Предыстория
Недавно в рамках учебной деятельности мне понадобилось использовать старый добрый генетический алгоритм в целях поиска минимума и максимума функции от двух переменных. Однако, к моему удивлению, на просторах интернета не нашлось подобной реализации на питоне, а в википедии в статье по генетическому алгоритму именно этот раздел не освещен.

И поэтому я решил написать свой небольшой пакет на Python с наглядной визуализацией алгоритма, по которой будет удобно настраивать этот алгоритм и искать тонкости выбранной модели.
В этой небольшой статье я хотел бы поделиться процессом, наблюдениями и итогами.
Принцип работы алгоритма
Я не стану рассказывать о глобальном принципе работы генетических алгоритмов, но если вы ещё не слышали о таком, то ознакомиться с ним вы можете в википедии.
На данный момент в пакете реализован только один ГА, который параметризуется входными данными через простую гуишку. Расскажу кратко о выбранных генетических функциях и основных алгоритмических решениях.
Однохромосомная особь несёт в каждом своем гене информацию о соответствующей координате х или у. Популяция определяется множеством особей, однако популяция сегментируется по 4 особи. Данное решение, конечно же, обусловлено попыткой избежать сходимость к локальному оптимуму, так как стоит задача о поиске глобального экстремума. Такое разбиение, как показала практика, во многих случаях не дает доминировать одному генотипу во всей популяции, а, наоборот, придает «эволюции» бóльшую динамику. Для каждой такой части популяции применяется следующий алгоритм:
- Селекция происходит схоже с метод ранжирования. Выбирается 3 особи с наилучшим показателями фитнесс-функции (т.