В продолжение статьи «Поиск в пространстве стратегий. AI водитель». Я сделал мини-игру жанра «файтинг», где обучаемый AI дерётся с другими, рукописными ботами, и разрабатывает стратегию победы методом проб и ошибок.
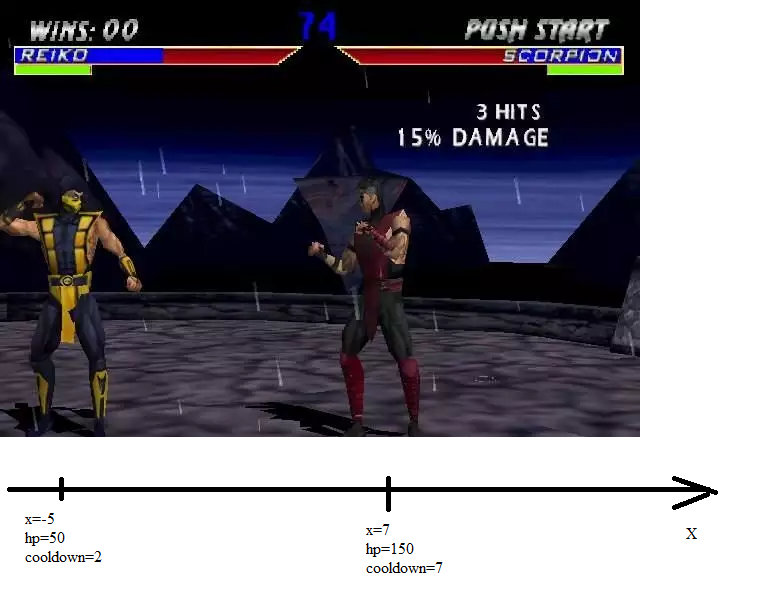
В этой игре дерутся два парня вроде такого:

Они расположены на координатной оси, обладают некоторым запасом здоровья, а ещё у них есть параметр «cooldown». Cooldown – это сколько тактов боец пропустит из-за того, что выполнил данное действие. Например, действие «идти» вызывает cooldown 2, а действие «удар ножом» вызывает cooldown 4. Действовать можно лишь когда cooldown опустился до нуля (он каждый ход уменьшается на единицу, если ещё не равен нулю).
Итак, есть два бойца. У каждого есть координата, здоровье и кулдаун:
Каждый из бойцов может в свой ход выполнить одно из 6 действий:
1) Идти вправо на 1 (вызывает cooldown 2)
2) Идти влево на 1 (вызывает cooldown 2)
3) Ждать (вызывает cooldown 1)
4) Удар ножом (вызывает cooldown 4, наносит 20 урона, если расстояние до противника не более 1)
5) Выстрел из арбалета (вызывает cooldown 10; на расстоянии до 5 клеток наносит 10 урона; до 12 клеток наносит 4 урона)
6) Отравление (вызывает cooldown 10; на расстоянии до 8 клеток наносит 2 урона и отравляет. Отравленный противник каждый ход теряет по 1 хп. Отравление действует до конца боя, отравить дважды нельзя)
На вход каждому бойцу поступает информация: x, hp и состояние отравлен/не отравлен о себе и о своём противнике. Кроме того, поступает значение cooldown противника. На выходе у каждая стратегия выдаёт число от 1 до 6.
В случае, когда стратегию реализует нейросеть, она выдаёт 6 чисел, каждое из которых означает «насколько я хочу, чтобы реализовался такой-то вариант». Например, если нейросеть выдала 0 0 1 0 -1 0, это значит, что она выбирает действие 3, так как у 3-его элемента последовательности наибольшее значение.
Один бой длится 70 тактов (или пока один боец не убьёт другого, если это случится раньше). 70 тактов – это 7 выстрелов или 35 шагов.
Определимся с метрикой качества для AI-бойца. Будем считать, что качество игры нейросети за один бой = -100 – (сколько мы потеряли здоровья)+(сколько противник потерял здоровья). Минус сотня нужна потому, что мой оптимизатор хорошо максимизирует только отрицательные величины.
q=-100-(input(3)-units(1).hp)+(input(4)-units(2).hp);
Параметрами данной стратегии будут веса и сдвиги в нейронной сети — испытание нашего AI выглядит следующим образом: в нейросеть загружается набор весов, эта нейросеть некоторое время дерётся в противником, затем она получает оценку качества. Оптимизатор анализирует полученное качество, генерирует новый набор весов (предположительно, дающий лучшее качество), и цикл повторяется.
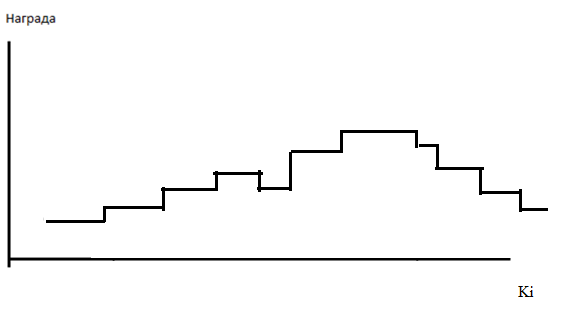
Важный элемент этой игры – ступенчатая зависимость метрики качества от коэффициентов нейросети.

Почему так? Потому что допустим, нейросеть выдала следующий выходной вектор: 0 0 1 0 0 0. А потом мы чуть-чуть изменили один любой параметр. И получили такой выходной вектор: 0 0 0.9 0 0 0. Или 0.1 -0.1 0.9 0 0 -0.1. При этом нейросеть как голосовала за 3-й вариант, так и продолжает за него голосовать.
То есть методы оптимизации, основанные на малых изменениях (градиентный спуск, например), здесь работать не будут.
