— пусть лучше небольшая, но фейербаховская...
Виктор Пелевин «Поколение Пи»
Недавний релиз ядра Linux 4.9 отличный повод рассказать о предстоящем разгоне WiFi. Сразу оговорюсь — пост не о том, как увеличить зону покрытия или менять регуляторные домены. Ничего такого делать не надо, достаточно обновить ядро после того, как патчи буфероборца Dave Täht будут в стабильной ветке.
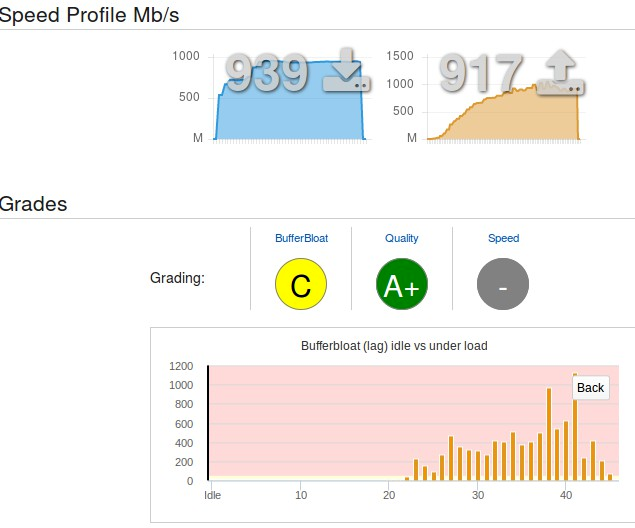
Значительное повышение скорости достигнуто за счет уменьшения задержки [1] и избыточной буферизации [2] в сети. Разработчикам пришлось ради этого перелопатить mac80211, убрать кое-что сверху, добавить снизу и после этого задержки в сети сократились на порядок. Цена вопроса? Патч в 200 строк. Подробности под катом.
Тот самый Bufferbloat
Bufferbloat — это излишняя буферизация в сетевом оборудовании провайдера, что приводит к нежеланным задержкам передачи данных. При достаточно загруженном канале каждое соединение отъедает миллисекунды, которые затем превращаются в секунды, а иногда и минуты ожидания. Если сетевая задержка равна 1 секунде, то slashdot.org будет загружаться целых 4 минуты!
# flent -l 300 -H server –streams=12 tcp_ndown &
# wget -E -H -k -K -p https://www.slashdot.org
...
FINISHED --2016-10-22 13:43:35--
Total wall clock time: 232.8s
Downloaded: 62 files, 1.8M in 0.9s (77KB/s)Первая команда использует питоновский wrapper для netperf, это мощный инструмент проведения контрольных замеров[3] сетевых подключений.
-l 300 #тест длится 5 минут
-H server #подключиться к хосту server
-streams=12 tcp_ndown #12 потоков tcp downloadFlent загружает канал так, чтобы соединение устанавливалось с секундной задержкой. Установка соединения заняла 99.6% времени исполнения, в результате реальная скорость упала до жалких 77 KB/с. При нулевой задержке та же страница загружается за 8 секунд. Таким образом время кругового пути[4] и задержка имеют большее значение, чем пропускная способность.
На стороне провайдера ИБ носит характер эпидемии, но и на пользовательском оборудовании его хватает. Довольно долго каждый сетевой драйвер проектировался с расчетом на нереально высокие потребности буферизации данных, так как разработчики оптимизировали планировщик пакетов для самых высоких скоростей. Однако IRL их редко используют во время WiFi подключения. Вот из-за чего котики загружаются медленно, а видео-звонки превращаются в пытку. Проверьте вашу ИБ без СМС и регистрации.
Неприятность в том, что основной bufferbloat на стороне провайдера, исправив ситуацию там, получаешь прирост скорости соединения на халяву. Speedtest ISP Xfinity и Google Fiber.
Не сказать, что дело ограничивалось одним лишь нытьем. Начиная с Linux 3.3 вышла целая серия исправлений и оптимизаций направленных на устранение ИБ.
