
При создании веб-приложения мы в какой-то момент задаемся вопросом — как управлять его состоянием? Vue предоставляет нам способ управлять им в пределах одного компонента, подход очень простой, и при этом замечательно работает. Но что делать, если в приложении множество компонентов, которые должны иметь доступ к одним и тем же данным? Одно из решений этой задачи — Vuex, инструмент для централизованного управления состоянием. В данной статье мы рассмотрим из чего он состоит и как его использовать.
Что такое Vuex?
В официальной документации Vuex описывается следующим образом:
Vuex — это паттерн управления состоянием и библиотека для приложений на Vue.js. Он служит центральным хранилищем данных для всех компонентов приложения и обеспечивает предсказуемость изменения данных при помощи определённых правил
Лучше понять местоположение Vuex в приложении поможет следующая схема:
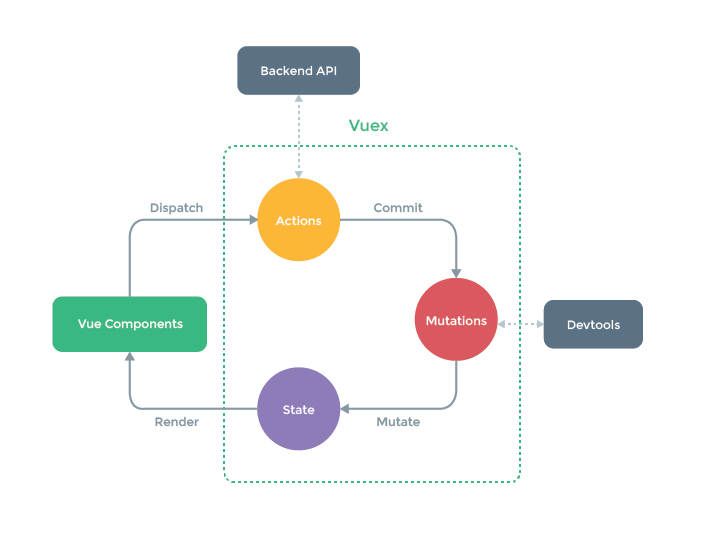
Как можно заметить, хранилище становится своеобразным связующим звеном для всех остальных частей приложения. Подробное описание этого есть в документации, (в том числе и на русском), целью же данной статьи будет быстрое погружение.
Для того, чтобы начать использовать Vuex нам нужно подключить его в наш проект — это можно сделать через npm, или просто подключить библиотеку с cdnjs. Мы не будем акцентировать на этом внимание, а перейдем сразу к созданию базового хранилища:
Vue.use(Vuex)
const store = new Vuex.Store({
state: {},
actions: {},
mutations: {},
getters: {},
modules: {}
})
Хранилище состоит из пяти объектов, каждый из которых играет определенную логическую роль в приложении. Рассмотрим их по порядку.
State
Здесь мы определяем структуру данных нашего приложения, а также можем указать значения по умолчанию. Для того, чтобы не быть голословными, давайте определимся, что будем писать приложение для заметок. Соответственно в хранилище нужно положить массив с заметками:
state: {
notes: []
}
Actions
В данной части объявляются методы, которые будут вызывать какие-либо изменения в хранилище. Здесь мы можем сделать запрос к серверу, и после получения ответа вызвать изменение состояния. Actions могут быть вызваны из компонентов с помощью метода dispatch. Мы еще увидим его в действии, а пока просто добавим метод для добавления заметки. Поскольку сервера у нас нет, он будет содержать только следующее:
actions: {
addNote({commit}, note) {
commit('ADD_NOTE', note)
}
}
commit — это способ вызвать мутацию, изменение состояния. Именование мутаций с помощью заглавных букв не является обязательным, но имеет свой смысл — если в коде встретилось такое название метода, мы можем быть уверены в его предназначении (он изменяет состояние).
Mutations
В мутациях изменяется состояние. Здесь не может быть асинхронных вызовов функций, вычислений и.т.д. — только изменение состояния. В нашем примере с добавлением заметки это будет выглядеть примерно так:
mutations: {
ADD_NOTE(state, note) {
state.notes.push(note)
}
}
Getters
Для того, чтобы использовать данные, положенные в хранилище, их нужно оттуда достать. Причем часто нам нужны не просто данные, а только часть из них — мы хотим применить к ним какие-то фильтры. Геттеры дают нам такую возможность. В базовом варианте мы можем просто вернуть заметки в том виде, в котором они есть:
getters: {
notes(state) {
return state.notes
}
}
Modules
По мере роста приложения хранилище увеличивается и возможность разбить его на части становится все более востребованной. Модули позволяют разделить одно хранилище на несколько хранилищ, но при этом хранить их в виде единого дерева хранилищ.
const moduleA = { state: {}, mutations: {}, actions: {}, getters: {} }
const moduleB = { state: {}, mutations: {}, actions: {}, getters: {} }
const store = new Vuex.Store({
modules: {
a: moduleA,
b: moduleB
}
})
store.state.a // -> состояние модуля moduleA
store.state.b // -> состояние модуля moduleB
Более подробно о модулях и пространствах имен можно почитать в документации.
Переходим от слов к делу
Разобравшись с тем, из чего состоит Vuex, соберем наше мини-приложение. Для начала объединим рассмотренные выше пять частей в хранилище и передадим его в качестве аргумента в объект Vue, для того, чтобы его использовать. Хранилище будет доступно через this.$store и в дочерних компонентах. Также понадобится метод addNew для добавления новой заметки. Обратите внимание на использование геттера и метода dispatch для работы с хранилищем.
const store = new Vuex.Store({
state: {
notes: []
},
actions: {
addNote({commit}, note) {
commit('ADD_NOTE', note)
}
},
mutations: {
ADD_NOTE(state, note) {
state.notes.push(note)
}
},
getters: {
notes(state) {
return state.notes
}
}
})
new Vue({
el: '#app',
store,
computed: {
notes() {
return this.$store.getters.notes;
}
},
methods: {
addNew() {
this.$store.dispatch('addNote', { text: 'новая заметка' })
}
}
})
Таким образом мы сделали простейшее приложение, позволяющее добавлять и хранить заметки. Остается добавить разметку для отображения их на странице. Исходный код доступен в песочнице на codepen.
Заключение
Мы рассмотрели устройство Vuex и базовый пример его использования. Как можно видеть, инструмент простой и интуитивно понятный. Но нужно понимать его сферу применения. При создании простого приложения, вроде того, что мы написали выше, использование Vuex кажется излишним, но по мере роста приложения он может стать незаменимым подспорьем в управлении состоянием.
Документация на английском
Документация на русском
