, в которой представлен их новый инструмент DIGITS и сеть DetectNet для обнаружения объектов на изображениях. Оригинальная статья, конечно, может показаться вначале немного рекламной, да и сеть DetectNet ничего "революционного" не представляет, но комбинация инструмента DIGITS и сети DetectNet, мне кажется, может быть интересной для всех.
Сегодня с помощью NVIDIA Deep Learning GPU Training System (DIGITS) исследователи-аналитики имеют в своем распоряжении всю мощью глубокого обучения (deep learning) для решения самых общих задач в этой области, таких как: подготовка данных, определение сверточной сети, параллельное обучение нескольких моделей, наблюдение за процессом обучения в реальном времени, а также выбор лучшей модели. Полностью интерактивный инструмент DIGITS избавляет вас от программирования и отладки и вы занимаетесь только дизайном и обучением сети.
В версии DIGITS 4 представлен новый подход к задаче обнаружения объектов, который позволяет вам обучать сети для нахождения объектов (таких как лица, транспортные средства или пешеходы) на изображениях и определять ограничивающие прямоугольники (bounding boxes) вокруг объектов. Читайте статью Deep Learning for Object Detection with DIGITS для более детального ознакомления с методом.

Рисунок 1. Результат работы сети DetectNet для обнаружения транспортных средств
Для быстрого освоения метода работы с DIGITS инструмент включает в себя показательный пример модели нейронной сети под названием DetectNet. На рис. 1 показан результат работы сети DetectNet, обученной для обнаружения транспортных средств на изображениях аэрофотосъемки.
Формат данных DetectNet
В качестве входных данных обучающей выборки для задачи классификации изображений используются обыкновенные картинки (обычно небольшого размера и содержащие один объект) и классовые метки (обычно целочисленный идентификатор класса или строковое название класса). С другой стороны, для задачи по обнаружению объектов необходимо больше информации для обучения. Изображения из входных данных обучающей выборки для DetectNet имеют больший размер и содержат несколько объектов, и, для каждого объекта на изображении метка должна содержать не только информацию о классе, которому принадлежит объект, но и расположение углов его ограничивающего прямоугольника. В данном случае наивный выбор формата метки с изменяющейся длиной и размерностью приводит к тому, что определение функции потерь (loss function) может быть затруднено, поскольку количество объектов на обучающем изображении может варьироваться.
DetectNet решает эту проблему, используя фиксированный трехмерный формат метки, что позволяет работать с изображениями любого размера и различным числом присутствующих объектов. Данное представление входных данных для DetectNet было "навеяно" работой [Redmon et al. 2015].
На рис. 2 показана схема обработки изображений из обучающей выборки с разметкой для обучения сети DetectNet. В начале, на исходное изображение накладывается фиксированная решетка с размером немного меньше, чем самый маленький объект, который мы хотим обнаружить. Далее, каждый квадрат решетки размечается следующей информацией: класс объекта, находящегося в квадрате решетки, и координаты пикселя углов ограничивающего прямоугольника относительно центра квадрата решетки. В случае, если ни один объект не попал в квадрат решетки, то используется специальный класс "dontcare" для сохранения фиксированного формата данных. Также в формат входных данных добавляется дополнительное значение "coverage", принимающее значения 0 или 1, чтобы указать, присутствует ли объект в квадрате решетки или нет. В случае, когда несколько объектов попадают в один квадрат решетки, DetectNet выбирает тот объект, который занимает наибольшее количество пикселей. Если количество пикселей одинаково, то выбирается объект с наименьшей ординатой (OY) ограничивающего прямоугольника. Такой выбор объектов не принципиален для изображений аэрофотосъемки, но имеет смысл для изображений с горизонтом, например, изображения от видеорегистратора, где объект с наименьшей ординатой ограничивающего прямоугольника находится на более близком расстоянии к камере.

