Comments 41
Неплохая статья. Хотя местами расходится с фактами.
Там проблема скорее в ограничении количества таблиц, которые можно JOINуть. У Котерова был эксперимент — на ограничении 32 таблицы запрос по выборке дерева большого и сильно вложенного (уровень вложенности 8) с 32 JOINами работает (можно найти на dklab — проверял месяца три назад) примерно с той же скоростью, что и 8 JOINов (примерно с той же скоростью в данном случае означает флуктуации между запросами на уровне флуктуации скорости выполнения одного запроса)
NESTED SETS, если его попробовать (у меня ощущение, что про него пишут просто потому что он упоминается в любой статье про деревья) реально применить, годится либо для деревьев, которые никогда не будут меняться и данные в которые никогда не будут дописываться в середину дерева, либо для «кустиков» до 800 узлов суммарно. Потому как при больших (ударение на первую букву) размерах, вставка узла в середину начинает занимать около МИНУТЫ на не самом отстойном железе и внятно сконфигуренной базой. У Nested Sets имеется один единственный замечательный + — вывод дерева в правильном порядке.
Materialized Path в классическом виде хранит информацию о предках, а не порядок вывода по отношению к предкам. Если скомбинировать классический Materialized Path с Materialized Path, приведенным в этом примере, да еще написать правильную функцию сравнения того Materialized Path, в котором порядок вывода хранится, получится вполне внятное дерево, выводимое единым запросом в правильном порядке. Правда, остаются проблемы с переносом веток, но, проблемы эти решаются (т.е. перенос ветки с вложенностью 5 и 7000 потомков занимает, в среднем, около 2 секунд совместной работы PostgreSQL+PHP).
А в целом, хотелось бы в таких статьях (это вроде как уже не первая) побольше конкретики собственного опыта (я вырастил дерево такой-то вышины и такой-то ширины, и храню я это дерево там-то и там-то потому-тои потому-то)
Хотя данные в таком виде уже более приспособлены сразу для вывода, но, как видите, главный недостаток такого подхода — необходимо достоверно знать количество уровней вложенности в вашей иерархии, кроме того, чем больше иерархия, тем больше JOIN'ов — тем ниже производительность.(про JOIN и про Adjacency List).
Там проблема скорее в ограничении количества таблиц, которые можно JOINуть. У Котерова был эксперимент — на ограничении 32 таблицы запрос по выборке дерева большого и сильно вложенного (уровень вложенности 8) с 32 JOINами работает (можно найти на dklab — проверял месяца три назад) примерно с той же скоростью, что и 8 JOINов (примерно с той же скоростью в данном случае означает флуктуации между запросами на уровне флуктуации скорости выполнения одного запроса)
NESTED SETS, если его попробовать (у меня ощущение, что про него пишут просто потому что он упоминается в любой статье про деревья) реально применить, годится либо для деревьев, которые никогда не будут меняться и данные в которые никогда не будут дописываться в середину дерева, либо для «кустиков» до 800 узлов суммарно. Потому как при больших (ударение на первую букву) размерах, вставка узла в середину начинает занимать около МИНУТЫ на не самом отстойном железе и внятно сконфигуренной базой. У Nested Sets имеется один единственный замечательный + — вывод дерева в правильном порядке.
Materialized Path в классическом виде хранит информацию о предках, а не порядок вывода по отношению к предкам. Если скомбинировать классический Materialized Path с Materialized Path, приведенным в этом примере, да еще написать правильную функцию сравнения того Materialized Path, в котором порядок вывода хранится, получится вполне внятное дерево, выводимое единым запросом в правильном порядке. Правда, остаются проблемы с переносом веток, но, проблемы эти решаются (т.е. перенос ветки с вложенностью 5 и 7000 потомков занимает, в среднем, около 2 секунд совместной работы PostgreSQL+PHP).
А в целом, хотелось бы в таких статьях (это вроде как уже не первая) побольше конкретики собственного опыта (я вырастил дерево такой-то вышины и такой-то ширины, и храню я это дерево там-то и там-то потому-тои потому-то)
«Потому как при больших (ударение на первую букву) размерах, вставка узла в середину начинает занимать около МИНУТЫ на не самом отстойном железе и внятно сконфигуренной базой.»
