Кажется, у меня появилась привычка писать о мощных машинах, где множество ядер простаивают из-за неправильных блокировок. Так что… Да. Опять про это.
Эта история особенно впечатляет. В самом деле, как часто у вас один поток несколько секунд крутится в цикле из семи команд, удерживая блокировку, которая останавливает работу 63 других процессоров? Это просто восхитительно, в каком-то ужасном смысле.
Вопреки распространённому мнению, у меня на самом деле нет машины с 64 логическими процессорами, и я никогда не видел этой конкретной проблемы. Но с ней столкнулся мой друг,этот ботан зацепил меня он попросил о помощи, и я решил, что проблема достаточно интересная. Он выслал трассировку ETW с достаточным количеством информации, чтобы коллективный разум в твиттере быстро решил проблему.
Жалоба у друга была достаточно простая: он собирал билд с помощью ninja. Обычно ninja отлично справляется с ростом нагрузки, постоянно поддерживая n+2 процессов, чтобы избежать простоя. Но здесь использование CPU в первые 17 секунд сборки выглядело следующим образом:

Если очень внимательно присмотреться (шутка), то видна тонкая грань, где общая загрузка CPU за пару секунд падает со 100% до 0%. Всего за полсекунды загрузка снижается с 64 до двух или трёх потоков. Вот увеличенный фрагмент одного из таких падений — по горизонтальной оси отмечены секунды:
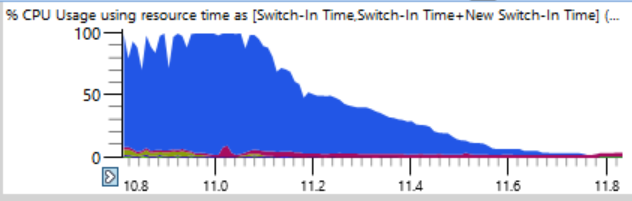
Первой мыслью было, что ninja не может достаточно быстро создавать процессы. Я видел такое много раз, обычно из-за вмешательства антивирусного ПО. Но когда я отсортировал графики по времени окончания, то обнаружил, что во время таких падений не завершались никакие процессы, поэтому ninja не виноват.
Для выяснения причины простоя идеально подходит таблица CPU Usage (Precise). Там хранятся логи всех переключений контекста, в том числе точные записи о каждом запуске потока, включая место и время ожидания.
Хитрость в том, что в простое нет ничего плохого. Проблема возникает в том случае, когда мы действительно хотим, чтобы поток выполнял работу, а вместо этого он простаивает. Поэтому нужно выбрать определённые моменты простоя.
При анализе важно понимать, что переключение контекста происходит, когда поток возобновляет работу. Если мы посмотрим на те места, когда загрузка процессора начинает падать, то ничего не найдем. Вместо этого нужно сосредоточиться на том, когда система снова начала работать. Эта фаза трассировки ещё более драматичная. В то время как спад нагрузки CPU занимает полсекунды, обратный процесс от одного используемого потока до полной загрузки занимает всего двенадцать миллисекунд! График ниже довольно сильно увеличен, и всё же переход от простаивания к нагрузке — почти вертикальная линия:

Я увеличил масштаб до двенадцати миллисекунд и обнаружил 500 переключений контекста, здесь потребуется тщательный анализ.
В таблице переключения контекста много столбцов, которые я задокументировал здесь. Когда процесс зависает, для поиска причины я делаю группировку по новым процессам, новым потокам, новым стекам потоков и т. д. (обсуждается здесь), но это не работает на сотне остановленных процессов. Если бы я изучал какой-то один неправильный процесс, то видно, что он был подготовлен предыдущим процессом, который подготовлен предыдущим, и я бы сканировал длинную цепочку, чтобы найти первое звено, которое (предположительно) в течение длительного времени удерживает важную блокировку.