Качество AI по результату серии боёв будем считать как среднее качество по всем боям плюс наихудшее качество делить на два.
Зачем брать наихудшее? Затем, чтобы нейросеть не научилась идеально играть в одном редком случае, плохо играя во всех остальных, и не стала получать за это кучу очков «в среднем». А зачем брать среднее? Затем, что чем больше выборов нейросети участвует в оценивании, тем больше это:
Похоже на это:
А второй вариант куда легче оптимизировать методами малых изменений, чем первый.
Проводим серию тестов. Метрика качества застряла на величине около -100. То есть AI не стал сражаться. Ну а что? Научиться убегать гораздо легче, чем научиться побеждать.
Введём ограничение. Всякий раз, когда наш боец выходит за пределы арены (от -20 до 20 по x), он погибает. Приказ «ни шагу назад» в действии.
Да, и обсудим стратегию рукописных ботов, коих несколько.
Рукописный бот «Гладиатор». Идёт на сближение. Если достаёт до противника ножом – бьёт. Стреляет только если видит, что убьёт противника одним выстрелом (чего почти никогда не бывает).
AI начал чаще выигрывать, чем проигрывать, через 15 минут обучения (метрика: -95.6). Ещё через минуту он улучшил свой навык (метрика: -88). Ещё через минуту метрика была -77.4. Через минуту -76.2.
Проверяем, как это он побеждает. Запускаем бой.
У Гладиатора координата 10, hp=80, у нейросети координата -9, hp=80.
Гладиатор наступает, а нейросеть стоит на месте и делает удары ножом в пустоту. Как только Гладиатор дошёл до рубежа стрельбы ядом, нейросеть стреляет. Затем, когда кулдаун проходит, нейросеть продолжает бесполезно махать ножом… Яд стреляет на 8 клеток. Чтобы пройти 8 клеток, надо потратить 16 ходов. Удар ножом – это 4 хода. 16 нацело делится на 4. Это означает, что когда гладиатор подходит к нейросети в упор, она наносит удар ножом раньше Гладиатора. Фактически AI использовал кулдаун от удара ножом в качестве таймера. Теперь соотношение здоровья – 80:34 не в пользу Гладиатора. Если бы нейросеть стреляла из арбалета (что, казалось бы, разумнее, чем бить ножом по воздуху), она упустила бы шанс первого удара.
Время истекло, когда счёт был 45:5 в пользу нейросети.
Создаю несколько новых рукописных ботов.
Рукописный бот «Штурмовик». Идёт на сближение. Если достреливает ядом, и противник ещё не отравлен, применяет яд. Если достреливает из арбалета на короткой дистанции (5 единиц), стреляет. Если противник подошёл в упор, применяет нож.
Рукописный бот «Стрелок». Идёт на сближение. Если достреливает из арбалета хоть как-нибудь — стреляет. Если достреливает ядом и противник не отравлен, использует яд. Если добивает ножом, применяет нож.
Рукописный бот «Башня». Не идёт на сближение. Если достреливает из арбалета хоть как-нибудь — стреляет. Если достреливает ядом и противник не отравлен, использует яд. Если добивает ножом, применяет нож.
И оставляю нейросеть драться с ними на ночь. Для бОльшего сглаживания функции полезности я задам больше испытаний (13 штук) и больше тактов в одном испытании (85 вместо 70).
Соответственно, работать всё это будет теперь медленнее, но я считаю, шансов найти хороший оптимум больше.
10:30 утра. Я проверяю качество обучения сети. -90.96. В наихудшем случае метрика равна -100 (то есть AI и его противник нанесли друг другу поровну урона). В среднем случае -81.9231, то есть AI нанёс на 18 единиц урона больше.
Посмотрим, как дерётся нейросеть с разными видами ботов.
1) Гладиатор. Начальные координаты: -9 у нейросети и 10 у Гладиатора. Гладиатор идёт на сближение, а нейросеть тем временем стреляет в пустоту. Соответственно, нейросеть почти всё время стоит с большими кулдаунами. И… Когда гладиатор оказался на расстоянии 9 от нейросети, кулдаун закончился, и нейросеть ждёт. Не стреляет. Гладиатор делает свой ход, и нейросеть тут же его отравляет. К тому времени, когда Гладиатор подобрался на расстояние 4 до нейросети, её кулдаун после отравления прошёл. Нейросеть наносит удар ножом в пустоту… И кулдаун заканчивается ровно тогда, когда гладиатор подошёл на расстояние удара. Нейросеть бьёт первой, и дальше начинается обмен ударами. 85 тактов не успевают истечь – нейросеть убила Гладиатора. У Гладиатора -18 hp, у нейросети 40. Разница – 58 единиц.
2) Штурмовик. Начальные координаты: у нейросети 5, у Штурмовика -10. Штурмовик идёт в атаку, а нейросеть стоит на месте и машет ножом. Как только Штурмовик оказался в зоне действия яда, нейросеть применяет яд. И тут я замечаю ошибку в коде штурмовика, да и всех других ботов тоже. Из-за этой ошибки они не могут пользоваться ядом.
Тем не менее, я смотрю, что AI делает с ботом «Башня». Да ничего интересного – он с ним просто не дерётся. Видимо, игра от обороны настолько хороша, что нейросеть не пытается противостоять этой стратегии, а просто не ввязывается. И игра заканчивается вничью.
Итак, в 11:02 я доработал стратегии «Штурмовик», «Стрелок» и «Башня», чтобы они могли пользоваться ядом, и запустил нейросеть на обучение. Метрика качества тут же упала до -107.
В 11:04 произошло первое улучшение: метрика достигла -97.31.
И всё. Худший результат хуже -100, так что в 11:59 я перезапускаю поиск с нуля.
