Существует класс приложений реального времени, для которых тяжело предсказать потребности в распределении памяти во время выполнения статически. В этот класс входят, например, встраиваемые реализации стеков некоторых коммуникационных протоколов, где поведение и распределение ресурсов определяется отчасти активностью других агентов в сети. Классический подход в таких случаях заключается в использовании блочных менеджеров памяти, выделяющих фрагменты фиксированного размера (как это сделано, например, в LwIP). Этот подход накладывает нежелательные функциональные и качественные ограничения на реализацию. В этой заметке я предлагаю точку зрения, что традиционные (не блочные) аллокаторы незаслуженно обделены вниманием разработчиков систем реального времени, делюсь соображениями по релевантным вопросам, жалуюсь на жизнь, и предлагаю улучшить положение дел.
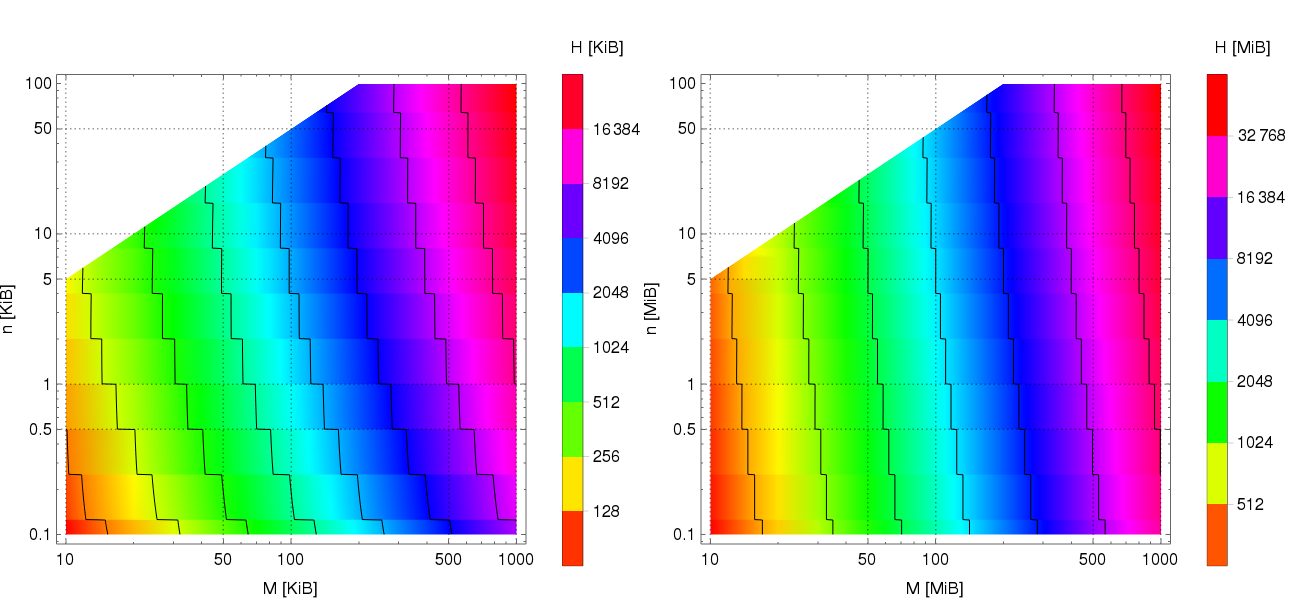
 как функция от пиковой потребности приложения в динамической памяти (M) и максимального размера выделяемого фрагмента (n)")
(КДПВ – см. аннотацию к диаграмме в конце)
Неочевидность свойств алгоритмов динамического распределения памяти породила настораживающую тенденцию к лёгкому искажению действительности в документации некоторых ОСРВ, причём не последнего пошиба. Например, раздел об управлении памятью FreeRTOS обходит стороною класс аллокаторов постоянной вычислительной сложности O(1), заставляя неискушённого коллегу принять, что O(n) есть теоретический потолок. Аналогичные артефакты находятся в документации к ChibiOS (1, 2). Мы, разумеется, не станем подозревать разработчиков столь выдающихся продуктов в незнании матчасти; скорее, спишем это на свойственный людям банальный недосмотр. Приложения реального времени редко полагаются на динамическое распределение во время выполнения, так что множество затронутых здесь невелико.
Знакомому со спецификой систем реального времени читателю не нужно объяснять, что первоочередное значение для них имеют характеристики не среднего, а худшего случая, что радикально отличает их от систем общего назначения (примером последней будет та, при помощи которой вы сейчас читаете этот текст). Для прочих читателей приведу пример: если некий алгоритм имеет асимптотическую сложность O(log n) в подавляющем большинстве случаев, но раз в тысячу лет иногда выпадает случай O(n), то интерес для анализа представляет лишь последний.
Порядком вычислительной сложности дело не ограничивается. Ресурсный потолок по памяти, очевидно, имеет критическое значение для встраиваемых систем, где количество доступных мегабайт можно пересчитать пальцами одной руки. Поставщики же ОСРВ имеют наклонности к заимствованию оптимизированных на средний случай алгоритмов из продуктов, не рассчитанных на реальное время и встраиваемые приложения. Подтверждающим примером будет реализация аллокатора в NuttX, где используется стратегия поиска наилучшего совпадения (best fit), чья пониженная склонность к фрагментации в общем случае даётся ценою крайне пессимистичного её прогноза для худшего случая. Аналогичные замечания можно сделать в адрес упомянутых ранее конкурентов.