Итак, я попробовал в программе другое расположение столбцов:
Это даёт упорядоченный по времени список переключений контекста с пометкой, кто кого готовил и как долго ждали процессы, готовые к работе.
Оказалось, что этого достаточно. Таблица ниже говорит сама за себя, если знать, как её читать. Первые несколько переключателей контекста не представляют интереса, потому что время ожидания нового процесса (Time Since Last) довольно мало, но на выделенной строке (#4) начинается интересное:

В этой строке говорится, что System (4) подготовил cl.ехе (3032), который ждал 3,368 секунды. В следующей строке говорится, что менее чем через 0,1 мс cl.ехе (3032) подготовил cl.exe (16232), который ждал 3,367 секунды. И так далее.
Несколько переключателей контекста, как в строке #7, не входят в цепочку ожидания, а просто отражают другую работу в системе, но в целом цепочка растягивается на много десятков элементов.
Это означает, что все эти процессы ожидают освобождения одной и той же блокировки. Когда процесс System (4) освобождает блокировку (после удержания в течение 3,368 секунд!) ожидающие процессы, в свою очередь, захватывают её, делают свою небольшую работу и передают блокировку дальше. В очереди ожидания около сотни процессов, что показывает степень влияния единственной блокировки.
Небольшое изучение Ready Thread Stacks показало, что большинство ожиданий идёт от KernelBase.dllWriteFile. Я попросил WPA отобразить вызывающие объекты этой функции, с группировкой. Там можно увидеть, что за 12 миллисекунд этого катарсиса 174 потока выходят из ожидания WriteFile, и они ждали в среднем 1,184 секунды:

174 потока ждут WriteFile, среднее время ожидания 1,184 секунды
Это удивительное отставание, и на самом деле даже не весь масштаб проблемы, потому что освобождения той же блокировки ожидают многие потоки из других функций, таких как KernelBase.dll!GetQueuedCompletionStatus.
В этот момент я знал, что прогресс сборки остановился из-за того, что все процессы компилятора и другие ожидали WriteFile, поскольку System (4) удерживал блокировку. Ещё один столбец Ready Thread Id показал, что блокировку освободил поток 3276 в системном процессе.
Во время всех «подвисаний» сборки поток 3276 был загружен на 100%, поэтому ясно, что он выполнял некоторую работу на CPU, удерживая блокировку. Чтобы выяснить, куда тратится процессорное время, посмотрим график CPU Usage (Sampled) для потока 3276. Данные об использовании CPU оказались удивительно чёткими. Практически всё время занимает работа одной функции ntoskrnl.exe!RtlFindNextForwardRunClear (в колонке с цифрами указано количество образцов):

Стек вызовов ведёт к ntoskrnl.exe!RtlFindNextForwardRunClear
Просмотр стека потоков Readying Thread Id подтвердил, что NtfsCheckpointVolume освободил блокировку через 3,368 с:

Стек вызовов из NtfsCheckpointVolume в ExReleaseResourceLite
В этот момент мне показалось, что пришло время использовать богатые познания моих фоловеров в твиттере, поэтому я опубликовал этот вопрос и показал полный стек вызовов. Твиты с такими вопросами могут быть очень эффективными, если предоставить достаточно информации.
В этом случае очень быстро появился правильный ответ от Кейтлин Гэдд, наряду с множеством других замечательных предложений. Она отключила функцию восстановления системы — и внезапно сборка пошла в два-три раза быстрее!
Блокировка выполнения по всей системе в течение 3+ секунд довольно впечатляет, но ситуация впечатляет ещё сильнее, если в таблицу CPU Usage (Sampled) добавить столбец Address и отсортировать по нему. Он показывает, куда именно в RtlFindNextForwardRunClear попадают образцы — и 99% из них приходится на одну инструкцию!