После мультистарта и первичной эволюции метрика была около -133. На момент 12:06 метрика уже была -105.4.
Но дальше метрика росла как-то медленно. Я решил выяснить, в чём же дело. Ну конечно! Нейросеть научилась убегать даже в отрезке от -20 до 20. И большинство боёв завершалось вничью. В нескольких боях AI не мог отступать по каким-либо причинам, и там его эффективность колебалась от -53 (разрывает противника вклочья) до -108 (поражение средней тяжести).
Уменьшим размер поля боя. Пусть это будет отрезок от -10 до +10. А ещё будем давать награду всякому, кто может удержать центр – по 1 очку за один ход удержания. К метрике за бой прибавляется число очков за центр для нейросети и вычитается число центр-очков для врага.
И я запускаю обучение с нуля в 16:06. После мультистарта и первичной эволюции получаю качество -126.
В 9:44 на следующий день получаю качество -100.81. То есть бот в среднем выигрывает, но иногда проигрывает. Смотрим, сколько он набирал в разных испытаниях.
-45 -98 -108 -99 -100 -76 -104 -100 -105 -99 -96
3 поражения, 2 ничьи и 6 побед. Посмотрим, что это за ситуации такие, где нейросеть проигрывает.
Битва номер 3, самая проигрышная. Начальные координаты нейросети и противника – это -9 и 9. Здоровье – по 80, стратегия противника – Штурмовик.
Поначалу нейросеть стреляет в пустоту, затем дожидается, когда Штурмовик подойдёт на расстояние отравления, бойцы обмениваются отравлениями (нейросеть стреляет раньше, поэтому опережает противника на 5 hp. Почему именно 5, а не 2, я так и не понял.), затем нейросеть начинает уже привычным образом махать ножом в ожидании противника, в результате Штурмовик первым выходит на ближний рубеж стрельбы из арбалета и стреляет в нейросеть. Этот выстрел был смертельным. Итого, у Штурмовика 5 hp, у нейросети 0. Плюс Штурмовик получил 3 очка за прохождение центра.
-104 очка сеть выбила в 7-ом бою. Координаты нейросети и противника были -6 и 9 соответственно, у обоих по 400 хп, стратегия противника – Стрелок.
Стрелок идёт в наступление, а нейросеть тем временем машет ножом. В результате нейросеть пропускает оптимальный момент для выстрела, и инициативу перехватывает противник. Дальше следует продолжительная перестрелка, и Стрелок успевает сделать на один выстрел больше, чем нейросеть. А выстрел из арбалета на дальнюю дистанцию снимает как раз 4 хп.
-105 очков сеть выбила в 9-ом бою. Координаты нейросети и противника были -1 и 9 соответственно, у нейросети 140 хп, у противника 40, стратегия противника – Штурмовик. Нейросеть в ожидании машет ножом и пропускает оптимальный момент для применения яда. Штурмовик первым пускает яд. В результате он нанёс на 5 урона больше, чем нейросеть.
Нейросеть во-первых, не атакует, а сидит в обороне, во-вторых, ожидает неоптимальным образом, вместо нажатия кнопки «ждать» жмёт кнопку «удар».
Со стратегией «башня» нейросеть дерётся только если они находятся уже на расстоянии выстрела. Стратегию «гладиатор» нейросеть разрывает вклочья: -45 и -76 набиты именно на нём. Стратегии «штурмовик» и «стрелок» нейросеть побеждает за счёт того, что стреляет первой и получает преимущество либо в яде, либо в количестве выстрелов.
Ну и ещё такой AI долго обучается. А в остальном… Вообще-то это AI, принимающий дискретные решения, и он скорее работает, чем нет.
Когда я рассказал об этом AI другу, который только вернулся из армии, он очень удивился моей метрике качества. Расстреливать отступающих, говорил он – плохое решение. Лучше сделай, чтобы AI считал нанесение урона врагу более важным занятием, чем сохранение своего хп.
Сделай его кровожадным!
То есть исправь это:
На это:
Тогда метрика штрафует нас на 1 за получение единицы урона и награждает на 2 за нанесение одной единицы.
Запускаем обучение с нуля. За то время, что прошло до идеи создать берсеркера, я успел сменить процессор на более мощный и написать более быструю реализацию нейросетей, так что всё обучение заняло всего минут 20. 20 минут – и метрика качества равна -65… Только как из этой метрики понять, насколько реально эффективен AI?
Возвращаем не-берсеркерскую метрику
И ужасаемся. «Осторожная» метрика равна -117, во многих сражениях AI снял меньше хп, чем потерял. AI получился чересчур кровожадным – совсем забыл о своём хп.
Меняем метрику на
И продолжаем обучение.
Минут через пять видим результат: q=-75.75.
Результаты по отдельным испытаниям:
0 -91.2000 -76.3000 -49.300 -49.500 -29.5000 -87.200 -73.600 -64.00 -57.00 -82.0000
Снова меняем метрику на «осторожную» и смотрим на результат.
Q=-114.98. Из 11 боёв AI проигрывает.
Подбираем такое значение коэффициента агрессивности, чтобы AI видел у себя одно поражение, то есть чтобы один из 11 боёв заканчивался со счётом меньше -100. Я это хочу сделать, чтобы с одной стороны, и дальше поощрять AI к игре от нападения, а с другой, чтобы у AI было примерно такое же понимание побед и поражений, как и у меня. С точки зрения биологии, я сейчас настраиваю эволюционную траекторию AI.
Итак, при коэффициента агрессивности 1.18 AI уже понимает, что иногда он проигрывает, но ещё не понимает, насколько часто.
Продолжаем обучение.
Спустя полчаса мы достигаем q=-96.