- Linux 3.3: Byte Queue Limits
- Linux 3.4 RED bug fixes & IW10 added & SFQRED
- Linux 3.5 Fair/Flow Queuing packet scheduling (fq_codel, codel)
- Linux 3.7 TCP small queues (TSQ)
- Linux 3.12 TSO/GSO improvements
- Linux 3.13 Host FQ + Pacing (sch_fq)
- Linux 3.15 Change to microseconds from milliseconds throughout networking kernel
- Linux 3.17 Network Batching API
- Linux 4.9 BBR (Bottleneck Bandwidth and RTT)
Последний в этой серии исправлений алгоритм BBR. Новость с opennet.ru.
В состав ядра включена реализация предложенного компанией Google алгоритма контроля перегрузки TCP (congestion control) — BBR (Bottleneck Bandwidth and RTT), успешно применяемого для увеличения пропускной способности и сокращения задержек передачи данных для трафика с google.com и YouTube. BBR требует внесения изменений только на стороне отправителя, программное обеспечение сетевой инфраструктуры и принимающей стороны остаётся без изменений. Вместо использования потери пакетов как индикатора перегрузки, в BBR применяются методы моделирования канала связи, прогнозирующие имеющуюся пропускную способность через последовательные проверки и оценку времени приема-передачи (RTT), но не доводя до потери пакетов или задержек в передаче. На начальной стадии соединения BBR оценивает потолок пропускной способности канала, затем снижает интенсивность отправки для разгрузки очереди и переходит в режим корректировки, то повышая, то снижая интенсивность отправки, балансируя между максимальной пропускной способностью и незаполненностью очереди пакетов;
Эти изменения затронули почти все сетевые протоколы, однако обошли стороной WiFi и LTE. Так не могло долго продолжаться и за WiFi взялись всерьез. Проект Make WiFi Fast собрал сотни участников во главе с командой ядерных сетевиков.
Терминология
QDiscили Queuing Discipline — обычный FIFO планировщик, он находится между IP стеком и драйвером.
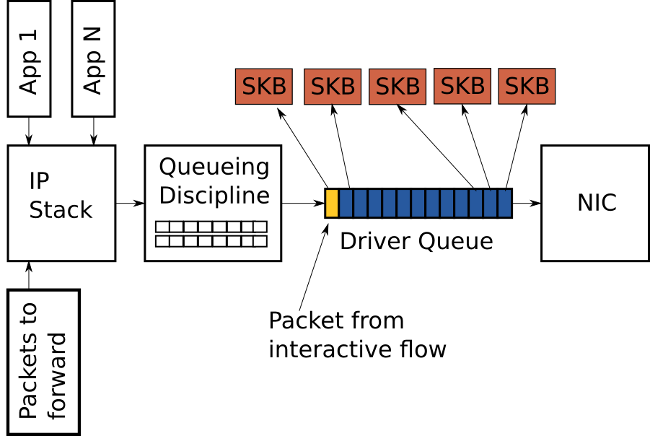
- Планировщик
fq_codelне так прост. О нем уже писали на Хабре, поэтому не буду повторяться.
fq_codel — один из самых эффективных и современных алгоритмов, использующий AQM.- TXOP — transmit opportunity, попытка отправки.
Как патчами разгоняли WiFi
Dave Täht, который уже на раз спасал интернет за последние шесть лет, атаковал проблему с помощью новых и лучших бенчмарков, которые самому же пришлось разрабатывать. Довольно популярный в научной среде и за ее пределами Iperf3, вообще оказался профнепригодным, так как по умолчанию предполагает нереальные 100 ms ИБ.
while( testing)
sleep 100ms
while( total_bytes_sent / total_elapsed_time < target_rate)
transmit buffer of dataТак было до патча. Обратите внимание на огромные задержки в > 10 на верхнем и нижнем уровне WiFi стека.