Рисунок 2. Представление входных данных для сети DetectNet
Таким образом, целью обучения сети DetectNet является предсказание подобного представления данных для заданного изображения. Или, другими словами, DetectNet должен предсказать для каждого квадрата решетки присутствует ли в нем объект, а также вычислить относительные координаты углов ограничивающего прямоугольника.
Архитектура сети DetectNet
Нейронная сеть DetectNet имеет пять частей, определенных в файле модели сети фреймворка Caffe. На рис. 3 показана архитектура сети DetectNet, использованная во время обучения. В ней можно выделить 3 важных процесса:
- Изображения и метки обучающей выборки поступают на вход слоя данных. Далее, преобразующий слой “на лету” производит дополнение данных.
- Полностью сверточная сеть (fully-convolutional network или FCN) производит извлечение признаков и предсказание классов объектов и ограничивающих прямоугольников по квадратам решетки.
- Функции потерь, одновременно, считают ошибку по задачам предсказания покрытия объекта и углов ограничивающих прямоугольников по квадратам решетки.
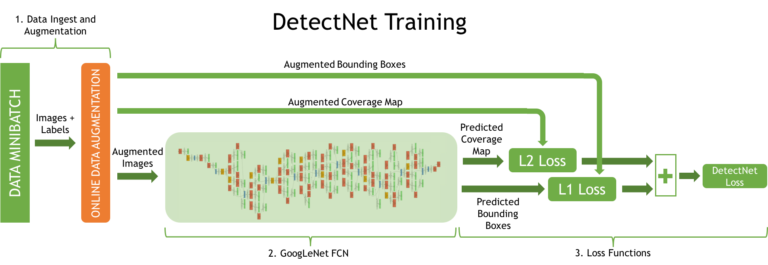
Рисунок 3. Структура сети DetectNet для обучения
На рис. 4 изображена архитектура сети DetectNet для проверки, имеющая два дополнительных важных процесса:
- Кластеризация предсказанных ограничивающих прямоугольников для получения окончательного набора.
- Подсчет упрощенной метрики mAP (mean Average Precision) для измерения эффективности модели по всей тестовой выборке.
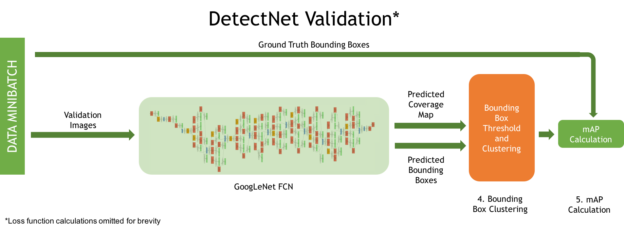
Рисунок 4. Структура сети DetectNet для проверки
Мы можете изменить размер квадрата решетки для обучающих меток, задавая шаг (stride) в пикселях для слоя detectnet_groundtruth_param. Например,
detectnet_groundtruth_param {
stride: 16
scale_cvg: 0.4
gridbox_type: GRIDBOX_MIN
min_cvg_len: 20
coverage_type: RECTANGULAR
image_size_x: 1024
image_size_y: 512
obj_norm: true
crop_bboxes: false
}В параметрах этого слоя вы можете также указать размер обучающих изображений (image_size_x, image_size_y). Таким образом, когда указаны эти параметры, изображения, попадающие на вход сети DetectNet во время обучения, обрезаются случайным образом по этим размерам. Это может быть полезно, если ваша обучающая выборка состоит из изображений очень больших размеров, в которых объекты для обнаружения очень маленькие.
Параметры слоя, который дополняет “на лету” входные данные, определены в detectnet_augmentation_param. Например,
detectnet_augmentation_param {
crop_prob: 1.0
shift_x: 32
shift_y: 32
scale_prob: 0.4
scale_min: 0.8
scale_max: 1.2
flip_prob: 0.5
rotation_prob: 0.0
max_rotate_degree: 5.0
hue_rotation_prob: 0.8
hue_rotation: 30.0
desaturation_prob: 0.8
desaturation_max: 0.8
}Процедура дополнения данных играет важную роль, для успешного обучения высокочувствительного и точного детектора объектов, используя DetectNet. Параметры из detectnet_augmentation_param определяют различные случайные преобразования (смещение, отражения, и т.д.) над обучающей выборкой. Такие преобразования входных данных приводят к тому, что сеть никогда не обрабатывает одно и тоже изображение два раза и, тем самым, становится более устойчивой к переобучению и естественному изменению формы объектов из тестовой выборки.