Возвращаем «осторожную» метрику, получаем q=-106.23
Смотрим, сколько очков получил AI в каком бою.
-44 -94 -119 -99 -110 -75 -104 -96 -95 -93 -96
Проиграно: 3 боя. Выиграно: 8 боёв. Ничьи: 0. Это лучше, чем 3 поражения, 2 ничьи и 6 побед, которые получились в испытании без агрессивности.
Посмотрим, как наш AI выиграл в 3-ем с конца бою – без агрессии он тогда проиграл.
Типа противника в этом бою – Штурмовик. Вначале бойцы сближаются, игнорируя возможность выстрелить из арбалета на дальнюю дистанцию. Затем они при первой же возможности отравляют друг друга (AI это делает раньше, и выигрывает за счёт этого единичку хп). Затем AI стреляет из арбалета (на дальнюю дистанцию, со штрафом), а Штурмовик бросается в ближний бой. К моменту, когда Штурмовик оказался на расстоянии прицельного выстрела (5 шагов), AI уже перезарядился и стреляет снова. Штурмовик этого не пережил.
Посмотрим же, как наш AI проигрывает. Запускаем бой номер 3. Противник – снова Штурмовик.
Как и в прошлый раз, враги сходятся на расстояние отравляющего выстрела, но на этот раз Штурмовик смог выстрелить первым, и получить преимущество в 1 хп (ошибка номер 1). Дальше бойцы продолжают сходиться и начинается перестрелка на арбалетах. AI поспешил, и первый снаряд выпустил прежде, чем противник оказался в зоне прицельного огня (ошибка номер 2). Он нанёс урон чуть раньше, зато Штурмовик сделал шаг вперёд и нанёс 10 урона вместо 4. В ходе дальнейшей перестрелки Штурмовик успешно убивает AI.
Из данного эксперименты я делаю следующие выводы:
1) Тот способ создания AI, который пригоден для создания автопилота, пригоден и для создания боевого робота.
2) Иногда для того, чтобы AI достиг заданной цели, ему нужно называть более достижимую цель, а затем постепенно подменять цель на ту, которой мы хотим достичь.
3) Оптимизировать ступенчатую функцию намного тяжелее, чем гладкую.
4) 3 слоя по 11 нейронов – это достаточно для управления роботом, у которого 7 сенсоров и 6 выходнов. Обычно 33 нейронов не хватает на задачи подобной размерности.
Файл с конфигурацией нейросети. К сожалению, я потерял тот файл с хорошо выигрывающим AI, но этот играет не хуже.
При желании можно сыграть против AI — в этом случае надо в Test Seria раскомментировать строчку:
input=[-3.,9.,80,80,0];%Player 2 is a human
В этой игре дерутся два парня вроде такого:
Они расположены на координатной оси, обладают некоторым запасом здоровья, а ещё у них есть параметр «cooldown». Cooldown – это сколько тактов боец пропустит из-за того, что выполнил данное действие. Например, действие «идти» вызывает cooldown 2, а действие «удар ножом» вызывает cooldown 4. Действовать можно лишь когда cooldown опустился до нуля (он каждый ход уменьшается на единицу, если ещё не равен нулю).
Итак, есть два бойца. У каждого есть координата, здоровье и кулдаун:
Каждый из бойцов может в свой ход выполнить одно из 6 действий:
1) Идти вправо на 1 (вызывает cooldown 2)
2) Идти влево на 1 (вызывает cooldown 2)
3) Ждать (вызывает cooldown 1)
4) Удар ножом (вызывает cooldown 4, наносит 20 урона, если расстояние до противника не более 1)
5) Выстрел из арбалета (вызывает cooldown 10; на расстоянии до 5 клеток наносит 10 урона; до 12 клеток наносит 4 урона)
6) Отравление (вызывает cooldown 10; на расстоянии до 8 клеток наносит 2 урона и отравляет. Отравленный противник каждый ход теряет по 1 хп. Отравление действует до конца боя, отравить дважды нельзя)
На вход каждому бойцу поступает информация: x, hp и состояние отравлен/не отравлен о себе и о своём противнике. Кроме того, поступает значение cooldown противника. На выходе у каждая стратегия выдаёт число от 1 до 6.
В случае, когда стратегию реализует нейросеть, она выдаёт 6 чисел, каждое из которых означает «насколько я хочу, чтобы реализовался такой-то вариант». Например, если нейросеть выдала 0 0 1 0 -1 0, это значит, что она выбирает действие 3, так как у 3-его элемента последовательности наибольшее значение.
Один бой длится 70 тактов (или пока один боец не убьёт другого, если это случится раньше). 70 тактов – это 7 выстрелов или 35 шагов.
Определимся с метрикой качества для AI-бойца. Будем считать, что качество игры нейросети за один бой = -100 – (сколько мы потеряли здоровья)+(сколько противник потерял здоровья). Минус сотня нужна потому, что мой оптимизатор хорошо максимизирует только отрицательные величины.
q=-100-(input(3)-units(1).hp)+(input(4)-units(2).hp);
Параметрами данной стратегии будут веса и сдвиги в нейронной сети — испытание нашего AI выглядит следующим образом: в нейросеть загружается набор весов, эта нейросеть некоторое время дерётся в противником, затем она получает оценку качества. Оптимизатор анализирует полученное качество, генерирует новый набор весов (предположительно, дающий лучшее качество), и цикл повторяется.
Важный элемент этой игры – ступенчатая зависимость метрики качества от коэффициентов нейросети.
Почему так? Потому что допустим, нейросеть выдала следующий выходной вектор: 0 0 1 0 0 0. А потом мы чуть-чуть изменили один любой параметр. И получили такой выходной вектор: 0 0 0.9 0 0 0. Или 0.1 -0.1 0.9 0 0 -0.1. При этом нейросеть как голосовала за 3-й вариант, так и продолжает за него голосовать.