Я взял у себя файлы ntoskrnl.exe и ntkrnlmp.pdb (той же версии, что у друга) и запустил
Мы видим, что инструкция на ...4657 входит в цикл из семи инструкций, которые встречаются и в других образцах. Справа указано количество таких образцов:
В качестве упражнения для читателя оставим интерпретацию количества образцов на суперскалярном процессоре с внеочередным исполнением инструкций, хотя в этой статье можно найти некоторые хорошие идеи. В данном случае у нас 32-ядерный AMD Ryzen Threadripper 2990WX. Видимо, процессорная функция Micro-Up Fusion с выполнением пяти инструкций за раз на самом деле позволяет каждый цикл завершать на jne, поскольку инструкция после самой дорогой инструкции попадает в большинство прерываний выборки.
Так и получается, что машина с 64 логическими процессорами стопорится циклом из семи команд в системном процессе, удерживая жизненно важную блокировку NTFS, что исправляется путём отключения восстановления системы.
Непонятно, почему этот код плохо себя вёл на этой конкретной машине. Предполагаю, это как-то связано с распределением данных на почти пустом диске 2 ТБ. Когда восстановление системы включили обратно, проблема тоже вернулась, но уже не такая суровая. Может, есть некая патология для дисков с огромными фрагментами пустого пространства?
Другой фоловер в твиттере упомянул баг Volume Shadow Copy из Windows 7, который допускает выполнение за время O(n^2). Эту ошибку якобы исправили в Windows 8, но, возможно, она сохранилась в какой-то форме. Мои трассировки стека чётко показывают, что VspUpperFindNextForwardRunClearLimited (поиск используемого бита в этой 16-мегабайтной области) вызывает VspUpperFindNextForwardRunClear (ищет следующий используемый бит в любом месте, но не возвращает его, если тот находится за пределами указанной области). Конечно, это вызывает некое чувство дежавю. Как я недавно рассказывал, O(n^2) — слабое место плохо масштабируемых алгоритмов. Тут совпадают два фактора: такой код достаточно быстрый, чтобы попасть в продакшн, но достаточно медленный, чтобы этот продакшн уронить.
Были сообщения, что подобная проблема возникает при массированном удалении файлов, но у нас трассировка не показывает много удалений, так что проблема, видимо, не в этом.
В завершение продублирую общесистемный график загрузки CPU из начала статьи, но в этот раз с указанием использования CPU проблемным процессом System (зелёным цветом внизу). В такой картинке проблема совершенно очевидна. Системный процесс технически виден на верхнем графике, но на таком масштабе его легко упустить.

Хотя на графике проблема хорошо видна, на самом деле это ничего не доказывает. Как говорится, корреляция — это не причинная связь. Только анализ событий переключения контекста показывает, что именно этот поток удерживает критическую блокировку — и тогда можно быть уверенным, что мы нашли фактическую причину, а не просто случайную корреляцию.
Как обычно, это расследование я завершаю призывом лучше именовать потоки. У системного процесса десятки потоков, многие из которых имеют специальное назначение, и ни у одного нет названия. Самым загруженным системным потоком в этой трассировке был MiZeroPageThread. Я неоднократно погружался в его стек, и каждый раз вспоминал, что он не представляет интереса. Компилятор VC++ тоже не именует свои потоки. Чтобы проименовать потоки, не требуется много времени, и это реально полезно. Просто дайте названия. Это просто. Chromium даже включает в себя инструмент для перечисления названий потоков в процессе.
Если кто-то из команды NTFS в Microsoft хочет поговорить на эту тему, дайте знать, а я могу связать вас с автором оригинального отчёта и предоставить трассировку ETW.
Эта история особенно впечатляет. В самом деле, как часто у вас один поток несколько секунд крутится в цикле из семи команд, удерживая блокировку, которая останавливает работу 63 других процессоров? Это просто восхитительно, в каком-то ужасном смысле.