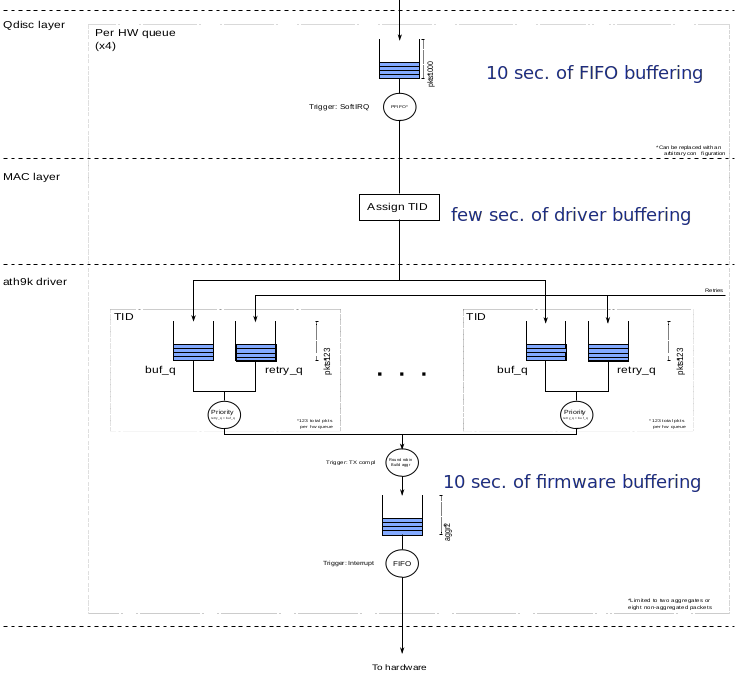
- QDisc убрали напрочь. Очередь теперь формируется по станциям и продвигается по круговому циклу, a. k. a. Round Robin Fair Queuing.
- Буферизация перешла на уровень промежуточного планировщика MAC80211, который управляется со стороны
fq_codel. у него минимальный размер, не больше 2 TXOP. - Минимум буферизации в драйвере, самое большое 2 пула TXOP (1.2-10ms): 1 готовый агрегированный фрейм для повторной попытки и еще 1 на подхвате.
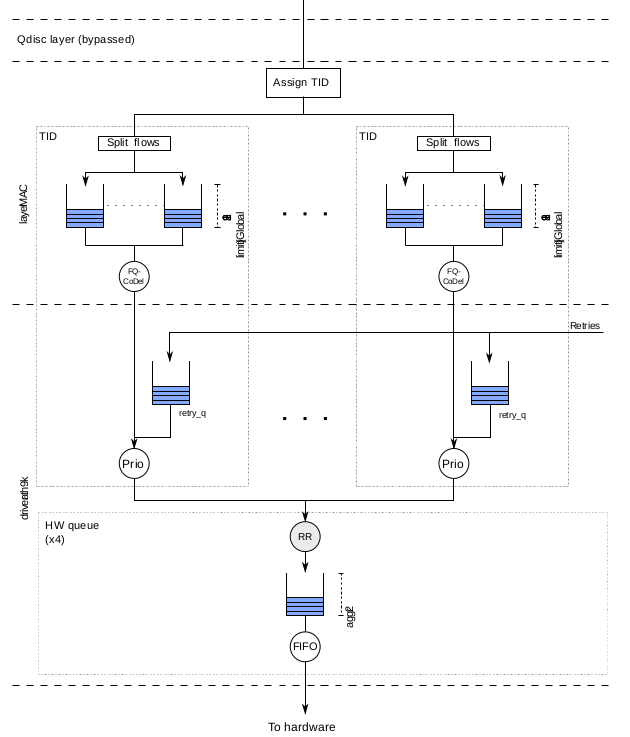
MAC80211 больше не складирует пакеты на нижнем уровне драйвера, а отправляет их промежуточному планировщику, докладывает об этом драйверу и тот забирает их по мере поступления. Благодаря этому MAC80211 имеет больше информации о том, когда происходит передача данных. Задержки от буферизации благодаря этому составили всего 2-12 ms.