То есть методы оптимизации, основанные на малых изменениях (градиентный спуск, например), здесь работать не будут.
Качество AI по результату серии боёв будем считать как среднее качество по всем боям плюс наихудшее качество делить на два.
q=(min(arr)+sum_/countOfPoints)/2 - sum(abs(k))*0.00001;%sum(abs(k)) – это регуляризация. Нужна, чтобы оптимизатор не делал веса сети чересчур большими – тогда алгоритм начинает хуже обучаться. Зачем брать наихудшее? Затем, чтобы нейросеть не научилась идеально играть в одном редком случае, плохо играя во всех остальных, и не стала получать за это кучу очков «в среднем». А зачем брать среднее? Затем, что чем больше выборов нейросети участвует в оценивании, тем больше это:
Похоже на это:
А второй вариант куда легче оптимизировать методами малых изменений, чем первый.
Проводим серию тестов. Метрика качества застряла на величине около -100. То есть AI не стал сражаться. Ну а что? Научиться убегать гораздо легче, чем научиться побеждать.
Введём ограничение. Всякий раз, когда наш боец выходит за пределы арены (от -20 до 20 по x), он погибает. Приказ «ни шагу назад» в действии.
Да, и обсудим стратегию рукописных ботов, коих несколько.
Рукописный бот «Гладиатор». Идёт на сближение. Если достаёт до противника ножом – бьёт. Стреляет только если видит, что убьёт противника одним выстрелом (чего почти никогда не бывает).
AI начал чаще выигрывать, чем проигрывать, через 15 минут обучения (метрика: -95.6). Ещё через минуту он улучшил свой навык (метрика: -88). Ещё через минуту метрика была -77.4. Через минуту -76.2.
Проверяем, как это он побеждает. Запускаем бой.
У Гладиатора координата 10, hp=80, у нейросети координата -9, hp=80.
Гладиатор наступает, а нейросеть стоит на месте и делает удары ножом в пустоту. Как только Гладиатор дошёл до рубежа стрельбы ядом, нейросеть стреляет. Затем, когда кулдаун проходит, нейросеть продолжает бесполезно махать ножом… Яд стреляет на 8 клеток. Чтобы пройти 8 клеток, надо потратить 16 ходов. Удар ножом – это 4 хода. 16 нацело делится на 4. Это означает, что когда гладиатор подходит к нейросети в упор, она наносит удар ножом раньше Гладиатора. Фактически AI использовал кулдаун от удара ножом в качестве таймера. Теперь соотношение здоровья – 80:34 не в пользу Гладиатора. Если бы нейросеть стреляла из арбалета (что, казалось бы, разумнее, чем бить ножом по воздуху), она упустила бы шанс первого удара.
Время истекло, когда счёт был 45:5 в пользу нейросети.
Создаю несколько новых рукописных ботов.
Рукописный бот «Штурмовик». Идёт на сближение. Если достреливает ядом, и противник ещё не отравлен, применяет яд. Если достреливает из арбалета на короткой дистанции (5 единиц), стреляет. Если противник подошёл в упор, применяет нож.
Рукописный бот «Стрелок». Идёт на сближение. Если достреливает из арбалета хоть как-нибудь — стреляет. Если достреливает ядом и противник не отравлен, использует яд. Если добивает ножом, применяет нож.
Рукописный бот «Башня». Не идёт на сближение. Если достреливает из арбалета хоть как-нибудь — стреляет. Если достреливает ядом и противник не отравлен, использует яд. Если добивает ножом, применяет нож.
И оставляю нейросеть драться с ними на ночь. Для бОльшего сглаживания функции полезности я задам больше испытаний (13 штук) и больше тактов в одном испытании (85 вместо 70).
Соответственно, работать всё это будет теперь медленнее, но я считаю, шансов найти хороший оптимум больше.
10:30 утра. Я проверяю качество обучения сети. -90.96. В наихудшем случае метрика равна -100 (то есть AI и его противник нанесли друг другу поровну урона). В среднем случае -81.9231, то есть AI нанёс на 18 единиц урона больше.
Посмотрим, как дерётся нейросеть с разными видами ботов.
1) Гладиатор. Начальные координаты: -9 у нейросети и 10 у Гладиатора. Гладиатор идёт на сближение, а нейросеть тем временем стреляет в пустоту. Соответственно, нейросеть почти всё время стоит с большими кулдаунами. И… Когда гладиатор оказался на расстоянии 9 от нейросети, кулдаун закончился, и нейросеть ждёт. Не стреляет. Гладиатор делает свой ход, и нейросеть тут же его отравляет. К тому времени, когда Гладиатор подобрался на расстояние 4 до нейросети, её кулдаун после отравления прошёл. Нейросеть наносит удар ножом в пустоту… И кулдаун заканчивается ровно тогда, когда гладиатор подошёл на расстояние удара. Нейросеть бьёт первой, и дальше начинается обмен ударами. 85 тактов не успевают истечь – нейросеть убила Гладиатора. У Гладиатора -18 hp, у нейросети 40. Разница – 58 единиц.
2) Штурмовик. Начальные координаты: у нейросети 5, у Штурмовика -10. Штурмовик идёт в атаку, а нейросеть стоит на месте и машет ножом. Как только Штурмовик оказался в зоне действия яда, нейросеть применяет яд. И тут я замечаю ошибку в коде штурмовика, да и всех других ботов тоже. Из-за этой ошибки они не могут пользоваться ядом.
Тем не менее, я смотрю, что AI делает с ботом «Башня». Да ничего интересного – он с ним просто не дерётся. Видимо, игра от обороны настолько хороша, что нейросеть не пытается противостоять этой стратегии, а просто не ввязывается. И игра заканчивается вничью.