е. производится сортировка особей в порядке возрастания/убывания заданной пользователем функции, которая и выступает в роли функции приспособления).
- Далее применяется функция скрещивания таким образом, что новое поколение (а точнее новый сегмент популяции в 4 особи) получает 2 пары немутировавших генов от особи с лучшим показанием фитнесс-функции и по паре мутировавших генов от двух других особей. Подробнее о составлении функции мутации будет написано в следующем параграфе.
Принцип работы селекции, скрещивания и мутации наглядно выглядит так (в поколении N хромосомы особей уже отсортированы в нужном порядке, а маленький черный квадрат означает мутацию):

Первичные тесты и наблюдения
Итак, протестируем данный алгоритм на двух простых примерах:
Тест 1


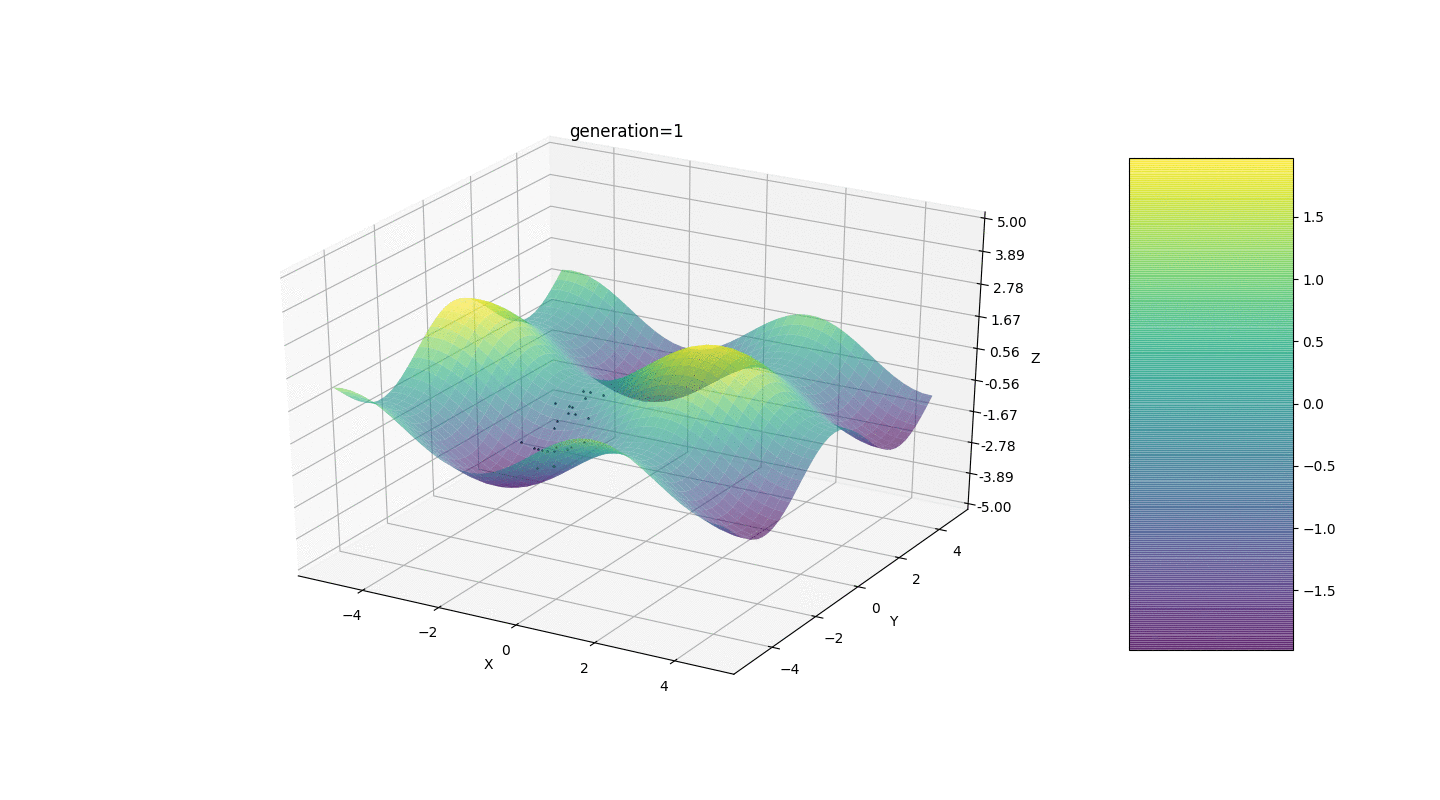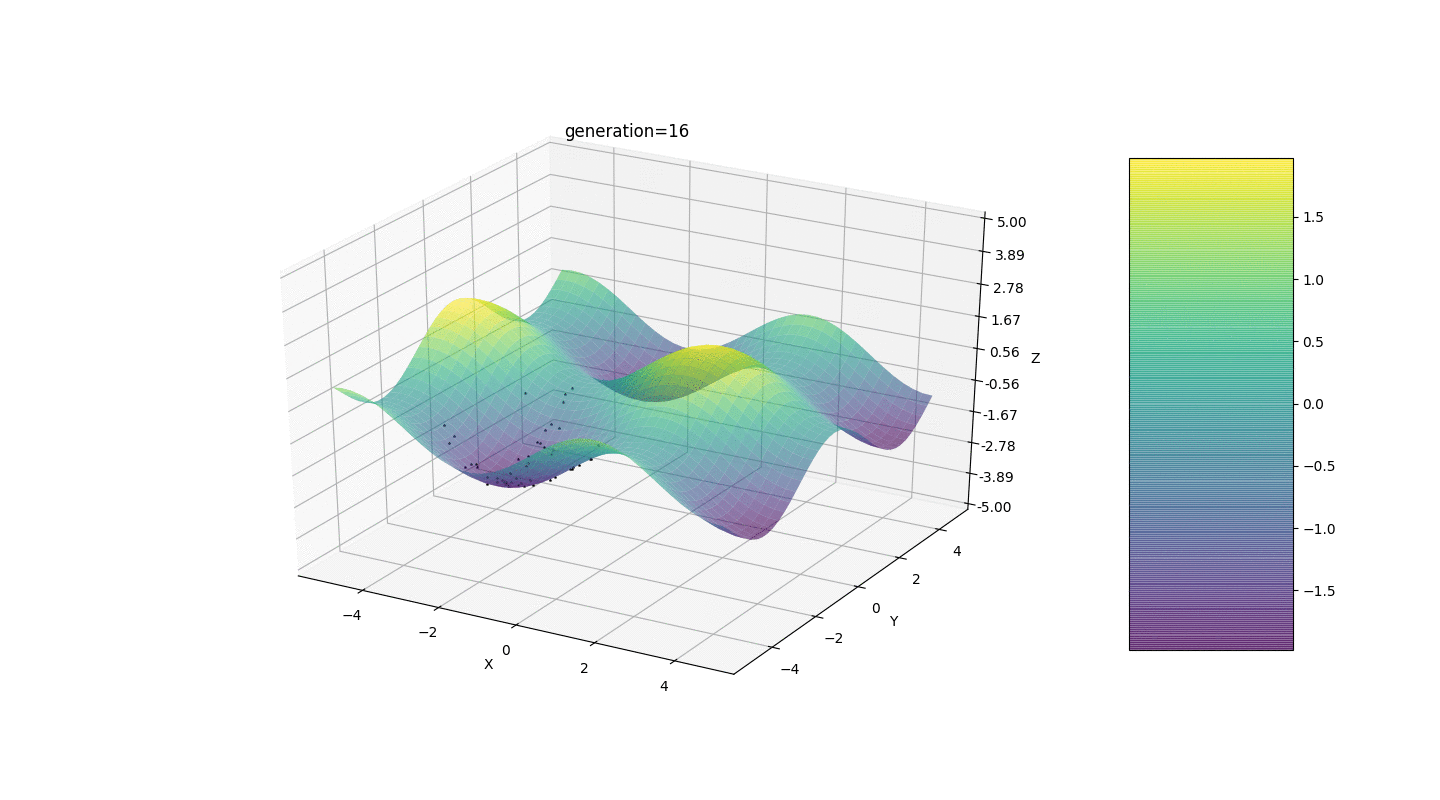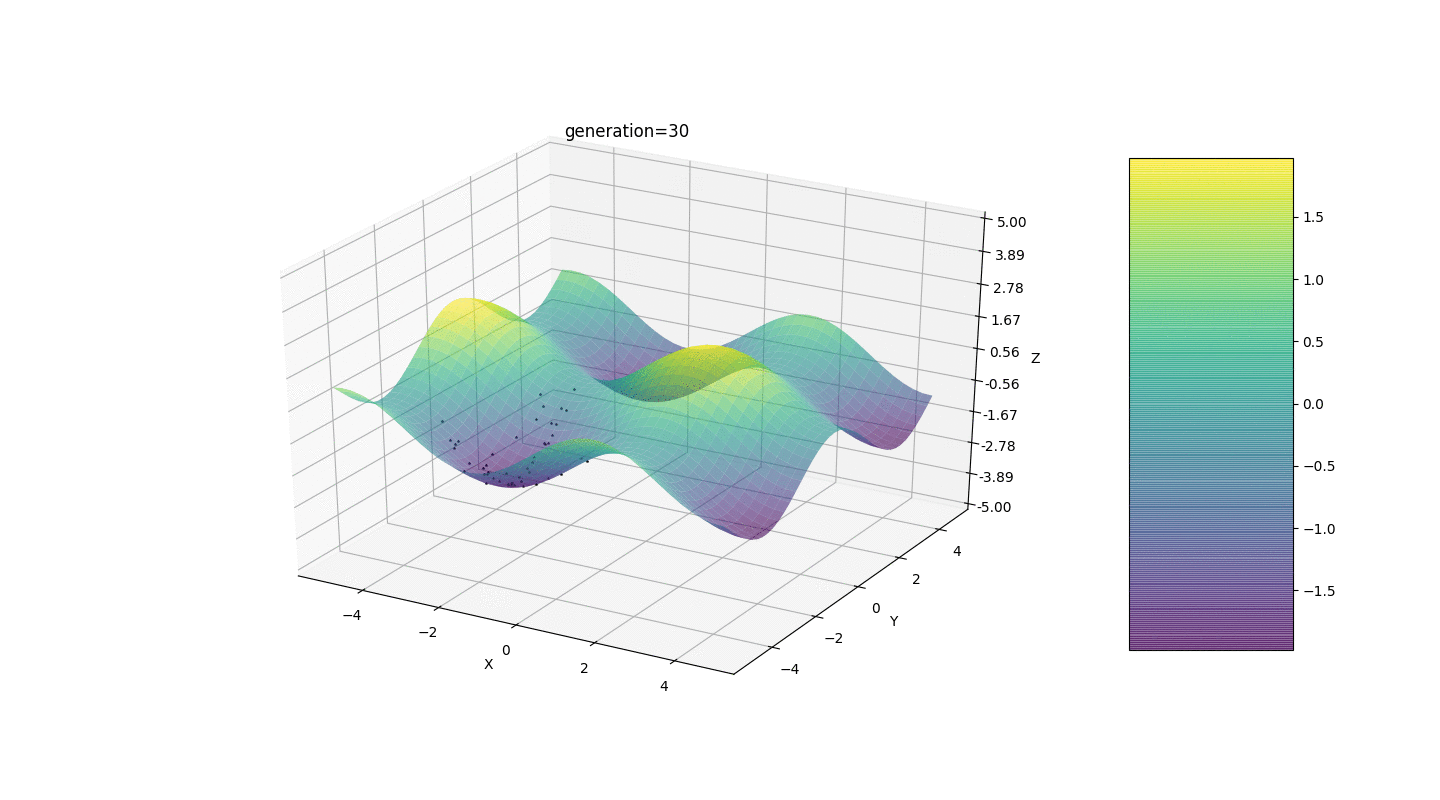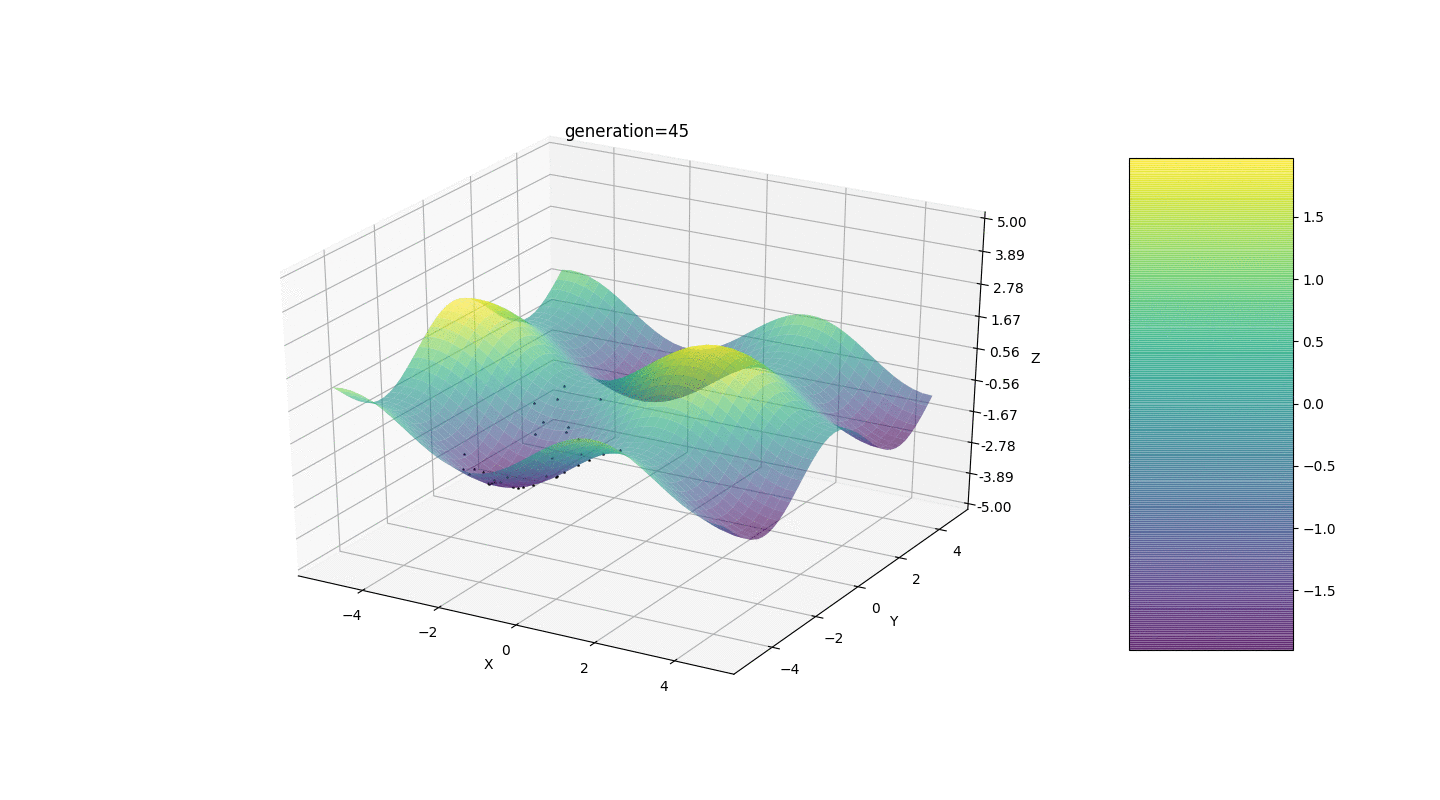