Вставка в дерево в ~700 узлов занимала от 2 до 4 секунд до переделки запроса на batch (bulk) update. После такой переделки изменение дерева в ~1300 (это ведь больше 800?) узлов никогда не занимала больше 1-1.2 секунды. Oracle, p4 несколько лет назад (т.е. максимум, что там было — HT, никаких Quad Core). От работы с nested sets на PostgreSQL впечатления аналогичные.
Я затрудняюсь представить себе, что нужно сделать c подобными запросами, чтобы обновление заняло минуту.
Вставка в дерево в ~700 узлов занимала от 2 до 4 секунд до переделки запроса на batch (bulk) update. После такой переделки изменение дерева в ~1300 (это ведь больше 800?) узлов никогда не занимала больше 1-1.2 секунды. Oracle, p4 несколько лет назад (т.е. максимум, что там было — HT, никаких Quad Core). От работы с nested sets на PostgreSQL впечатления аналогичные.
Я затрудняюсь представить себе, что нужно сделать c подобными запросами, чтобы обновление заняло минуту.
Еще раз. Есть дерево. ветвистое. глубокое. Суммарно — около 100000 узлов, вложенность что-то порядка 15. Начинаем формировать дерево Nested Sets из имеющегося Adjacency List. Поскольку работа с деревом предполагает, в том числе, копирование, перемещение веток, а также вставку узлов в середину, данные перед вставкой берутся в сравнительно произвольном порядке. До 500 узлов тормозов не заметно, после начинаются нарастающие тормоза. Начиная с 700 узлов среднее время выполнения вставки составляет около минуты на узел. После вставки 1300 узлов процесс остановлен.
Опыт проводился на тестовом сервере (Athlon 2500XP) и на PostgreSQL 8.3. Для чистоты эксперимента был проведен раза три, с вариациями по порядку выборки исходного дерева. Существенных изменений в производительности не замечалось.
Железка, когда еще была боевым сервером, держала сайты суммарной посещаемостью около 800000 хитов в сутки + почту к этим сайтам и испытывала проблемы разве что от кривоватых рук тогдашнего админа (сволочь ротацию логов как-то совсем криво делал).
А с самими запросами ничего не делалось. просто вставлялся узел, потом апдейтилось дерево.
Опыт проводился на тестовом сервере (Athlon 2500XP) и на PostgreSQL 8.3. Для чистоты эксперимента был проведен раза три, с вариациями по порядку выборки исходного дерева. Существенных изменений в производительности не замечалось.
Железка, когда еще была боевым сервером, держала сайты суммарной посещаемостью около 800000 хитов в сутки + почту к этим сайтам и испытывала проблемы разве что от кривоватых рук тогдашнего админа (сволочь ротацию логов как-то совсем криво делал).
А с самими запросами ничего не делалось. просто вставлялся узел, потом апдейтилось дерево.
Туше. Но, простите, но из Ваших слов о nested set (и более ранних) никак не следовало, что в дереве 100000 узлов.
А с самими запросами ничего не делалось. просто вставлялся узел, потом апдейтилось дерево
Сложно что-то предлагать, не зная деталей, но я бы начал с упрощения операции вставки. Никто же не заставляет значения leftBound и rightBound быть строго последовательными — создавайте их с шагом хоть в 10000, тогда вставка и перемещение узлов будут приводить к пересчёту дерева гораздо реже (хотя «балансировку» время от времени выполнять придётся, конечно), новые узлы будут просто укладываться в резерв родительского диапазона.
Кстати, не поделитесь — что это за предметная область такая, что надо постоянно перемещать участки иерархии и добавлять новые кусты больших размеров?
А с самими запросами ничего не делалось. просто вставлялся узел, потом апдейтилось дерево
Сложно что-то предлагать, не зная деталей, но я бы начал с упрощения операции вставки. Никто же не заставляет значения leftBound и rightBound быть строго последовательными — создавайте их с шагом хоть в 10000, тогда вставка и перемещение узлов будут приводить к пересчёту дерева гораздо реже (хотя «балансировку» время от времени выполнять придётся, конечно), новые узлы будут просто укладываться в резерв родительского диапазона.