Итак, в 11:02 я доработал стратегии «Штурмовик», «Стрелок» и «Башня», чтобы они могли пользоваться ядом, и запустил нейросеть на обучение. Метрика качества тут же упала до -107.
В 11:04 произошло первое улучшение: метрика достигла -97.31.
И всё. Худший результат хуже -100, так что в 11:59 я перезапускаю поиск с нуля.
После мультистарта и первичной эволюции метрика была около -133. На момент 12:06 метрика уже была -105.4.
Но дальше метрика росла как-то медленно. Я решил выяснить, в чём же дело. Ну конечно! Нейросеть научилась убегать даже в отрезке от -20 до 20. И большинство боёв завершалось вничью. В нескольких боях AI не мог отступать по каким-либо причинам, и там его эффективность колебалась от -53 (разрывает противника вклочья) до -108 (поражение средней тяжести).
Уменьшим размер поля боя. Пусть это будет отрезок от -10 до +10. А ещё будем давать награду всякому, кто может удержать центр – по 1 очку за один ход удержания. К метрике за бой прибавляется число очков за центр для нейросети и вычитается число центр-очков для врага.
q=-100-(input(3)-units(1).hp)+(input(4)-units(2).hp)+(center.me-center.enemy);И я запускаю обучение с нуля в 16:06. После мультистарта и первичной эволюции получаю качество -126.
В 9:44 на следующий день получаю качество -100.81. То есть бот в среднем выигрывает, но иногда проигрывает. Смотрим, сколько он набирал в разных испытаниях.
-45 -98 -108 -99 -100 -76 -104 -100 -105 -99 -96
3 поражения, 2 ничьи и 6 побед. Посмотрим, что это за ситуации такие, где нейросеть проигрывает.
Битва номер 3, самая проигрышная. Начальные координаты нейросети и противника – это -9 и 9. Здоровье – по 80, стратегия противника – Штурмовик.
Поначалу нейросеть стреляет в пустоту, затем дожидается, когда Штурмовик подойдёт на расстояние отравления, бойцы обмениваются отравлениями (нейросеть стреляет раньше, поэтому опережает противника на 5 hp. Почему именно 5, а не 2, я так и не понял.), затем нейросеть начинает уже привычным образом махать ножом в ожидании противника, в результате Штурмовик первым выходит на ближний рубеж стрельбы из арбалета и стреляет в нейросеть. Этот выстрел был смертельным. Итого, у Штурмовика 5 hp, у нейросети 0. Плюс Штурмовик получил 3 очка за прохождение центра.
-104 очка сеть выбила в 7-ом бою. Координаты нейросети и противника были -6 и 9 соответственно, у обоих по 400 хп, стратегия противника – Стрелок.
Стрелок идёт в наступление, а нейросеть тем временем машет ножом. В результате нейросеть пропускает оптимальный момент для выстрела, и инициативу перехватывает противник. Дальше следует продолжительная перестрелка, и Стрелок успевает сделать на один выстрел больше, чем нейросеть. А выстрел из арбалета на дальнюю дистанцию снимает как раз 4 хп.
-105 очков сеть выбила в 9-ом бою. Координаты нейросети и противника были -1 и 9 соответственно, у нейросети 140 хп, у противника 40, стратегия противника – Штурмовик. Нейросеть в ожидании машет ножом и пропускает оптимальный момент для применения яда. Штурмовик первым пускает яд. В результате он нанёс на 5 урона больше, чем нейросеть.
Промежуточные выводы.
Нейросеть во-первых, не атакует, а сидит в обороне, во-вторых, ожидает неоптимальным образом, вместо нажатия кнопки «ждать» жмёт кнопку «удар».
Со стратегией «башня» нейросеть дерётся только если они находятся уже на расстоянии выстрела. Стратегию «гладиатор» нейросеть разрывает вклочья: -45 и -76 набиты именно на нём. Стратегии «штурмовик» и «стрелок» нейросеть побеждает за счёт того, что стреляет первой и получает преимущество либо в яде, либо в количестве выстрелов.
Ну и ещё такой AI долго обучается. А в остальном… Вообще-то это AI, принимающий дискретные решения, и он скорее работает, чем нет.
Нейросеть-берсеркер
Когда я рассказал об этом AI другу, который только вернулся из армии, он очень удивился моей метрике качества. Расстреливать отступающих, говорил он – плохое решение. Лучше сделай, чтобы AI считал нанесение урона врагу более важным занятием, чем сохранение своего хп.
Сделай его кровожадным!
То есть исправь это:
q=-100-(input(3)-units(1).hp)+(input(4)-units(2).hp); На это:
q=-100-(input(3)-units(1).hp)+2*(input(4)-units(2).hp); %2 – коэффициент агрессивностиТогда метрика штрафует нас на 1 за получение единицы урона и награждает на 2 за нанесение одной единицы.
Запускаем обучение с нуля. За то время, что прошло до идеи создать берсеркера, я успел сменить процессор на более мощный и написать более быструю реализацию нейросетей, так что всё обучение заняло всего минут 20. 20 минут – и метрика качества равна -65… Только как из этой метрики понять, насколько реально эффективен AI?
Возвращаем не-берсеркерскую метрику
q=-100-(input(3)-units(1).hp)+(input(4)-units(2).hp); И ужасаемся. «Осторожная» метрика равна -117, во многих сражениях AI снял меньше хп, чем потерял. AI получился чересчур кровожадным – совсем забыл о своём хп.
Меняем метрику на
q=-100-(input(3)-units(1).hp)+1.7*(input(4)-units(2).hp); %1.7 – коэффициент агрессивностиИ продолжаем обучение.