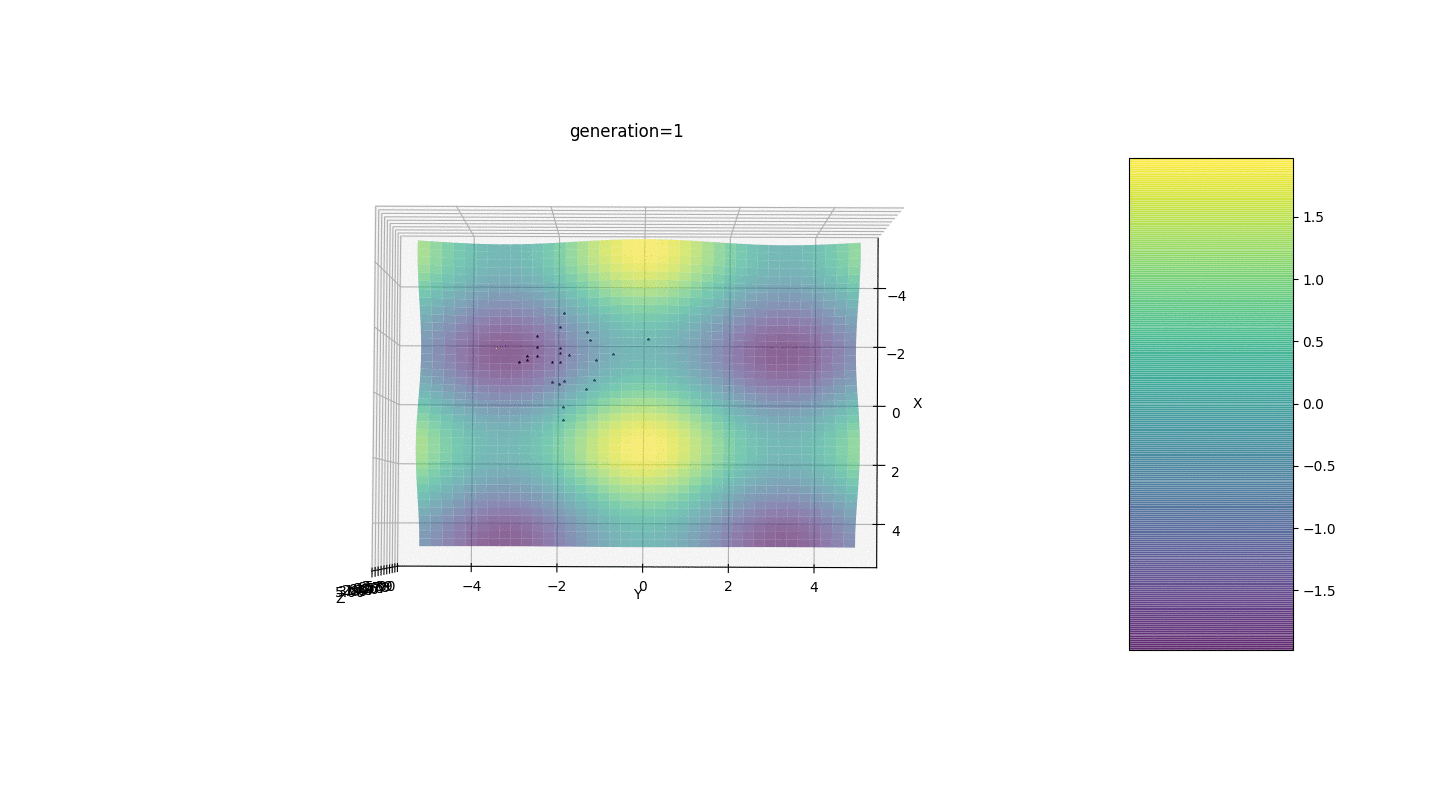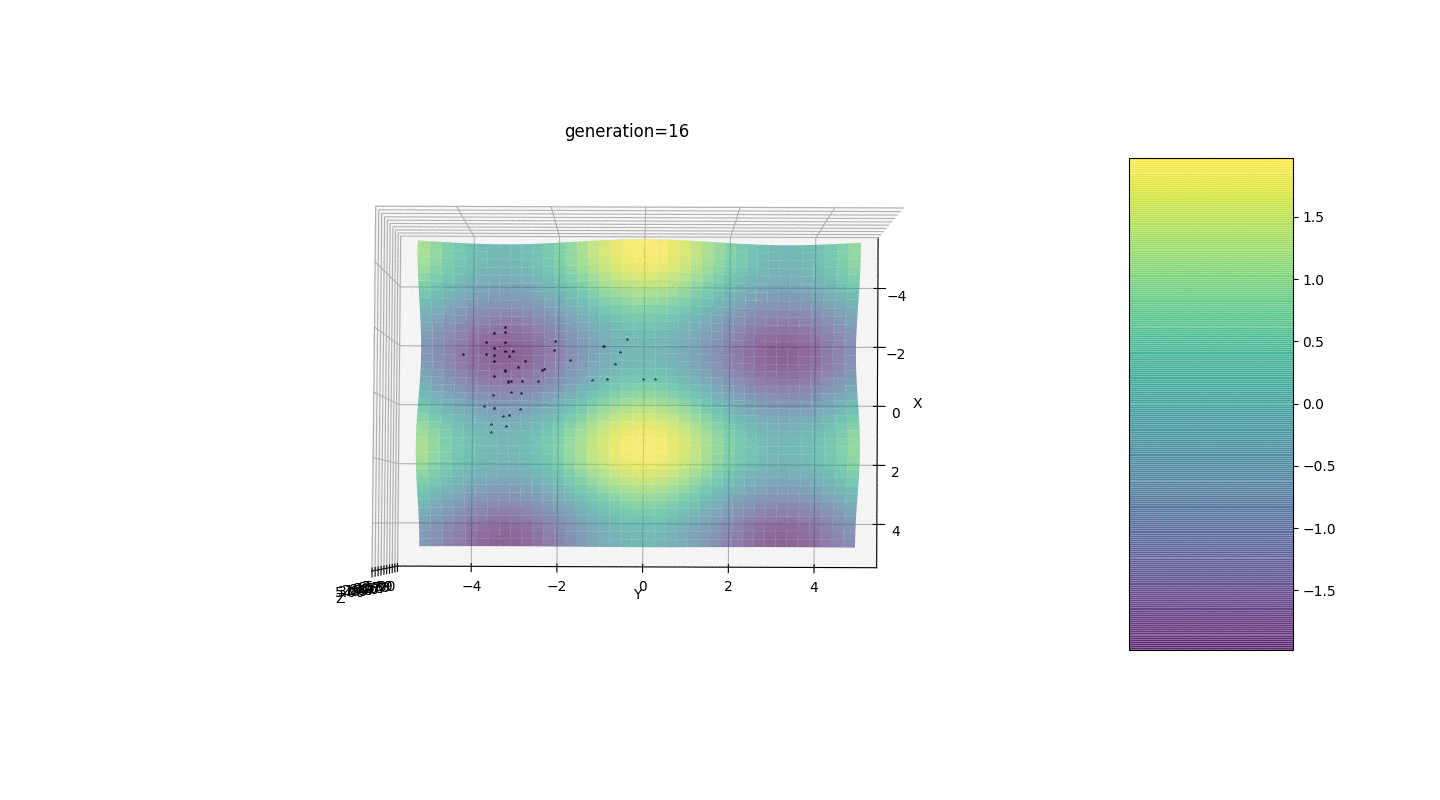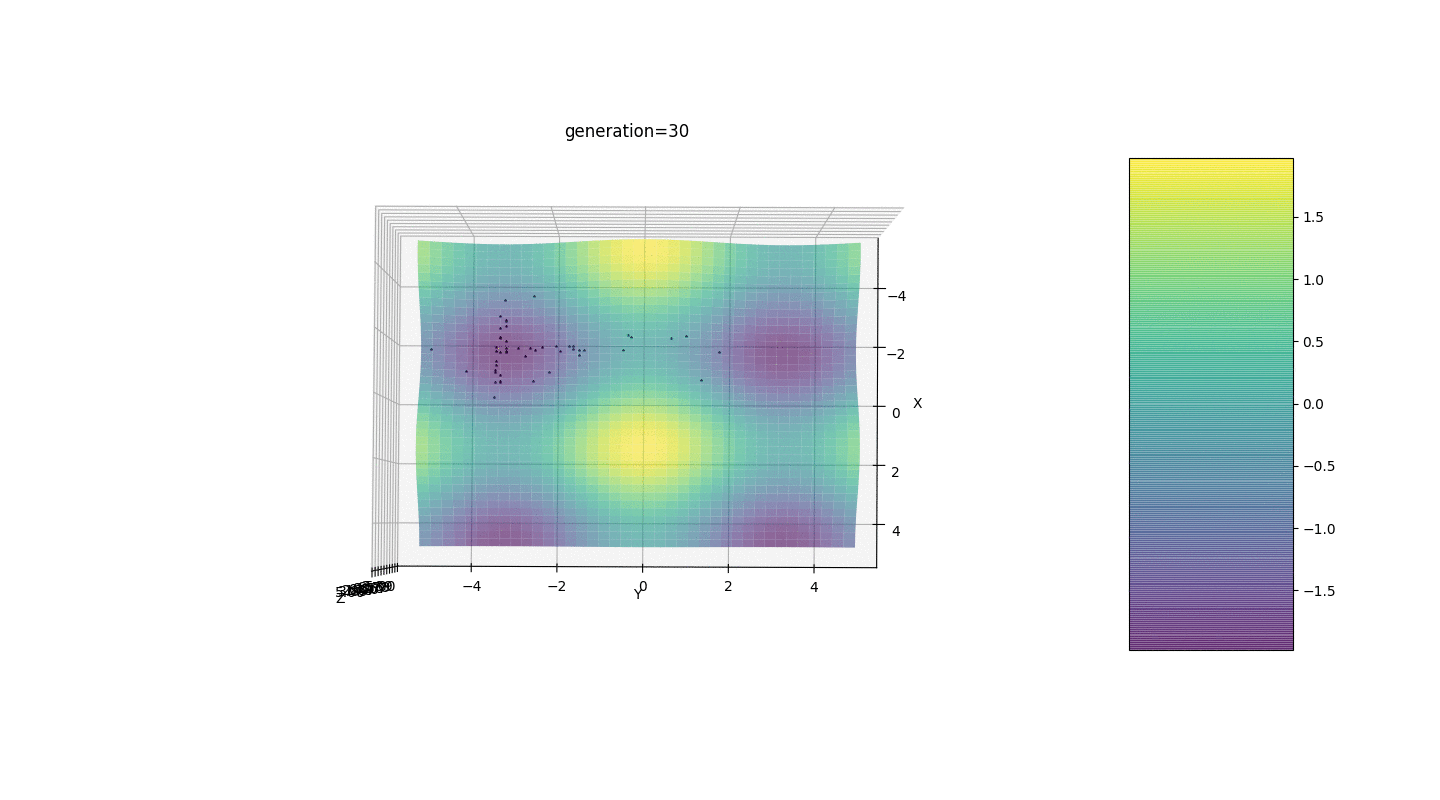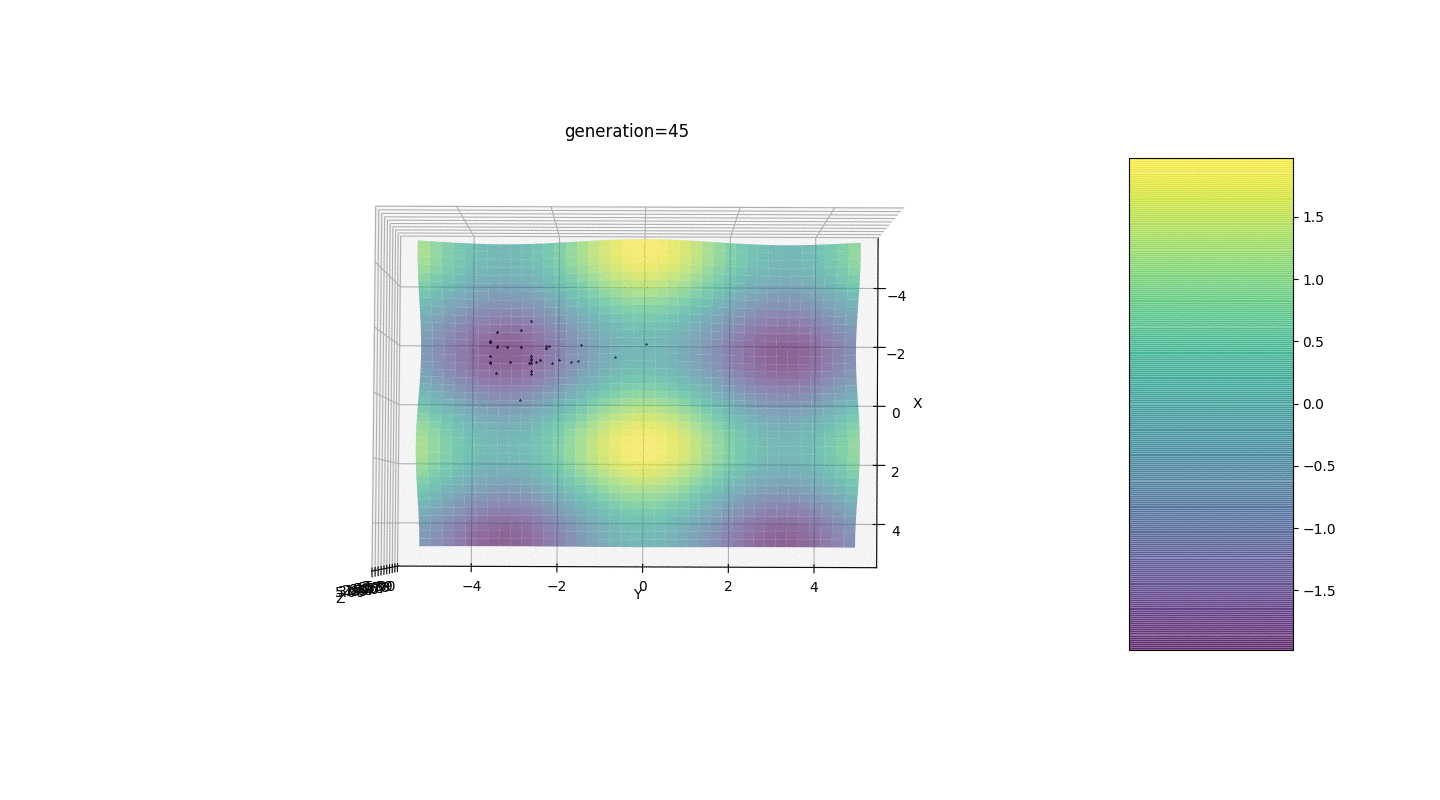

Тест 2



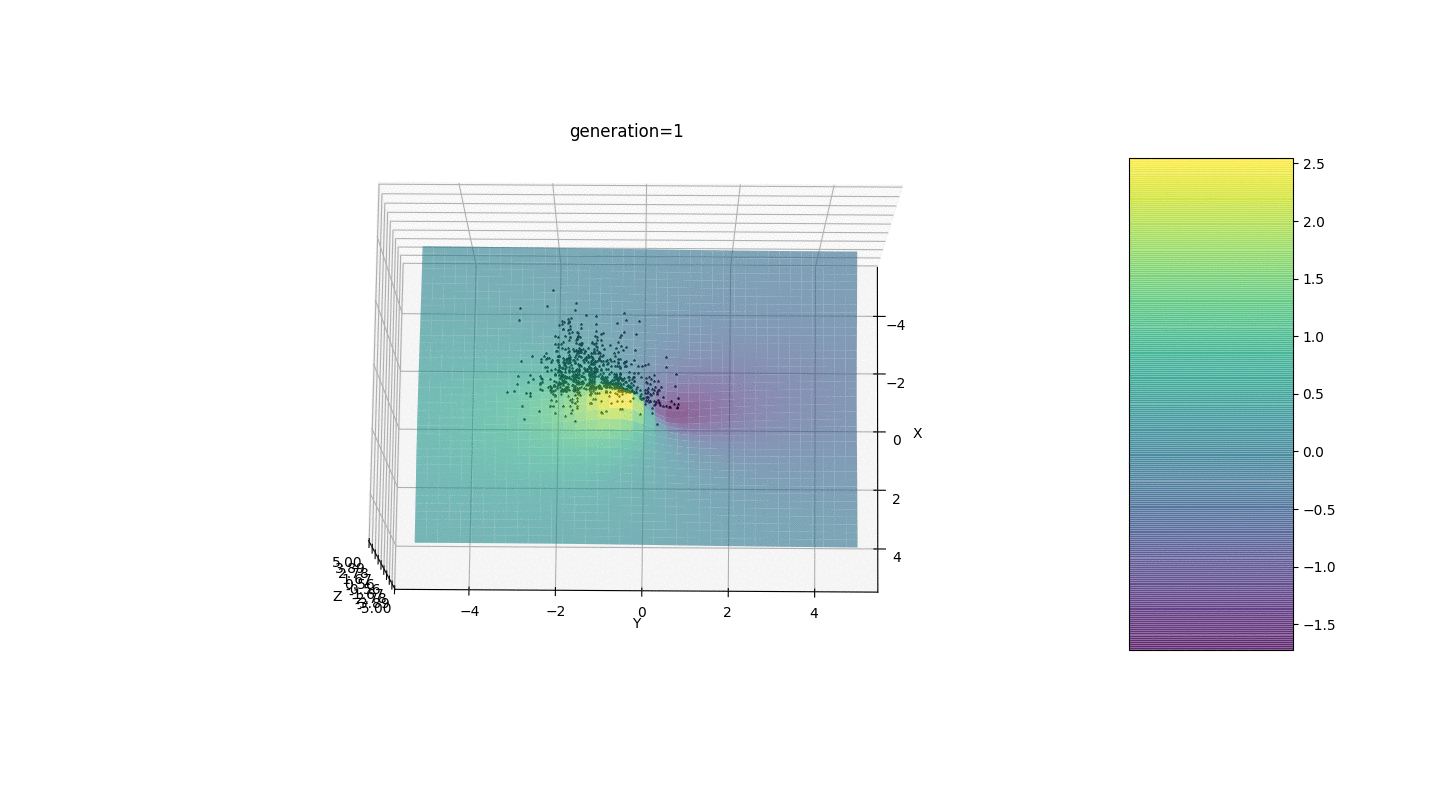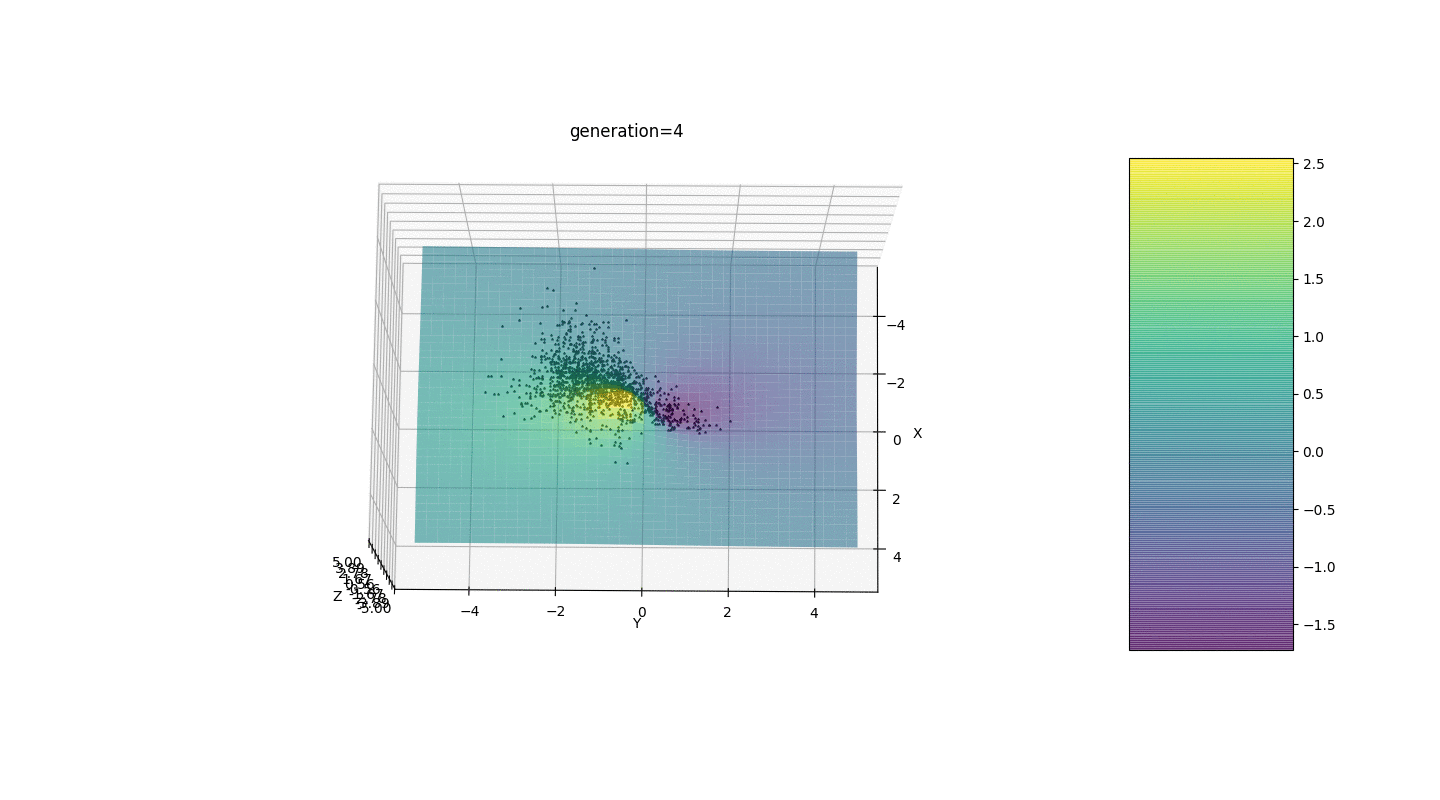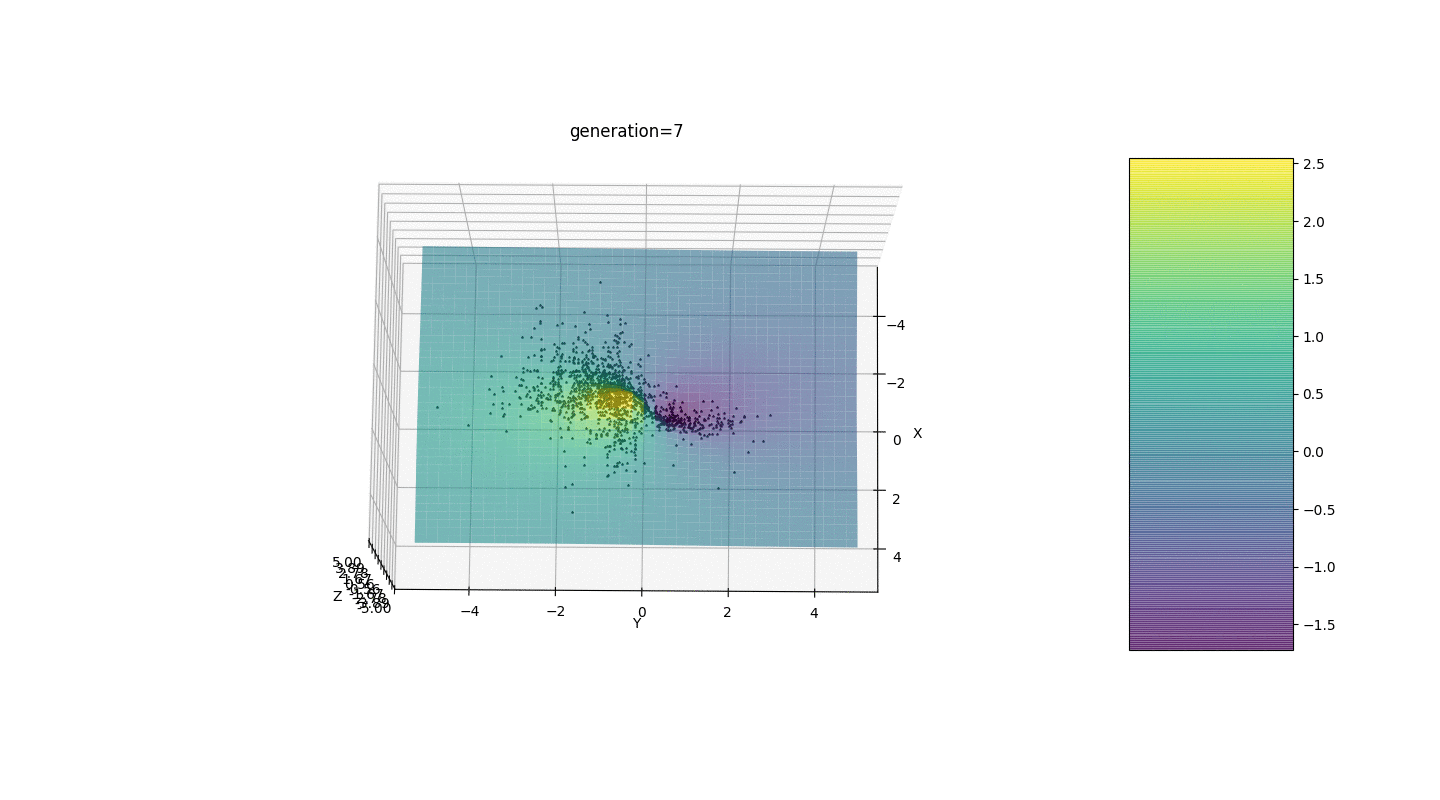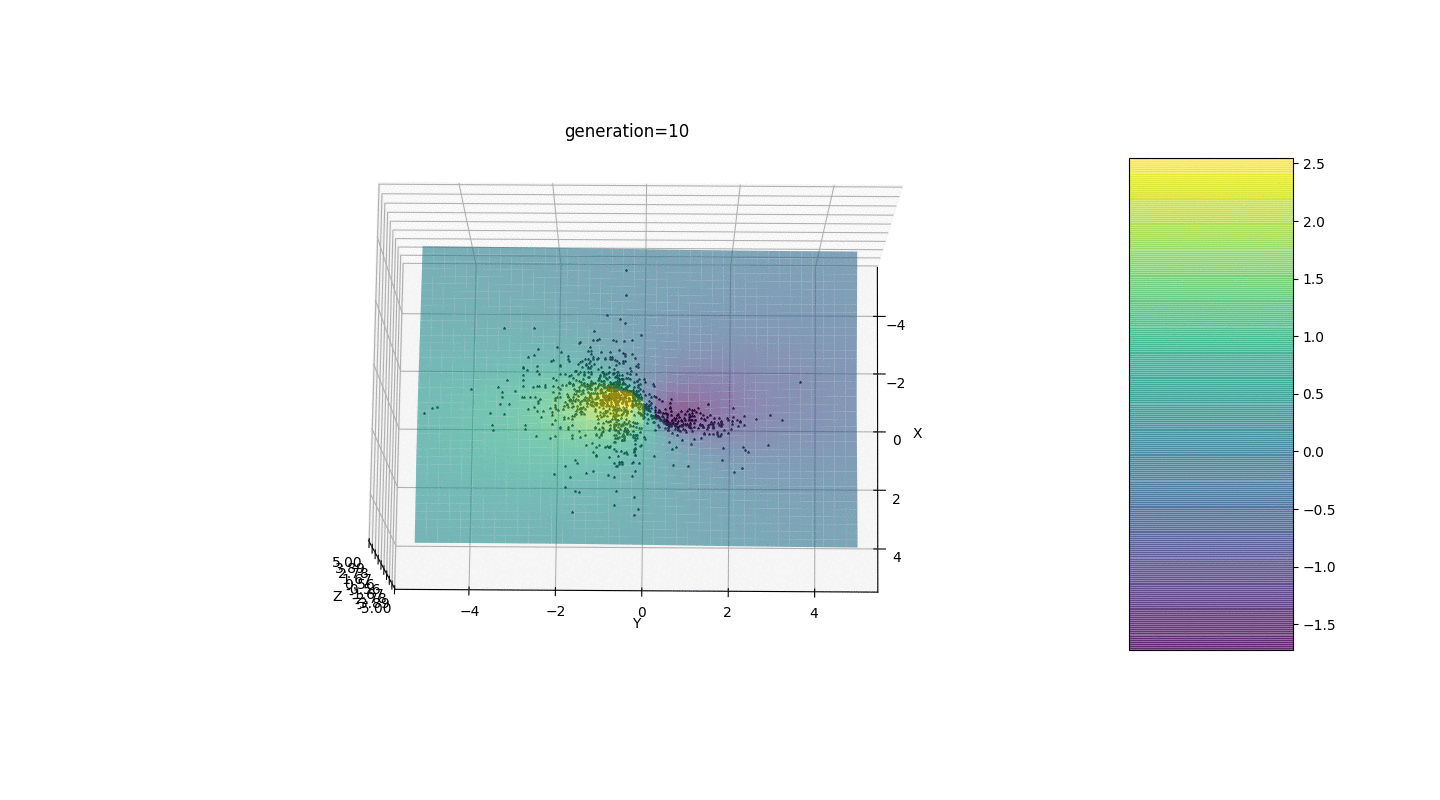

После тестирования и изучения работы алгоритма методом пристального взгляда и случайного тыка выявилось несколько гипотез-закономерностей:
- Погрешность алгоритма прямо пропорциональна количеству особей, но в среднем погрешность исчисляется на сотые, хотя при неудачных параметрах ошибка может достигать и десятых
- На данный момент мутация происходит прибавлением к гену рандомного числа из полуинтервала
из-за чего особи не могут удержаться в окрестности экстремума и происходит относительно сильное колебание в расстоянии между особями разных поколений. В некоторых случаях такие колебания могут оказаться полезными для выхода из локального экстремума, например, периодической функции, однако экстремумы могут находиться на большом расстоянии друг от друга (расстояние в евклидовом понимании)
- Во многих случаях точка экстремума достигается особями за 5-15 поколений, а остальные поколения бесполезно «прыгают» в окрестности этого экстремума
- Нулевое поколение заполняется случайными числами только в квадрате

и возможны случаи, когда данный квадрат покрывает локальный экстремум, что нам не подходит
Рассмотрим поверхность со многими экстремумами вида:

Экстремумы функции g будут находится в точках

Тест 3



Этот пример подтверждает и иллюстрирует все выше сказанные наблюдения.