Вопреки распространённому мнению, у меня на самом деле нет машины с 64 логическими процессорами, и я никогда не видел этой конкретной проблемы. Но с ней столкнулся мой друг,
Жалоба у друга была достаточно простая: он собирал билд с помощью ninja. Обычно ninja отлично справляется с ростом нагрузки, постоянно поддерживая n+2 процессов, чтобы избежать простоя. Но здесь использование CPU в первые 17 секунд сборки выглядело следующим образом:
Если очень внимательно присмотреться (шутка), то видна тонкая грань, где общая загрузка CPU за пару секунд падает со 100% до 0%. Всего за полсекунды загрузка снижается с 64 до двух или трёх потоков. Вот увеличенный фрагмент одного из таких падений — по горизонтальной оси отмечены секунды:
Первой мыслью было, что ninja не может достаточно быстро создавать процессы. Я видел такое много раз, обычно из-за вмешательства антивирусного ПО. Но когда я отсортировал графики по времени окончания, то обнаружил, что во время таких падений не завершались никакие процессы, поэтому ninja не виноват.
Для выяснения причины простоя идеально подходит таблица CPU Usage (Precise). Там хранятся логи всех переключений контекста, в том числе точные записи о каждом запуске потока, включая место и время ожидания.
Хитрость в том, что в простое нет ничего плохого. Проблема возникает в том случае, когда мы действительно хотим, чтобы поток выполнял работу, а вместо этого он простаивает. Поэтому нужно выбрать определённые моменты простоя.
При анализе важно понимать, что переключение контекста происходит, когда поток возобновляет работу. Если мы посмотрим на те места, когда загрузка процессора начинает падать, то ничего не найдем. Вместо этого нужно сосредоточиться на том, когда система снова начала работать. Эта фаза трассировки ещё более драматичная. В то время как спад нагрузки CPU занимает полсекунды, обратный процесс от одного используемого потока до полной загрузки занимает всего двенадцать миллисекунд! График ниже довольно сильно увеличен, и всё же переход от простаивания к нагрузке — почти вертикальная линия:
Я увеличил масштаб до двенадцати миллисекунд и обнаружил 500 переключений контекста, здесь потребуется тщательный анализ.
В таблице переключения контекста много столбцов, которые я задокументировал здесь. Когда процесс зависает, для поиска причины я делаю группировку по новым процессам, новым потокам, новым стекам потоков и т. д. (обсуждается здесь), но это не работает на сотне остановленных процессов. Если бы я изучал какой-то один неправильный процесс, то видно, что он был подготовлен предыдущим процессом, который подготовлен предыдущим, и я бы сканировал длинную цепочку, чтобы найти первое звено, которое (предположительно) в течение длительного времени удерживает важную блокировку.
Итак, я попробовал в программе другое расположение столбцов:
- Switch-In Time (когда произошло переключение контекста)
- Readying Process (кто освободил блокировку после ожидания)
- New Process (кто начал работать)
- Time Since Last (как долго ждал новый процесс)
Это даёт упорядоченный по времени список переключений контекста с пометкой, кто кого готовил и как долго ждали процессы, готовые к работе.
Оказалось, что этого достаточно. Таблица ниже говорит сама за себя, если знать, как её читать. Первые несколько переключателей контекста не представляют интереса, потому что время ожидания нового процесса (Time Since Last) довольно мало, но на выделенной строке (#4) начинается интересное:
В этой строке говорится, что System (4) подготовил cl.ехе (3032), который ждал 3,368 секунды. В следующей строке говорится, что менее чем через 0,1 мс cl.ехе (3032) подготовил cl.exe (16232), который ждал 3,367 секунды. И так далее.
Несколько переключателей контекста, как в строке #7, не входят в цепочку ожидания, а просто отражают другую работу в системе, но в целом цепочка растягивается на много десятков элементов.