Минут через пять видим результат: q=-75.75.
Результаты по отдельным испытаниям:
0 -91.2000 -76.3000 -49.300 -49.500 -29.5000 -87.200 -73.600 -64.00 -57.00 -82.0000
Снова меняем метрику на «осторожную» и смотрим на результат.
Q=-114.98. Из 11 боёв AI проигрывает.
Подбираем такое значение коэффициента агрессивности, чтобы AI видел у себя одно поражение, то есть чтобы один из 11 боёв заканчивался со счётом меньше -100. Я это хочу сделать, чтобы с одной стороны, и дальше поощрять AI к игре от нападения, а с другой, чтобы у AI было примерно такое же понимание побед и поражений, как и у меня. С точки зрения биологии, я сейчас настраиваю эволюционную траекторию AI.
Итак, при коэффициента агрессивности 1.18 AI уже понимает, что иногда он проигрывает, но ещё не понимает, насколько часто.
Продолжаем обучение.
Спустя полчаса мы достигаем q=-96.
Возвращаем «осторожную» метрику, получаем q=-106.23
Смотрим, сколько очков получил AI в каком бою.
-44 -94 -119 -99 -110 -75 -104 -96 -95 -93 -96
Проиграно: 3 боя. Выиграно: 8 боёв. Ничьи: 0. Это лучше, чем 3 поражения, 2 ничьи и 6 побед, которые получились в испытании без агрессивности.
Посмотрим, как наш AI выиграл в 3-ем с конца бою – без агрессии он тогда проиграл.
Типа противника в этом бою – Штурмовик. Вначале бойцы сближаются, игнорируя возможность выстрелить из арбалета на дальнюю дистанцию. Затем они при первой же возможности отравляют друг друга (AI это делает раньше, и выигрывает за счёт этого единичку хп). Затем AI стреляет из арбалета (на дальнюю дистанцию, со штрафом), а Штурмовик бросается в ближний бой. К моменту, когда Штурмовик оказался на расстоянии прицельного выстрела (5 шагов), AI уже перезарядился и стреляет снова. Штурмовик этого не пережил.
Посмотрим же, как наш AI проигрывает. Запускаем бой номер 3. Противник – снова Штурмовик.
Как и в прошлый раз, враги сходятся на расстояние отравляющего выстрела, но на этот раз Штурмовик смог выстрелить первым, и получить преимущество в 1 хп (ошибка номер 1). Дальше бойцы продолжают сходиться и начинается перестрелка на арбалетах. AI поспешил, и первый снаряд выпустил прежде, чем противник оказался в зоне прицельного огня (ошибка номер 2). Он нанёс урон чуть раньше, зато Штурмовик сделал шаг вперёд и нанёс 10 урона вместо 4. В ходе дальнейшей перестрелки Штурмовик успешно убивает AI.
Выводы
Из данного эксперименты я делаю следующие выводы:
1) Тот способ создания AI, который пригоден для создания автопилота, пригоден и для создания боевого робота.
2) Иногда для того, чтобы AI достиг заданной цели, ему нужно называть более достижимую цель, а затем постепенно подменять цель на ту, которой мы хотим достичь.
3) Оптимизировать ступенчатую функцию намного тяжелее, чем гладкую.
4) 3 слоя по 11 нейронов – это достаточно для управления роботом, у которого 7 сенсоров и 6 выходнов. Обычно 33 нейронов не хватает на задачи подобной размерности.
Коды функций
Функция, симулирующая один бой:
function q = evaluateNN(input_,nn)
units=[];
%input_: AI.x, enemy.x, AI.hp, enemy.hp, enemy.strategy
units(1).x=input_(1);
units(1).hp=input_(3);
units(1).cooldown=0;
units(1).poisoned=0;
units(2).x=input_(2);
units(2).hp=input_(4);
units(2).cooldown=0;
units(2).poisoned=0;
me=1;
enemy=2;
center.me=0;
center.enemy=0;
for i=1:85
if(units(1).cooldown==0 || units(2).cooldown==0)
cooldown=[units(1).cooldown;units(2).cooldown];
[ampl,turn]=min(cooldown);
%choose
if(turn==me)
%me
answArr=fastSim(nn,[units(me).x;units(me).hp;units(me).poisoned; units(enemy).x;units(enemy).hp; units(enemy).poisoned;units(enemy).cooldown]);
[ampl, action] = max(answArr);
else
if(turn==enemy)
%enemy
action=3;
if(input_(5)==0)%Human player
units(1),units(2)
'Player2: 1: x++, 2: x--, 3: wait, 4: knife, 5: crossbow, 6: poison'
action=input('Action number:')
end;
if(input_(5)==1)%gladiator
if(abs(units(me).x-units(enemy).x)<=1)
action=4;
elseif(abs(units(me).x-units(enemy).x)<=5 && units(enemy).hp<=10)
action=5;
elseif(units(enemy).x>units(me).x)
action=2;
else
action=1;
end;
end;
if(input_(5)==2)%stormtrooper
if(abs(units(me).x-units(enemy).x)<=1)
action=4;
elseif(abs(units(me).x-units(enemy).x)<=5)
action=5;
elseif(abs(units(me).x-units(enemy).x)<=8 && units(me).poisoned==0)
action=6;
elseif(units(enemy).x>units(me).x)
action=2;
else
action=1;
end;
end;
if(input_(5)==3)%archer
if(abs(units(me).x-units(enemy).x)<=1)
action=4;