Подсеть FCN в DetectNet имеет структуру, подобную сети GoogLeNet без слоя входных данных, заключительного слоя pool и выходных слоев [Szegedy et al. 2014]. Такой подход позволяет DetectNet использовать уже обученную модель GoogLeNet, снизить время обучения и улучшить точность полной модели. Полностью сверточная сеть (FCN) — это сверточная нейронная сеть без полностью связанных слоев. Это означает, что сеть может принимать на вход изображения различного размера и обычным образом считать отклик, применяя технику скользящего окошка с шагом. На выходе получается многомерный массив из действительных значений, который может накладываться на входное изображение, подобно входным меткам и квадратной решетке от DetectNet. В итоге, сеть GoogLeNet без заключительного слоя pool представляет собой некую сверточную нейронную сеть со скользящим окошком размера 555 x 555 пикселей и шагом в 16 пикселей [1].
DetectNet использует линейную комбинацию двух независимых функций потерь для создания окончательной функции потерь и оптимизации. Первая функция потерь coverage_loss — это квадратичная ошибка по всем квадратам решетки исходных данных между настоящим и предсказанным покрытием объекта:
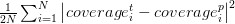
Вторая функция bbox_loss — это средняя ошибка между настоящими и предсказанными углами ограничивающего прямоугольника по всем квадратам решетки:

Фреймворк Caffe минимизирует взвешенную сумму значений этих функций потерь.
Выходные данные сети DetectNet
Последние слои сети DetectNet производят фильтрацию и кластеризацию набора сгенерированных ограничивающих прямоугольников для квадратов решетки. Для этого используется алгоритм groupRectangles из библиотеки OpenCV. Фильтрация ограничивающих прямоугольников производится пороговым методом по значению предсказанного покрытия объекта. Значение порога задается параметром gridbox_cvg_threshold в файле prototxt модели DetectNet. Кластеризация ограничивающих прямоугольников осуществляется с использованием критерия эквивалентности прямоугольников, который объединяет фигуры подобного местоположения и размера. Сходство прямоугольников определяется переменной eps: при нулевом значении прямоугольники не объединяются, а при значении, стремящимся к плюс бесконечности, все прямоугольники попадают в один кластер. После объединения прямоугольников в кластеры, происходит пороговая фильтрация малых кластеров с порогом, заданным параметром gridbox_rect_thresh, а по оставшимся кластерам считаются средние прямоугольники, которые записываются в список выходных данных. Метод кластеризации реализован функцией в Python и вызывается в Caffe через интерфейс “Python Layers“. Параметры алгоритма groupRectangles задаются через слой cluster в файле модели сети DetectNet.
В DetectNet интерфейс “Python Layers“ используется также для вычисления и вывода упрощенной метрики mAP (mean Average Precision), подсчитанной по окончательному набору ограничивающих прямоугольников. Для предсказанного и настоящего ограничивающих прямоугольников рассчитывается значение Intersection over Union (IoU) — отношение площади пересечения прямоугольников к сумме их площадей. При использовании порогового значения (по умолчанию 0.7) для IoU, предсказанный прямоугольник может быть отнесен в категорию истинно-положительных или ложно-положительных предсказаний. В случае, когда значение IoU для пары прямоугольников не превосходит пороговое значение, предсказанный прямоугольник попадает в категорию ложно-отрицательных предсказаний — объект не был обнаружен. Таким образом, упрощенная метрика mAP в DetectNet вычисляется как произведение точности (precision — отношение истинно-положительных к сумме истинно-положительных и ложно-положительных) на меру полноты (recall — отношение истинно-положительных к сумме истинно-положительных и истинно-отрицательных).