Апгрейд генетического алгоритма
Итак, на данный момент функция мутации составлена очень примитивно: она добавляет случайные величины из полуинтервала
Введём новый параметр, который назовём «сила мутации» (mutation range) и который будет показывать, в каком полуинтервале мутирует ген. Сделаем так, чтобы данный коэффициент мутации был обратно пропорциональна номеру поколения. Т.е. чем больше номер поколения, тем слабее мутируют гены. Это решение позволяет настраивать стартовую область и улучшать точность вычислений при необходимости.
Тест 1


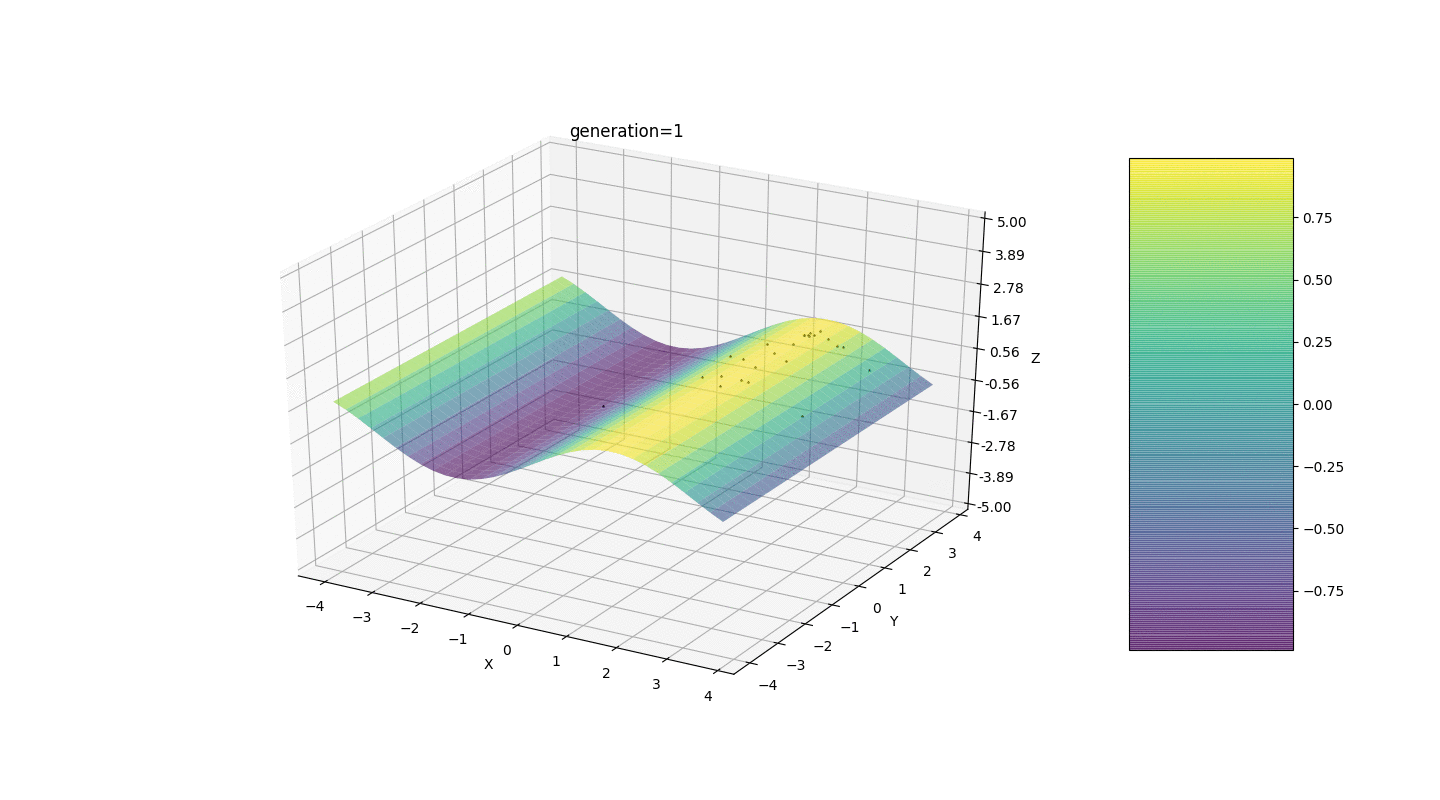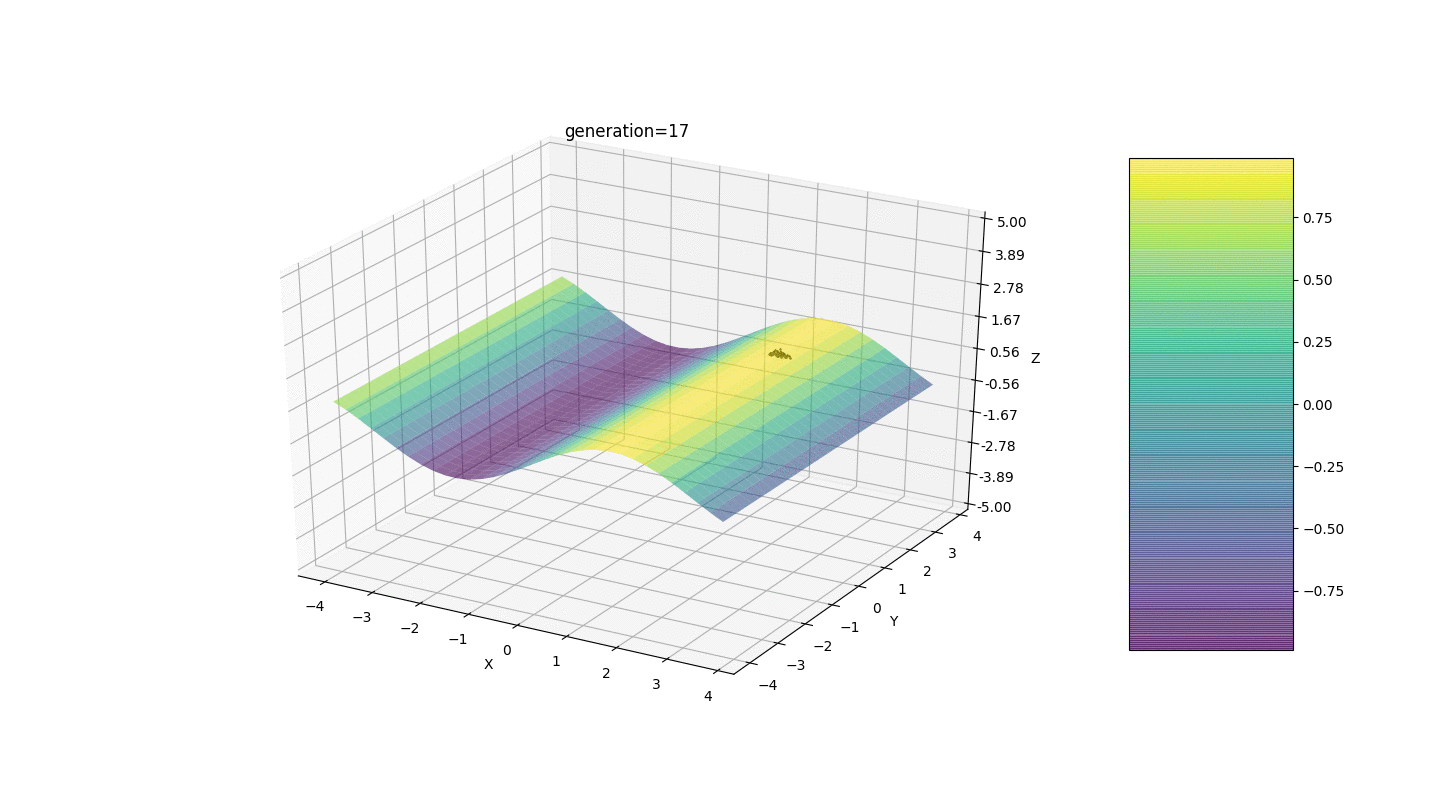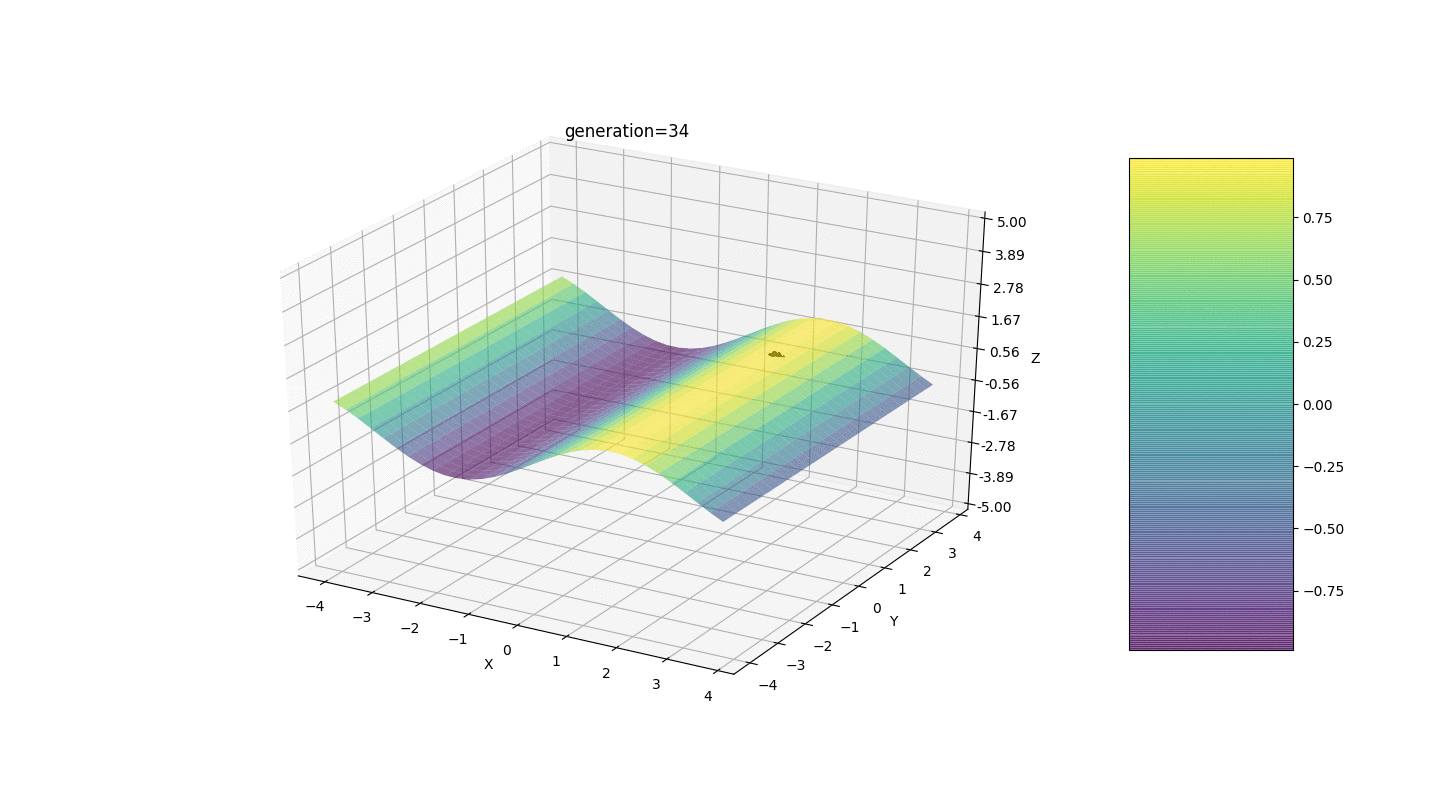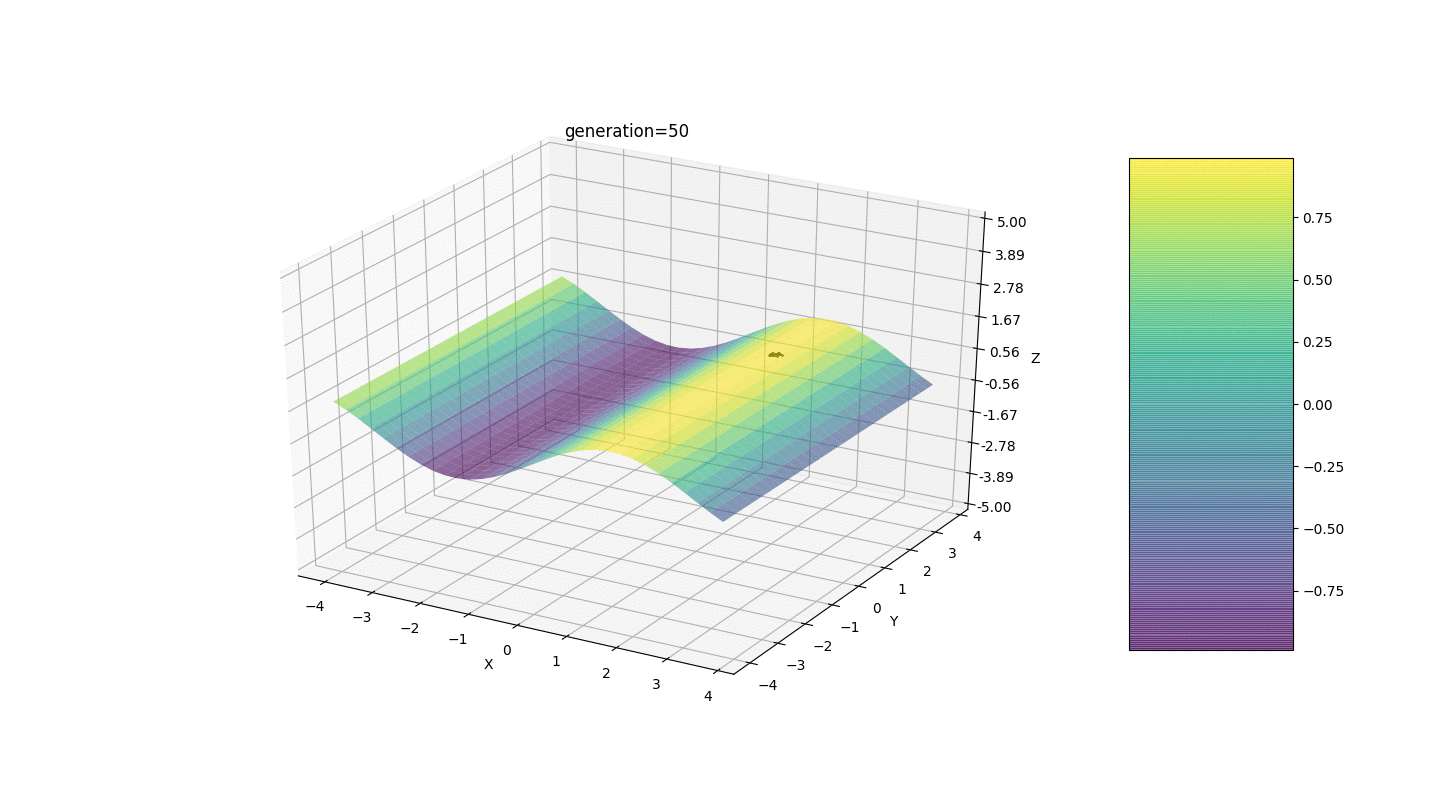

Как видно из примера, теперь, с каждым поколением популяция всё больше сходится в точку экстремума и вычисляет наиболее точные значения за счёт слабых колебаний.
А что же с проблемой локальных экстремумов? Рассмотрим уже знакомый пример.