Чего удалось достичь
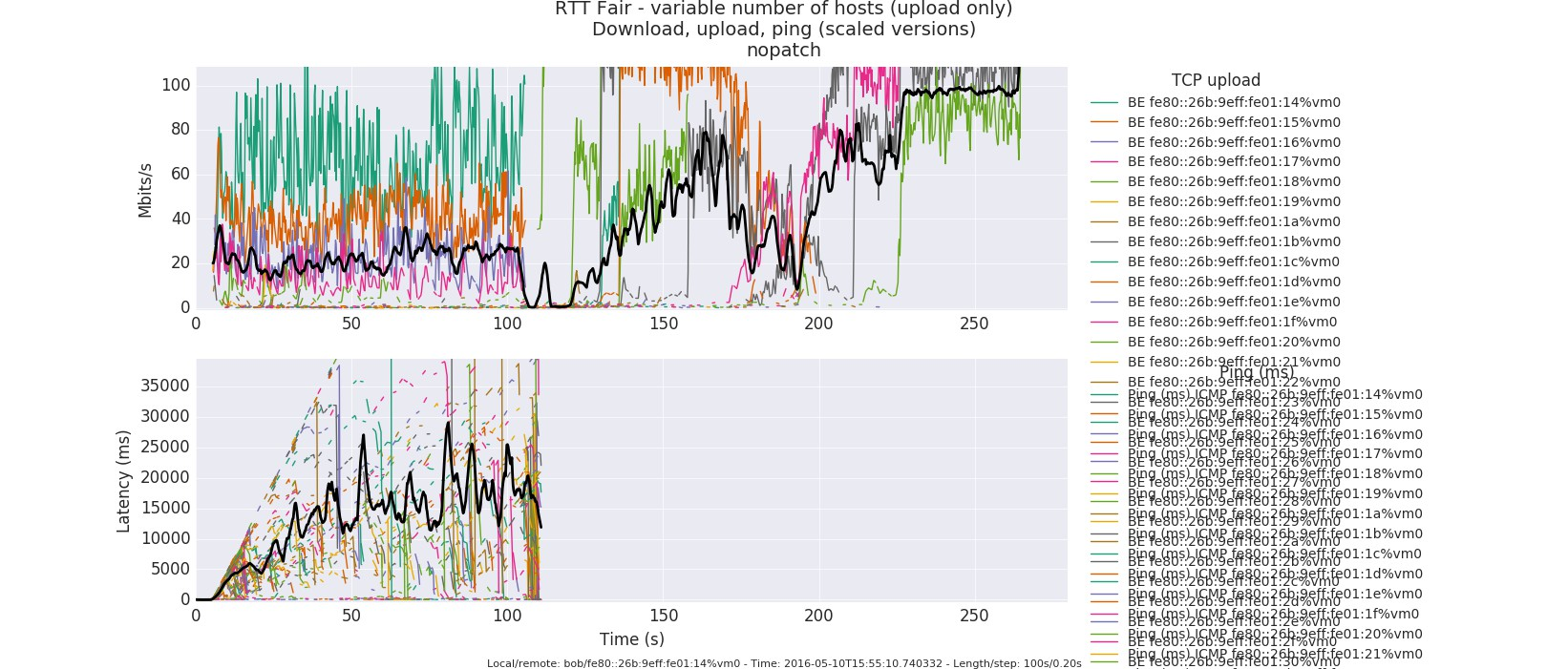
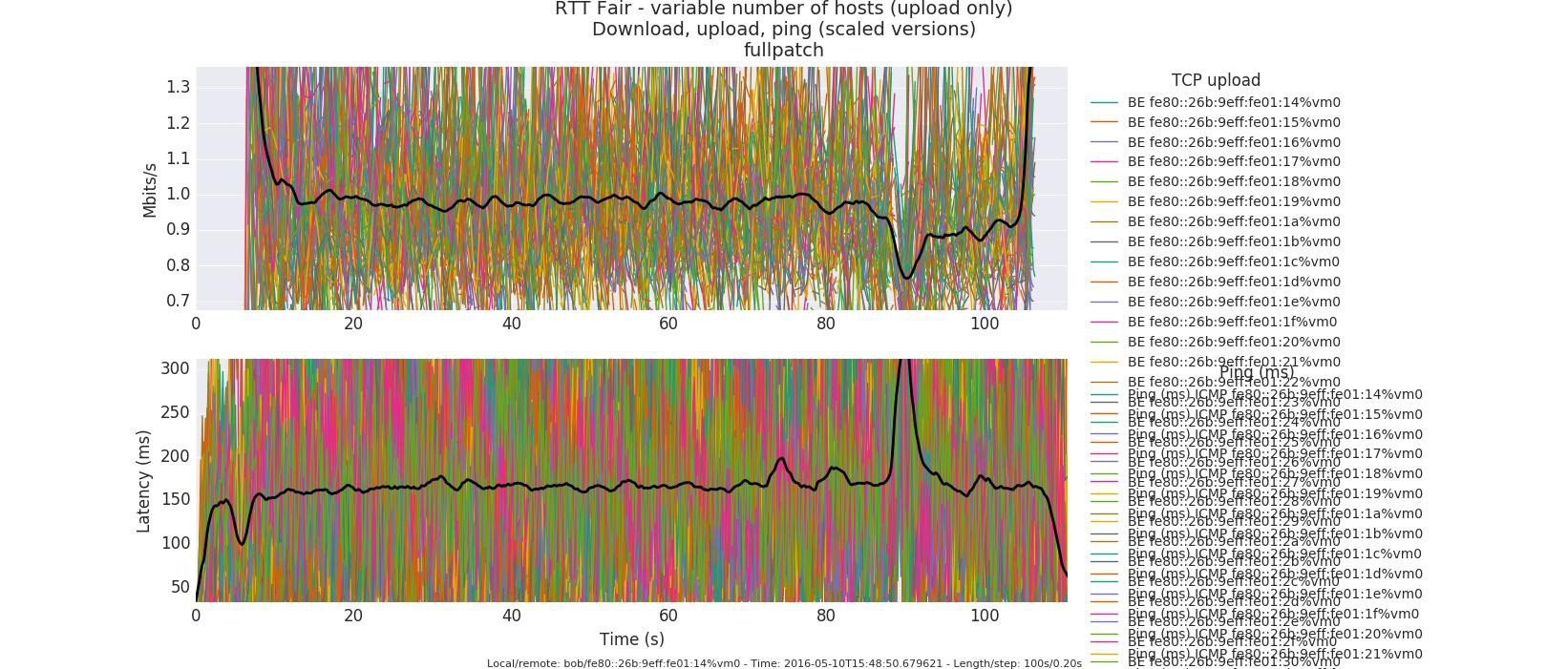
ИБ удалось избыть настолько, что задержки снизились с пиковых значений 1-2 секунд до 40 msec. Наиболее наглядной иллюстрацией будет картинка на которой видны WiFi сессии на 100 рабочих станций до и после патча.
До патча, лишь 5 станций успешно стартовали. Чудовищные > 15 секунд тормоза. Кликабельно.
После патча, все станции успешно стартовали. Задержки приемлемые 150-300 msec. Кликабельно.
Теперь ложка дегтя. Пока лишь драйвера ath9k полностью поддерживают все эти новшества, ath10k уже почти готов. Остальным пока придется подождать, но уверен, остальные драйвера тоже будут активно дорабатываться после того, как патчи попадут в стабильную ветку.
Использованные материалы и полезные ссылки
- Making WiFI Fast
- Linux WiFi latencies
- Петиция в FCC
- Проект Make WiFi Fast.
- Queueing in the Linux Network Stack