Эта метрика является удобной характеристикой чувствительности сети DetectNet к обнаружению объектов обучающей выборки, отбрасыванию ложных результатов и точности полученных ограничивающих прямоугольников. Более подробную информацию об анализе ошибок детектирования объектов можно найти в статье [Hoiem et al. 2012].
Эффективность обучения и результаты
Основное преимущество сети DetectNet для задачи обнаружения объектов — это эффективность, с которой детектируются объекты, и точность сгенерированных ограничивающих прямоугольников. Наличие полностью сверточной сети (FCN) позволяет сети DetectNet быть более эффективной по сравнения с использованием классификатора на базе нейронной сети на скользящем окошке. Таким образом избегаются лишние вычисления, связанные с перекрытием окошек. Данный подход с единой архитектурой нейронной сети является также более простым и элегантным для решения задачи обнаружения.
Обучение сети DetectNet в DIGITS 4 с Nvidia Caffe 0.15.7 и cuDNN RC 5.1 на выборке из 307 обучающих и 24 тестовых изображений, размером 1536 x 1024 пикселей, занимает 63 минуты, используя одну графическую карту Titan X.
Время детектирования объектов сетью DetectNet на изображениях, размером 1536 x 1024 пикселей, с размером решетки 16 пикселей, на предыдущей конфигурации (одна TitanX, Nvidia Caffe 0.15.7, cuDNN RC 5.1) занимает 41 мс (примерно 24 fps).
Первые шаги с DetectNet
Если вы желаете попробовать сеть DetectNet на собственных данных, вы можете скачать DIGITS 4. Пошаговая демонстрация рабочего процесса детектирования объектов в DIGITS представлена здесь.
Читайте также пост Deep Learning for Object Detection with DIGITS для ознакомления с методом использования функциональности обнаружения объектов в DIGITS 4.
Если вас интересуют плюсы и минусы различных подходов с использованием глубокого обучения в задаче обнаружения объектов, смотрите выступление Jon Barker на GTC 2016
Другие обучающие материалы по глубокому обучению, включая вебинары итд, можно найти в NVIDIA Deep Learning Institute.
Ссылки
Hoiem, D., Chodpathumwan, Y., and Dai, Q. 2012. Diagnosing Error in Object Detectors. Computer Vision – ECCV 2012, Springer Berlin Heidelberg, 340–353.
Redmon, J., Divvala, S., Girshick, R., and Farhadi, A. 2015. You Only Look Once: Unified, Real-Time Object Detection. arXiv [cs.CV]. http://arxiv.org/abs/1506.02640.
Szegedy, C., Liu, W., Jia, Y., et al. 2014. Going Deeper with Convolutions. arXiv [cs.CV]. http://arxiv.org/abs/1409.4842.
Дополнительная информация и ссылки от переводчика
Оригинал статьи можно найти здесь. Проект DIGITS является открытым и источники можно найти здесь. Файл prototxt сети DetectNet можно найти здесь или в виде изображения тут.
Про установку DIGITS
Подробную инструкцию по установке можно найти здесь.
Приложению DIGITS для запуска необходим Caffe, а точнее форк от NVidia, куда добавлены слои Python, необходимые для сети DetectNet. Этот форк "без особых проблем" может устанавливается на Mac OSX и Ubuntu. С Windows проблема в том, что ветка windows от BVLC/Caffe отсутcтвует в форке, поэтому как пишут сами авторы: DIGITS for Windows does not support DetectNet. Таким образом, на Windows можно установить BVLC/Caffe и запускать "стандартные" сети.
Примечания
[1] Using GoogLeNet with it’s final pooling layer removed results in the sliding window application of a CNN with a receptive field of 555 x 555 pixels and a stride of 16 pixels.

{kind=link}