Это означает, что все эти процессы ожидают освобождения одной и той же блокировки. Когда процесс System (4) освобождает блокировку (после удержания в течение 3,368 секунд!) ожидающие процессы, в свою очередь, захватывают её, делают свою небольшую работу и передают блокировку дальше. В очереди ожидания около сотни процессов, что показывает степень влияния единственной блокировки.
Небольшое изучение Ready Thread Stacks показало, что большинство ожиданий идёт от KernelBase.dllWriteFile. Я попросил WPA отобразить вызывающие объекты этой функции, с группировкой. Там можно увидеть, что за 12 миллисекунд этого катарсиса 174 потока выходят из ожидания WriteFile, и они ждали в среднем 1,184 секунды:
174 потока ждут WriteFile, среднее время ожидания 1,184 секунды
Это удивительное отставание, и на самом деле даже не весь масштаб проблемы, потому что освобождения той же блокировки ожидают многие потоки из других функций, таких как KernelBase.dll!GetQueuedCompletionStatus.
Что делает System (4)
В этот момент я знал, что прогресс сборки остановился из-за того, что все процессы компилятора и другие ожидали WriteFile, поскольку System (4) удерживал блокировку. Ещё один столбец Ready Thread Id показал, что блокировку освободил поток 3276 в системном процессе.
Во время всех «подвисаний» сборки поток 3276 был загружен на 100%, поэтому ясно, что он выполнял некоторую работу на CPU, удерживая блокировку. Чтобы выяснить, куда тратится процессорное время, посмотрим график CPU Usage (Sampled) для потока 3276. Данные об использовании CPU оказались удивительно чёткими. Практически всё время занимает работа одной функции ntoskrnl.exe!RtlFindNextForwardRunClear (в колонке с цифрами указано количество образцов):
Стек вызовов ведёт к ntoskrnl.exe!RtlFindNextForwardRunClear
Просмотр стека потоков Readying Thread Id подтвердил, что NtfsCheckpointVolume освободил блокировку через 3,368 с:
Стек вызовов из NtfsCheckpointVolume в ExReleaseResourceLite
В этот момент мне показалось, что пришло время использовать богатые познания моих фоловеров в твиттере, поэтому я опубликовал этот вопрос и показал полный стек вызовов. Твиты с такими вопросами могут быть очень эффективными, если предоставить достаточно информации.
В этом случае очень быстро появился правильный ответ от Кейтлин Гэдд, наряду с множеством других замечательных предложений. Она отключила функцию восстановления системы — и внезапно сборка пошла в два-три раза быстрее!
Но подождите, дальше ещё лучше
Блокировка выполнения по всей системе в течение 3+ секунд довольно впечатляет, но ситуация впечатляет ещё сильнее, если в таблицу CPU Usage (Sampled) добавить столбец Address и отсортировать по нему. Он показывает, куда именно в RtlFindNextForwardRunClear попадают образцы — и 99% из них приходится на одну инструкцию!
Я взял у себя файлы ntoskrnl.exe и ntkrnlmp.pdb (той же версии, что у друга) и запустил
dumpbin /disasm для просмотра интересующей функции в ассемблере. Первые цифры адресов отличаются, потому что код перемещается при загрузке, но последние четыре значения hex совпадают (они не изменяются после ASLR):RtlFindNextForwardRunClear: … 14006464F: 4C 3B C3 cmp r8,rbx 140064652: 73 0F jae 0000000140064663 140064654: 41 39 28 cmp dword ptr [r8],ebp 140064657: 75 0A jne 0000000140064663 140064659: 49 83 C0 04 add r8,4 14006465D: 41 83 C1 20 add r9d,20h 140064661: EB EC jmp 000000014006464F …
Мы видим, что инструкция на ...4657 входит в цикл из семи инструкций, которые встречаются и в других образцах. Справа указано количество таких образцов:
RtlFindNextForwardRunClear: … 14006464F: 4C 3B C3 cmp r8,rbx 4 140064652: 73 0F jae 0000000140064663 41 140064654: 41 39 28 cmp dword ptr [r8],ebp 140064657: 75 0A jne 0000000140064663 7498 140064659: 49 83 C0 04 add r8,4 2 14006465D: 41 83 C1 20 add r9d,20h 1 140064661: EB EC jmp 000000014006464F 1 …
В качестве упражнения для читателя оставим интерпретацию количества образцов на суперскалярном процессоре с внеочередным исполнением инструкций, хотя в этой статье можно найти некоторые хорошие идеи. В данном случае у нас 32-ядерный AMD Ryzen Threadripper 2990WX. Видимо, процессорная функция Micro-Up Fusion с выполнением пяти инструкций за раз на самом деле позволяет каждый цикл завершать на jne, поскольку инструкция после самой дорогой инструкции попадает в большинство прерываний выборки.