Кстати, не поделитесь — что это за предметная область такая, что надо постоянно перемещать участки иерархии и добавлять новые кусты больших размеров?
Так когда мы пытались сформировать дерево в nested sets, оно там никогда выше 1300 — 1400 узлов не дорастало))). мы скрипт отрубали.
делать границы с шагом, разумеется, можно, но не универсально — а мы пытались выработать некий универсальный подход, который позволил бы нам работать с большими деревьями быстро и с минимальными затратами.
А предметная область удручающе банальна — web-дизайн. Мы используем дерево в качестве универсального хранилища данных для сайта/группы сайтов. Там, не то, чтобы постоянно, но регулярно возникают задачи по копированию/перемещению/вставке в середину иногда одиночных узлов, а иногда весьма ветвистых веток. Фактически, любое обновление сайта означает вставку одиночного узла, а если на сайте болтается какой-нить мультитоварный каталог посерьезнее — возникает необходимость делать вставки участков иерархии. Nested Sets для решения наших задач не подошло совсем — слишком много в общем случае объектов на update. Причем количество этих объектов, вообще говоря, не контролируется.
Это как с рекурсией. Рекурсия по дереву сверху вниз есть абсолютное зло, поскольку, находясь наверху, мы не можем оценить количество рекурсивных вызовов. С другой строны, рекурсия снизу вверх, при определенных обстоятельствах, вполне допустима — поскольку количество вызовов ограничено вложенностью начального узла.
делать границы с шагом, разумеется, можно, но не универсально — а мы пытались выработать некий универсальный подход, который позволил бы нам работать с большими деревьями быстро и с минимальными затратами.
А предметная область удручающе банальна — web-дизайн. Мы используем дерево в качестве универсального хранилища данных для сайта/группы сайтов. Там, не то, чтобы постоянно, но регулярно возникают задачи по копированию/перемещению/вставке в середину иногда одиночных узлов, а иногда весьма ветвистых веток. Фактически, любое обновление сайта означает вставку одиночного узла, а если на сайте болтается какой-нить мультитоварный каталог посерьезнее — возникает необходимость делать вставки участков иерархии. Nested Sets для решения наших задач не подошло совсем — слишком много в общем случае объектов на update. Причем количество этих объектов, вообще говоря, не контролируется.
Это как с рекурсией. Рекурсия по дереву сверху вниз есть абсолютное зло, поскольку, находясь наверху, мы не можем оценить количество рекурсивных вызовов. С другой строны, рекурсия снизу вверх, при определенных обстоятельствах, вполне допустима — поскольку количество вызовов ограничено вложенностью начального узла.
Согласен.
Кроме того, автор передергивает:
тут нужно было бы продолжить: «… для любой модели кроме классики смежных вершин (которая, на практике и является верным выбором фактически всегда).».
Аналогично-с.
Кроме того, автор передергивает:
наиболее неприятной в данном алгоритме будет операция вставки узла в середину уже существующей структуры (между другими узлами), т.к. это повлечет изменение всех путей в нижележащих узлах. Хотя, справедливости ради, следует сказать, что такая операция окажется нетривиальной для любой модели хранения данных.
тут нужно было бы продолжить: «… для любой модели кроме классики смежных вершин (которая, на практике и является верным выбором фактически всегда).».
Другая тяжелая операция — это перенос одной ветки в другую.
Аналогично-с.
Эх, как я и сам это люблю. :) Единственный недостаток — так редко удается с ним работать!
А я люблю MS SQL — там есть конструкция WITH которая сводит всю эту статью к одному такому же короткому запросу и даже лучше чем в Оракле :-)
Пользуюсь ей уже два года, работаю с ней постоянно, рад что могу делать простые таблицы (id, parentid) и не городить таких сложных велосипедов как описано в этой статье.
Пользуюсь ей уже два года, работаю с ней постоянно, рад что могу делать простые таблицы (id, parentid) и не городить таких сложных велосипедов как описано в этой статье.
Спасибо. Очень познавательно.
Мелкие замечания. Как раз изучаю теорию графов, и вот — случай блеснуть знаниями =).