elseif(abs(units(me).x-units(enemy).x)<=8 && units(me).poisoned==0)
action=6;
elseif(abs(units(me).x-units(enemy).x)<=12)
action=5;
elseif(units(enemy).x>units(me).x)
action=2;
else
action=1;
end;
end;
if(input_(5)==4)%tower
if(abs(units(me).x-units(enemy).x)<=1)
action=4;
elseif(abs(units(me).x-units(enemy).x)<=8 && units(me).poisoned==0)
action=6;
elseif(abs(units(me).x-units(enemy).x)<=12)
action=5;
else
action=3;
end;
end;
end;
end;
%actions
%move
if(action==1)
if(turn==1)
another=2;
else
another=1;
end;
if(units(turn).x+1~=units(another).x)
units(turn).x=units(turn).x+1;
end;
units(turn).cooldown=units(turn).cooldown+2;
end;
if(action==2)
if(turn==1)
another=2;
else
another=1;
end;
if(units(turn).x-1~=units(another).x)
units(turn).x=units(turn).x-1;
end;
units(turn).cooldown=units(turn).cooldown+2;
end;
if(action==3)
%pause
units(turn).cooldown=units(turn).cooldown+1;
end;
%knife
if(action==4)
if(turn==1)
another=2;
else
another=1;
end;
if(abs(units(turn).x-units(another).x)<=1)
units(another).hp=units(another).hp-20;
end;
units(turn).cooldown=units(turn).cooldown+4;
end;
%crossbow
if(action==5)
if(turn==1)
another=2;
else
another=1;
end;
if(abs(units(turn).x-units(another).x)<=5)
%meely
units(another).hp=units(another).hp-10;
elseif(abs(units(turn).x-units(another).x)<=12)
%long-range
units(another).hp=units(another).hp-4;
end;
units(turn).cooldown=units(turn).cooldown+10;
end;
%poison
if(action==6)
if(turn==1)
another=2;
else
another=1;
end;
if(abs(units(turn).x-units(another).x)<=8)
units(another).hp=units(another).hp-2;
units(another).poisoned=1;
end;
units(turn).cooldown=units(turn).cooldown+10;
end;
else
units(1).cooldown=units(1).cooldown-1;
units(2).cooldown=units(2).cooldown-1;
end;
if(units(me).poisoned>0)
units(me).hp=units(me).hp-1;
end;
if(units(enemy).poisoned>0)
units(enemy).hp=units(enemy).hp-1;
end;
if(units(me).hp<=0)
break;
end;
if(units(me).x==0)
center.me=center.me+1;
end;
if(units(enemy).x==0)
center.enemy=center.enemy+1;
end;
if(abs(units(me).x)>=10)
units(me).hp=0;
break;
end;
if(units(enemy).hp<=0)
break;
end;
end;
q=-100-(input_(3)-units(1).hp)+1.0*(input_(4)-units(2).hp);
if(q>0)
q=0;
end;
end
Функция, проводящая серию боёв:
function q = testSeria(k)
global nn
sum_=0;
countOfPoints=0;
nnlocal=ktonn(nn,k);
arr=[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20];
%%
input=[[-3.,9.,80,80,1];[-2.,8.,10,10,2];[-4.,3.,60,60,4];[-4.,8.,20,20,3];[-2.,9.,15,15,2];[5.,-8.,100,100,4];[-5.,0.,50,50,1];[-5.,4.,80,80,2];[4.,7.,70,100,3];[7.,-6.,10,10,3];[-1.,9.,140,140,3]];
%input=[-3.,9.,80,80,0];%Player 2 is a human
sz=size(input);
for (i=1:sz(1))
val=evaluateNN(input(i,:),nnlocal);
sum_=sum_+val;
arr(i)=val;
end;
countOfPoints=sz(1);
q=(min(arr)+sum_/countOfPoints)/2 - sum(abs(k))*0.001;
end
Функция, исполняющая нейросеть:
function arr = fastSim(nn,input)
%fast simulation for fast network
sz=size(nn.LW);
sum=cell([1,sz(1)]);
LW=nn.LW;
b=nn.b;
sum{1}=nn.IW{1}*input;
arr=sum{1};
for i=1:sz(1)-1
sum{i+1}=tansig(LW{i+1,i}*(sum{i}+b{i}));
end;
arr=sum{sz(1)};
end
Функция, переводящая набор чисел в коэффициенты нейросети – нужна для оптимизации нейросети:
function nn = ktonn(nn,k)
%neuro net to array of koefficients
ksize=size(k);
if(ksize(2)==1)
k=k';
end;
bsz=size(nn.b);
counter=1;
for i=1:bsz(1)-1
sz=size(nn.b{i});
nn.b{i}=k(counter:counter+sz(1)-1)';
counter=counter+sz(1);
end;
lsz=size(nn.LW);
for i1=1:(lsz(1)-1)
x=i1+1;
y=i1;
szW=size(nn.LW{x,y});
nn.LW{x,y}=reshape(k(counter:counter+szW(1)*szW(2)-1),szW(1),szW(2));
counter=counter+szW(1)*szW(2);
end;
sz=size(nn.IW{1});
arr=k(counter:counter+sz(1)*sz(2)-1);
arr=reshape(arr,sz(1),sz(2));
nn.IW{1}=arr;
end
Main.m:
clc;
global nn
X=[[(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5)], [(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5)]];
Y=[[(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5)], [(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5)]];
nnBase=newff(X,Y,[11,11,11],{'tansig' 'tansig' 'tansig'},'trainrp');
nn.b=nnBase.b;
nn.IW=nnBase.IW;
nn.LW=nnBase.LW;
f=load('./conf.mat');
k=f.rtailor;
q=testSeria(k)Файл с конфигурацией нейросети. К сожалению, я потерял тот файл с хорошо выигрывающим AI, но этот играет не хуже.
При желании можно сыграть против AI — в этом случае надо в Test Seria раскомментировать строчку:
input=[-3.,9.,80,80,0];%Player 2 is a human