Так и получается, что машина с 64 логическими процессорами стопорится циклом из семи команд в системном процессе, удерживая жизненно важную блокировку NTFS, что исправляется путём отключения восстановления системы.
Coda
Непонятно, почему этот код плохо себя вёл на этой конкретной машине. Предполагаю, это как-то связано с распределением данных на почти пустом диске 2 ТБ. Когда восстановление системы включили обратно, проблема тоже вернулась, но уже не такая суровая. Может, есть некая патология для дисков с огромными фрагментами пустого пространства?
Другой фоловер в твиттере упомянул баг Volume Shadow Copy из Windows 7, который допускает выполнение за время O(n^2). Эту ошибку якобы исправили в Windows 8, но, возможно, она сохранилась в какой-то форме. Мои трассировки стека чётко показывают, что VspUpperFindNextForwardRunClearLimited (поиск используемого бита в этой 16-мегабайтной области) вызывает VspUpperFindNextForwardRunClear (ищет следующий используемый бит в любом месте, но не возвращает его, если тот находится за пределами указанной области). Конечно, это вызывает некое чувство дежавю. Как я недавно рассказывал, O(n^2) — слабое место плохо масштабируемых алгоритмов. Тут совпадают два фактора: такой код достаточно быстрый, чтобы попасть в продакшн, но достаточно медленный, чтобы этот продакшн уронить.
Были сообщения, что подобная проблема возникает при массированном удалении файлов, но у нас трассировка не показывает много удалений, так что проблема, видимо, не в этом.
В завершение продублирую общесистемный график загрузки CPU из начала статьи, но в этот раз с указанием использования CPU проблемным процессом System (зелёным цветом внизу). В такой картинке проблема совершенно очевидна. Системный процесс технически виден на верхнем графике, но на таком масштабе его легко упустить.
Хотя на графике проблема хорошо видна, на самом деле это ничего не доказывает. Как говорится, корреляция — это не причинная связь. Только анализ событий переключения контекста показывает, что именно этот поток удерживает критическую блокировку — и тогда можно быть уверенным, что мы нашли фактическую причину, а не просто случайную корреляцию.
Запросы
Как обычно, это расследование я завершаю призывом лучше именовать потоки. У системного процесса десятки потоков, многие из которых имеют специальное назначение, и ни у одного нет названия. Самым загруженным системным потоком в этой трассировке был MiZeroPageThread. Я неоднократно погружался в его стек, и каждый раз вспоминал, что он не представляет интереса. Компилятор VC++ тоже не именует свои потоки. Чтобы проименовать потоки, не требуется много времени, и это реально полезно. Просто дайте названия. Это просто. Chromium даже включает в себя инструмент для перечисления названий потоков в процессе.
Если кто-то из команды NTFS в Microsoft хочет поговорить на эту тему, дайте знать, а я могу связать вас с автором оригинального отчёта и предоставить трассировку ETW.
Ссылки
- Оригинальный тред в твиттере
- Анонс поста в твиттере
- Обсуждение на Hacker News
- Обсуждение на Reddit
- Возможно, релевантная тирада о Windows/NTFS