Не совсем понятно, почему автор выкинул из графа именно нижнее ребро (т. е. почему автор решил выбрать корнем дерева именно вершину 1) — получается совершенно другой граф. Речь, видимо, идет о покрывающих деревьях графа, то с тем же успехом можно было выкинуть любое другое ребро — получили бы три разных покрывающих дерева.
Если же автор выбрал его произвольно — то об этом стоит написать.
Далее, связи между вершинами правильнее писать через отображения:
Г(1) = {2,3};
Г(2) = {1,3};
Г(3) = {1,2}.
По теме, собственно первый комментатор высказался исчерпывающе.
Не совсем понятно, почему автор выкинул из графа именно нижнее ребро (т. е. почему автор решил выбрать корнем дерева именно вершину 1) — получается совершенно другой граф. Речь, видимо, идет о покрывающих деревьях графа, то с тем же успехом можно было выкинуть любое другое ребро — получили бы три разных покрывающих дерева.
Если же автор выбрал его произвольно — то об этом стоит написать.
Далее, связи между вершинами правильнее писать через отображения:
Г(1) = {2,3};
Г(2) = {1,3};
Г(3) = {1,2}.
По теме, собственно первый комментатор высказался исчерпывающе.
потому что дерево и граф — все-таки немного разны понятия. Графы в WEB (а иначе откуда берется мускуль, в отличие от деревьев, не юзаются). Для графа нужна совсем другая структура данных. по собственному опыту — мерзотная.
> потому что дерево и граф — все-таки немного разны понятия
Дерево есть неориентированный связный граф без циклов. А не «немного разные понятия».
> графы в WEB (а иначе откуда берется мускуль), в отличие от деревьев, не юзаются.
*FIXED*
Откуда такая безапелляционность?
> Для графа нужна совсем другая структура данных.
Ты просто специализируешь конкретную структуру на данном виде графа.
> по собственному опыту — мерзотная.
Структура графа совершенно спокойно хранится в виде матриц смежности и инцедентности — идеальная форма для обработки компьютером.
Дерево есть неориентированный связный граф без циклов. А не «немного разные понятия».
> графы в WEB (а иначе откуда берется мускуль), в отличие от деревьев, не юзаются.
*FIXED*
Откуда такая безапелляционность?
> Для графа нужна совсем другая структура данных.
Ты просто специализируешь конкретную структуру на данном виде графа.
> по собственному опыту — мерзотная.
Структура графа совершенно спокойно хранится в виде матриц смежности и инцедентности — идеальная форма для обработки компьютером.
деревья — это подмножество графов
графы юзаются в программировании с самого начала — блок-схемы например :)
Еще UML, BPEL, правда для их описания используется XML, суть которого — дерево :)
графы юзаются в программировании с самого начала — блок-схемы например :)
Еще UML, BPEL, правда для их описания используется XML, суть которого — дерево :)
Статья очень неплохая.
Вы немного не правы насчет «смеси» NS + материализованный путь.
Если «заваливаться» в сторону NS — то выиграша никакого, но если завалиться в сторону МП — то получится очень быстрая смесь ;)
Получается почти идеальный алгоритм :) Почему почти? Появляется избыточность данных. Но совсем небольшая.
Очень легко получать родителей, детей. Выборка без всяких join. Никаких liкe% concat и т.п.
Многие коммерческие продукты пользуются этим алгоритмом. Видел у IBM например.
Вы немного не правы насчет «смеси» NS + материализованный путь.
Если «заваливаться» в сторону NS — то выиграша никакого, но если завалиться в сторону МП — то получится очень быстрая смесь ;)
Получается почти идеальный алгоритм :) Почему почти? Появляется избыточность данных. Но совсем небольшая.
Очень легко получать родителей, детей. Выборка без всяких join. Никаких liкe% concat и т.п.
Многие коммерческие продукты пользуются этим алгоритмом. Видел у IBM например.
Точнее я бы сказал смесь AL+NS+МП :)
Да я согласен с вами. Достаточно немного «прокачать» MP и всё будет тоже довольно быстро — например автор позволил себе в NS закешировать левел — ради бога, кешируйте его и в MP (почему нет?) — это сильно развяжет вам руки! Можно простыми запросами дёргать определённые уровни, детей и т.д.
