
Когда-то давным-давно, когда деревья были большие, был такой шутер Half-Life, продолжение которого ждут до сих пор — это уже притча во языцех.
Были там такие противники как Combines (Combine Soldiers) — измененные захватчиками люди.
Во время игры можно было слышать их переговоры по радио — и я просто мечтал о такой радиостанции, которая бы сделала голос похожим на них и имела такой-же звук окончания радиопередачи.
Спустя много времени я таки решился осуществить свою мечту.
Переговоры были типа вот такого:
В то время я реально мечтал сделать, чтобы у моей радиостанции был хотя-бы такой же roger beep как в этих переговорах. Кто не знает что такое roger beep — это сигнал окончания передачи, тот, что звучит в конце каждого сообщения.
В игре тон его меняется в зависимости от солдата, вот что-то среднее:
Тогда сделать это было для меня сложно, но развитие микропроцессоров на сегодняшний день сделало не только возможным легко это повторить, но и замедлить голос, чтобы было еще более похоже на то, что было в игре.
Сердцем данной схемы стал процессор от фирмы ATMEL — ATTINY85.
И да — real time audio processing на крохотной ATTINY85 — это вполне возможно :)
Результат работы на примере голоса Геральта из Ривии
Оригинальный звук
Модифицированный звук
В живую звучит не так глухо и более четко. Тут из-за множества преобразований и перекодирования такое получилось, но общая картина, я думаю, понятна.
Можно сказать, что это все «just for fun», однако если убрать трансформацию голоса, то схема позволяет добавить roger beep любой радиостанции, если у нее есть разъем для аксессуаров типа «kenwood» (тот самый двойной разъем).
Я тестировал это на Baofeng-888s, и как раз у нее roger beep-а в принципе нет — так что возможность сделать это, или, например, скрэмблинг — вполне себе не только забава.
Как работает прошивка?
На самом деле ничего сложного там нет.
Используется низко-скоростной режим работы с периферией (через PLLCSR) — в этом случае питать ATTINY можно от 2.7 вольта и это дает частоту дискретизации около 9kHz.
Можно было использовать и высокоскоростной режим, что дало бы частоту около 18kHz, но тогда пришлось бы использовать напряжение питания от 4.5 вольт, а с этим были проблемы.
При нажатии на кнопку передачи на тангенте, генерируется прерывание и ATTINY выходит из сна, включает режим передачи на радиостанции и использует ADC на частоте примерно 8.9kHz чтобы оцифровывать голос с микрофона в циклический буфер:

При занесении очередного значения в буфер, оно миксуется с предыдущим — находится среднее, т.е. формула такая:
 .
.Это дает нам возможность переживать случай, когда старое значение еще не отдалось, а на его место уже пришло новое. А это рано или поздно случится, т.к. скорости чтения и записи — разные.
Указатели на буфер увеличиваются после каждой такой операции, когда они доходят до максимума, то сбрасываются в ноль — т.е. в начало буфера — поэтому он и зовется кольцевым.
Памяти у ATTINY не много — всего 500 байт, в данном случае под кольцевой буфер будет использоваться 450 байт, т.к. память нужна еще для переменных и стэка.
У буфера два указателя — по одному данные пишутся, по другому — читаются и коэффициент отношения этого как раз и задает скорость чтения относительно скорости записи.
При чтении данные отдаются через PWM и после сглаживающего фильтра они превращаются в звук, который уходит в микрофонный тракт радиостанции.
Кстати, через PWM получается очень неплохое качество и это можно использовать для любого места, где надо проиграть какой либо звук (музыкальные шкатулки, подарки и т.д.), причем выводов у ATTINY хватает, чтобы подключить даже SD — и тогда вообще можно хоть целые композиции играть.
Но вернемся к нашей схеме: при отпускании кнопки, ATTINY все еще удерживает режим передачи, прекращает оцифровку, и отдает через PWM оцифрованный звук roger beep-а, затем выключает режим передачи и уходит в сон, чтобы снизить потребление электроэнергии.
Звук, т.к. занимает достаточно много места — около 5 килобайт — занимает часть памяти под программу — т.к. данной памяти вполне достаточно для кода — это решает проблему с нехваткой памяти.
Что касается степени замедления или убыстрения голоса, то нужный коэффициент должен быть записан в 0 адрес EEPROM ATTINY, и, соответственно, его можно менять в пределах от 0 до 255.
Примеры значений:
30 убыстрение голоса
55 без изменений
75 замедление голоса
Схема
Само устройство будет представлять собой тангенту (или правильней — манипулятор) к радиостанции и будет с ней работать через стандартный разъем для аксессуаров «Kenwood».
Схема очень и очень простая, легко собирается «на коленке».
Модуль микрофонного усилителя заказал на Aliexpress, причем рекомендую именно такой тип модуля, который здесь на фото. Питается от 3-5в, стоимость около 2$.
Динамик требуется около 8 ом, 0.5-1 ватт.
Кнопка — любая, работающая на замыкание. Светодиод любой с возможностью работы от 3 вольт, ну, или с соответствующим резистором.
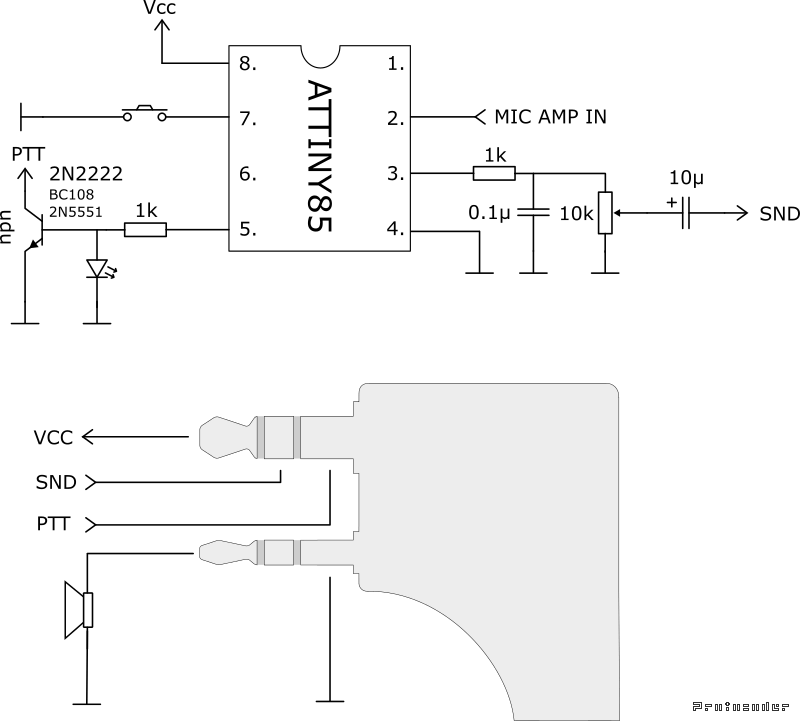
Есть одна особенность, которая не попала в эту схему — в разъеме для аксессуаров предусмотрено 5-вольтовое питание аксессуаров, но вот конкретно в Baofeng-888s что-то у китайцев сделано не так. Мало того, что там 3 вольта, так еще и при нагрузке оно падает до 0.7 вольта и, естественно, схема не работает.
Для того, чтобы это обойти, был добавлен крохотный DC-DC преобразователь с 1.2 до 3.3 вольта с Aliexpress и внешний разъем для подключения любой AA-батарейки.
Причем по-умолчанию, когда в разъем ничего не вставлено, схема будет пытаться питаться от радиостанции.
Как выглядит схема в сборе:

Виновник торжества:

Как сделать двойной штекер (KENWOOD-разъем) для радиостанции:

Два штекера 3.5 и 2.5, смотанных вместе изолентой — куда уж без нее.
Корпус
Тут особо ничего сложного нет, единственное, с чем пришлось повозиться — это с окошком в виде лямбды. Получилось достаточно криво, но чуть-чуть похоже :)
Делал дремелем, затем с лицевой стороны заклеил скотчем, а с противоположной залил клей из клеевого пистолета, в него же утопил светодиод, который загорается, когда идет передача.
Здесь еще нет разъема под внешнее питание.
Снаружи:

Внутри:
Все вместе:

Резюме
Вобщем, детскую мечту я свою исполнил и хоть она и была иррациональна — ее исполнение греет мою взрослую душу. Надеюсь кто-то испытает схожие чувства. :)
Прошивка
FUSE-биты для ATTINY85 (8Mhz, питание >= 2.7в):
0xE2 LOW
0xDD HIGH
0xFF EXTENDED
Скачать файлы прошивки
В ближайшее время постараюсь причесать и выложить исходники всего этого.
Примечание
Поскольку у моего брата не сложилось с НЛО, то я решил опубликовать на Хабре эту статью от своего имени. Когда я ее собрал — знаете — был счастлив как ребенок. И подумал что она достойна внимания хабрасообщества.
У меня она живет совместно с радиостанцией YAESU, и отлично работает, питаясь от самой станции.
Новые версии прошивки и файлы с ней связанные можно будет найти в блоге моего брата protocoder.ru.
Ну а так как я принимал непосредственное участие в разработке и сам собрал такую-же штуку — то попытаюсь ответить на любые вопросы по ней.