Недостаток внимания со стороны вендоров ОСРВ к теоретической стороне вопроса порождает положительную обратную связь, где неточности в документации и технически неоптимальные реализации действительно вынуждают пользователей отказываться от их использования, что снижает интерес, и, как следствие, оставляет осложнения без внимания.
Ваш покорный слуга недаром увяз в этой проблеме. Работая над реализацией встраиваемого сетевого стека для одного протокола реального времени, я обнаружил, что замена используемого на тот момент традиционного блочного менеджера памяти на обычный аллокатор фрагментов произвольного размера не только радикально упрощает API и реализацию, но и улучшает асимптотическую сложность внутренних процедур стека. Последнее обусловлено, среди прочего, заменой фрагментированных буферов из цепочек блоков на непрерывные фрагменты памяти:
// Список фрагментов на блочном аллокаторе: struct FragmentedBuffer { struct FragmentedBuffer* next; uint8_t data[]; }; // ...превращается в: uint8_t* data;
На второй день углубления в релевантные материалы, черенок моего сознания наткнулся на анализ алгоритмов Buddy Allocator, Half-Fit, и Two-Level Segregated Fit (TLSF). Все они представляют собою детерминированные аллокаторы постоянной вычислительной сложности O(1) (для Buddy Allocator мы делаем допущение, что объём памяти постоянен, в противном случае оценка будет иной). Почтенные господа J. Herter и J. Robson подвергают оба ресурсных вопроса – как времени, так и памяти – детальному рассмотрению в диссертации “Timing-Predictable Memory Allocation In Hard Real-Time Systems” и статье “Worst case fragmentation of first fit and best fit storage allocation strategies”, соответственно.
Даже малознакомый с теорией динамического распределения памяти читатель найдёт обоснование постоянства вычислительной сложности приведённых алгоритмов тривиальным. Гораздо больший интерес здесь представляет фрагментация. Насколько я могу видеть, многие мои коллеги ошибочно подозревают, что динамические аллокаторы неизбежно приходят в состояние катастрофической фрагментации (где выделение памяти невозможно из-за высокого дробления свободных участков) за конечное время. Подробный разбор вопроса с доказательством обратного можно найти на страницах 26–33 диссертации многоуважаемого Хертера, здесь же я лишь оставлю финальный вывод, что предел размера кучи H, при котором катастрофическая фрагментация недостижима, для лучших из приведённых алгоритмов определён как:

Где M – пиковая потребность приложения в динамической памяти, n – размер наибольшей аллокации.
Здесь уместно вернуться к началу и бросить ещё камней в огород поставщиков ОСРВ. Как я упомянул, в некоторых продуктах встречаются реализации алгоритмов управления памятью, чья стратегия размещения предусматривает выбор свободного фрагмента минимально возможного размера. Эта стратегия хорошо показывает себя в среднем случае, но в особых условиях деградирует до теоретического предела H = M (n — 2), уничтожая надежду на её уместность во встраиваемых системах.
Для меня было очевидным, что множество задач реального времени, где разумное применение хорошо охарактеризованных (предсказуемых) алгоритмов выделения памяти является оправданным, не исчерпывается моим стеком. Контраст между этим осознанием и недостаточным вниманием сообщества разработчиков встраиваемых систем к детерминированным аллокаторам, усугублённый также сомнительными дискуссиями на StackOverflow, побудил меня спасать дело самостоятельно, и я сделал свой собственный аллокатор. Он чрезвычайно компактен (500 строк на C99/C11), его процедуры выделения и освобождения памяти имеют постоянную вычислительную сложность, и предельный уровень фрагментации хорошо охарактеризован.
Вот он: https://github.com/pavel-kirienko/o1heap.
Приведённая выше модель худшего случая фрагментации потребовала дополнения, потому что её общая форма не уделяет внимания собственной потребности аллокатора в памяти для хранения метаданных. Уточнённая модель, построенная с учётом специфики моей реализации, доступна в документации, здесь её не привожу по причине малой теоретической ценности. Вместо этого призываю осмотреть иллюстрацию в начале текста; её содержимое учитывает конкретику моей реализации, и оно таково:
- Левая диаграмма: размер кучи H [KiB] от пиковой потребности приложения в памяти M [KiB] и наибольшей аллокации n [KiB] при минимальном размере аллокации 16 байт.
- Правая диаграмма: аналогично, но единицы измерения MiB.
Если величины H кажутся чрезмерными, это неспроста, ведь понятия верхнего предела и худшего случая не эквивалентны. Задача поиска огибающей худшего случая включает в себя минимизацию разрыва между теоретическим пределом и практически достижимым наихудшим состоянием. В нашем случае это конкретизируется в минимизацию разрыва между значением H, предсказанным нашей моделью, и реальным пиковым случаем фрагментации, который система может встретить на практике. Я надеялся подобраться к проблеме уменьшения H при сохранении гарантированных свойств алгоритма при помощи симуляций с систематическим перебором возможных состояний, но был вынужден отложить эту затею по причине отсутствия времени. Однако, вовлечённый в тему человек понимает высокую практическую значимость этой доработки. Если среди читателей найдутся достаточно мотивированные коллеги (Embox?), я бы с готовностью ввязался в коллаборацию по этому вопросу.
Другой важный вопрос заключается в исправлении текущего положения дел в открытых системах. Я вяло потыкал метафорической палочкой одного из разработчиков NuttX по этому поводу, и почерпнул, что вопрос имеет низкий приоритет: "I considered porting TLSF at one point, but overall it's low on my list of NuttX improvements I'd explore if I actually had time". Есть куда стремиться.

{kind=link}