все про это говорят, но нигде нет конкретного описания подобного решения. Как скрестить, откуда что взять, как и где обновлять.
NESTED SETS: Провел небольшой тест по производительности, вставка в пустое дерево по 1000 записей:
0001-1000 — 3.5275 сек.
1001-2000 — 6.2751 сек.
2001-3000 — 8.4156 сек.
3001-4000 — 9.9535 сек.
4001-5000 — 14.0197 сек.
Тест проводился на хостинге (nichost.ru тариф 301), собственная база MySQL, адаптер БД Zend_DB с включенным профилировщиком.
0001-1000 — 3.5275 сек.
1001-2000 — 6.2751 сек.
2001-3000 — 8.4156 сек.
3001-4000 — 9.9535 сек.
4001-5000 — 14.0197 сек.
Тест проводился на хостинге (nichost.ru тариф 301), собственная база MySQL, адаптер БД Zend_DB с включенным профилировщиком.
А еще есть — ordpath, хитрая схема нумерации, опитизированная и под поиск и под вставку новых узлов.
Отличная статья!
(Правда графы зря были освещены в этой статье. ИМХО, они не нужны здесь.)
— Народ, с каким фреймворком вы используете Doctrine?
И совсем не в тему, НО очень интересует, кто как крестил Zend Auth, Zend Acl и Doctrine в Zend контролерах.
(Правда графы зря были освещены в этой статье. ИМХО, они не нужны здесь.)
— Народ, с каким фреймворком вы используете Doctrine?
И совсем не в тему, НО очень интересует, кто как крестил Zend Auth, Zend Acl и Doctrine в Zend контролерах.
Я крестил — mikhailstadnik.com/tuning-zf-with-doctrine
Acl и Auth дальше сделать достаточно просто через написание собственных адаптеров и плагинов. Работет как часы.
Acl и Auth дальше сделать достаточно просто через написание собственных адаптеров и плагинов. Работет как часы.
Я крестил немного по другому, но результат тот же. В этом проблем нет. Все отлично работает.
Проблема заключается в грамотном использовании Acl и Auth. Как крестить контроллеры на работу с Acl, может поделитесь решением?
Не хочется изобретать велосипед.
Проблема заключается в грамотном использовании Acl и Auth. Как крестить контроллеры на работу с Acl, может поделитесь решением?
Не хочется изобретать велосипед.
Ах. вы об этом… Ну я не думаю, что могу предложить какое-либо стандартное решение. Все зависит от специфики приложения. Мой случай скорее будет частным нежели общим, поэтому как готовое решение давать не буду, но в двух словах скажу.
У нас на уровне БД структура прав доступа, в которой один из типов объектов на права — это экшены контроллеров, соответственно у нас есть Acl плагин который умеет их обрабатывать. Но для общего случая это довольно грубое решение. Мы-то и хотели все контролировать руками (фактически, пока я не пропишу права на экшн его никто не сможет выполнить)…
P.S. Подумаю еще на досуге над вашей задачей может че-то путнее в голову придет…
У нас на уровне БД структура прав доступа, в которой один из типов объектов на права — это экшены контроллеров, соответственно у нас есть Acl плагин который умеет их обрабатывать. Но для общего случая это довольно грубое решение. Мы-то и хотели все контролировать руками (фактически, пока я не пропишу права на экшн его никто не сможет выполнить)…
P.S. Подумаю еще на досуге над вашей задачей может че-то путнее в голову придет…
Юзаю с symfony, очень доволен.
> SELECT name, strfind( path, '.') AS level
> FROM mp_tree
> WHERE path LIKE '1.1%'; /* Выбираем всю ветку 'VEGETABLES' */;
Мне кажется, что в данном случае будут выбраны в том числе и ветки: 1.10, 1.11.2 и т.п. Т.е. нужно указывать разделитель:
WHERE path LIKE '1.1.%'; /* Выбираем всю ветку 'VEGETABLES' */;
И дальше уже вопрос нужна ли сама ветка 1.1; если да, то придется прописывать разделитель во все пути самым последним символом.
> FROM mp_tree
> WHERE path LIKE '1.1%'; /* Выбираем всю ветку 'VEGETABLES' */;
Мне кажется, что в данном случае будут выбраны в том числе и ветки: 1.10, 1.11.2 и т.п. Т.е. нужно указывать разделитель:
WHERE path LIKE '1.1.%'; /* Выбираем всю ветку 'VEGETABLES' */;
И дальше уже вопрос нужна ли сама ветка 1.1; если да, то придется прописывать разделитель во все пути самым последним символом.
Пробую разобраться с древовидной структурой в Propel, при вставке/изменении записи проблем нет, а вот когда пытаюсь сделать root node происходят странности. Кто нибудь работал с sfPropelActAsNestedSetBehaviorPlugin в админке. Хотелось бы понять как норм построить дерево.
Хочу добавить эту информацию в документацию по Doctrine на русском языке, перевод которой я делаю. Если автор не возражает.
А как быть, если одно дерево является частью других разных нескольких деревьев?
Думаю, нужен пример того что именно необходимо реализовать, чтобы ответить.
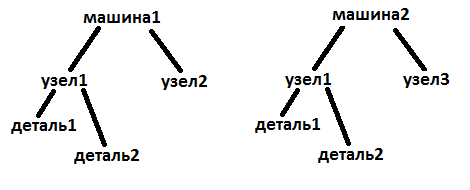
«узел1» — это дерево, которое является частью дерева «машина1» и «машина2».
Думаю тут нет ничего сверхестественного, если делать Adjacency List. Просто создаем таблицу для каждой из «сущностей»:
Теперь заполним эти таблицы данными из представленной схемы:
Теперь нужно просто создать связи между «сущностями», для этого создаются таблицы связей. Сначала свяжем Машины и Узлы:
Не плохо получилось, добавим связь узлов и деталей.
Прошу обратить внимание, что тут второе число это id детали, а третье id узла. Можно было сделать привычнее и расположить вторым узел, но так разнообразнее :)
Вообщем, получается крайне ловкое решение, и в том плане, что достаточно легко можно его модернизировать. К примеру, если понадобится связь Машин и Деталей, минуя Узлы, просто добавляем таблицу связей для них, при этом с остальными таблицами ничего не придется делать.
CREATE TABLE cars (
`id` BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
`name` VARCHAR(50) NOT NULL
) TYPE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE nodes (
`id` BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
`name` VARCHAR(50) NOT NULL
) TYPE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE details (
`id` BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
`name` VARCHAR(50) NOT NULL
) TYPE=InnoDB DEFAULT CHARSET=utf8;
Теперь заполним эти таблицы данными из представленной схемы:
INSERT INTO cars VALUES
(1, 'Машина1'),
(2, 'Машина2');
INSERT INTO nodes VALUES
(1, 'Узел1'),
(2, 'Узел2'),
(3, 'Узел3');
INSERT INTO details VALUES
(1, 'Деталь1'),
(2, 'Деталь2');
Теперь нужно просто создать связи между «сущностями», для этого создаются таблицы связей. Сначала свяжем Машины и Узлы:
CREATE TABLE car_node (
`id` BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
`car_id` BIGINT NOT NULL,
`node_id` BIGINT NOT NULL
) TYPE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO car_node VALUES
(1, 1, 1),
(2, 1, 2),
(1, 2, 1),
(2, 2, 3);
Не плохо получилось, добавим связь узлов и деталей.
CREATE TABLE node_detail (
`id` BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
`detail_id` BIGINT NOT NULL,
`node_id` BIGINT NOT NULL
) TYPE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO node_detail VALUES
(1, 1, 1),
(2, 2, 1);
Прошу обратить внимание, что тут второе число это id детали, а третье id узла. Можно было сделать привычнее и расположить вторым узел, но так разнообразнее :)
Вообщем, получается крайне ловкое решение, и в том плане, что достаточно легко можно его модернизировать. К примеру, если понадобится связь Машин и Деталей, минуя Узлы, просто добавляем таблицу связей для них, при этом с остальными таблицами ничего не придется делать.
Sign up to leave a comment.
Иерархические структуры данных и Doctrine