Тест 2


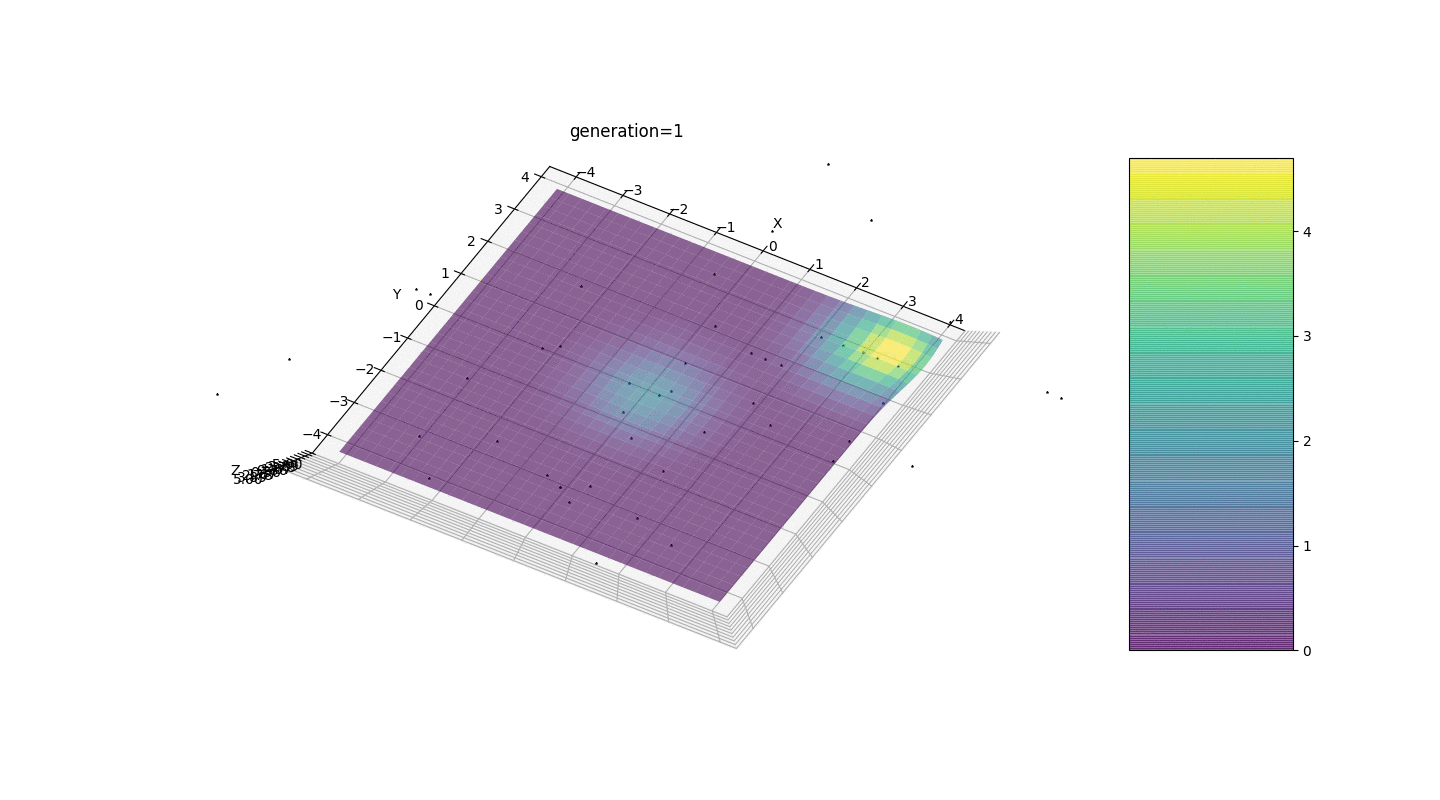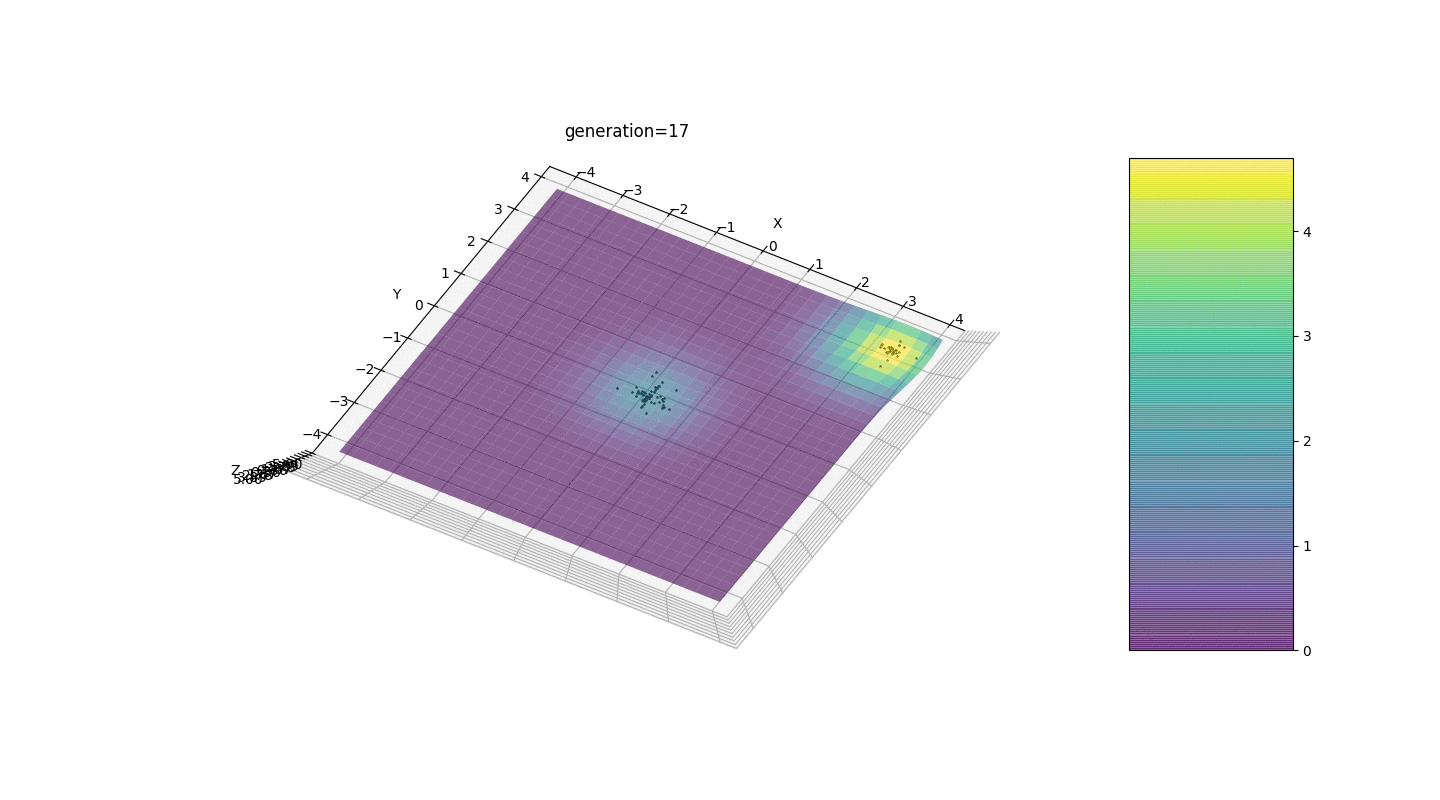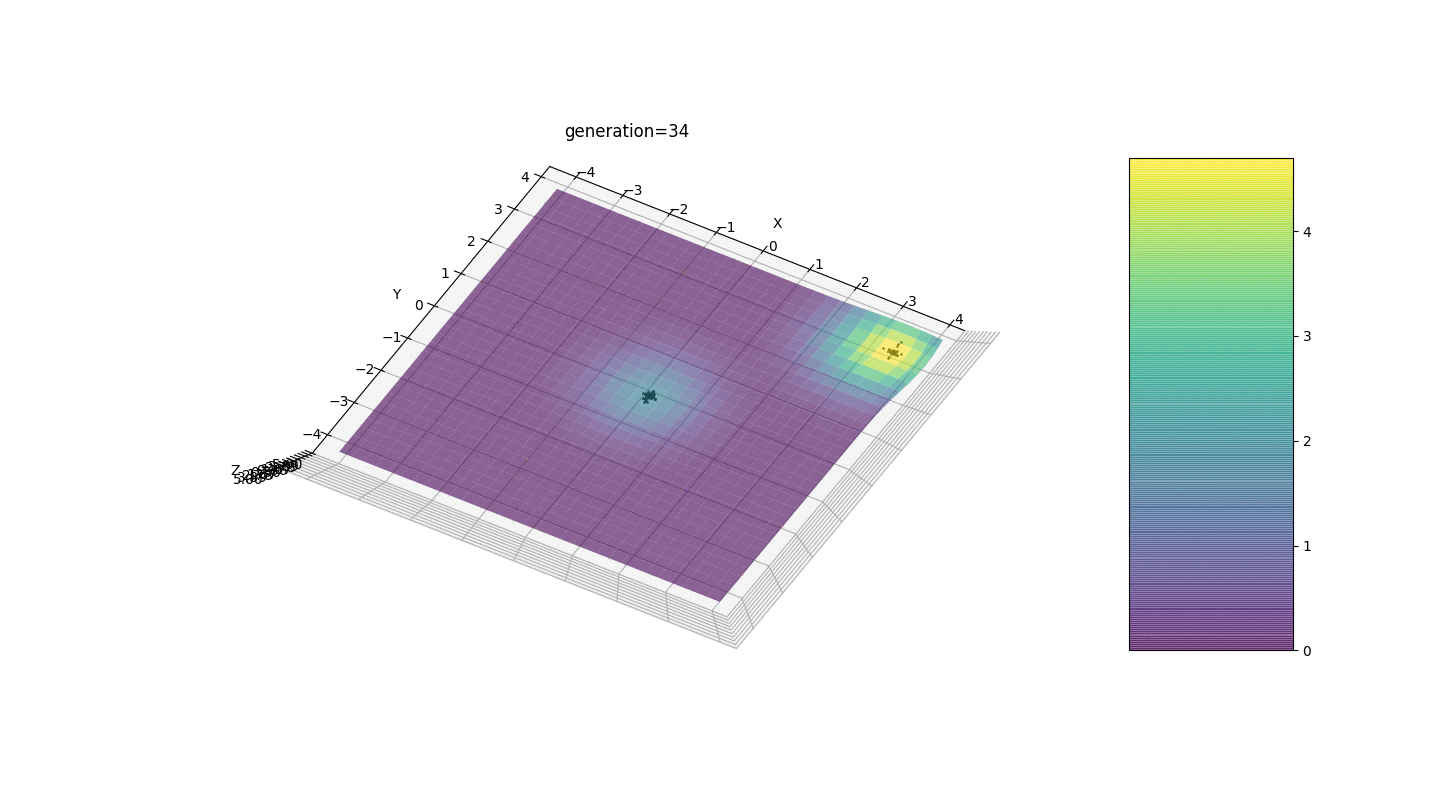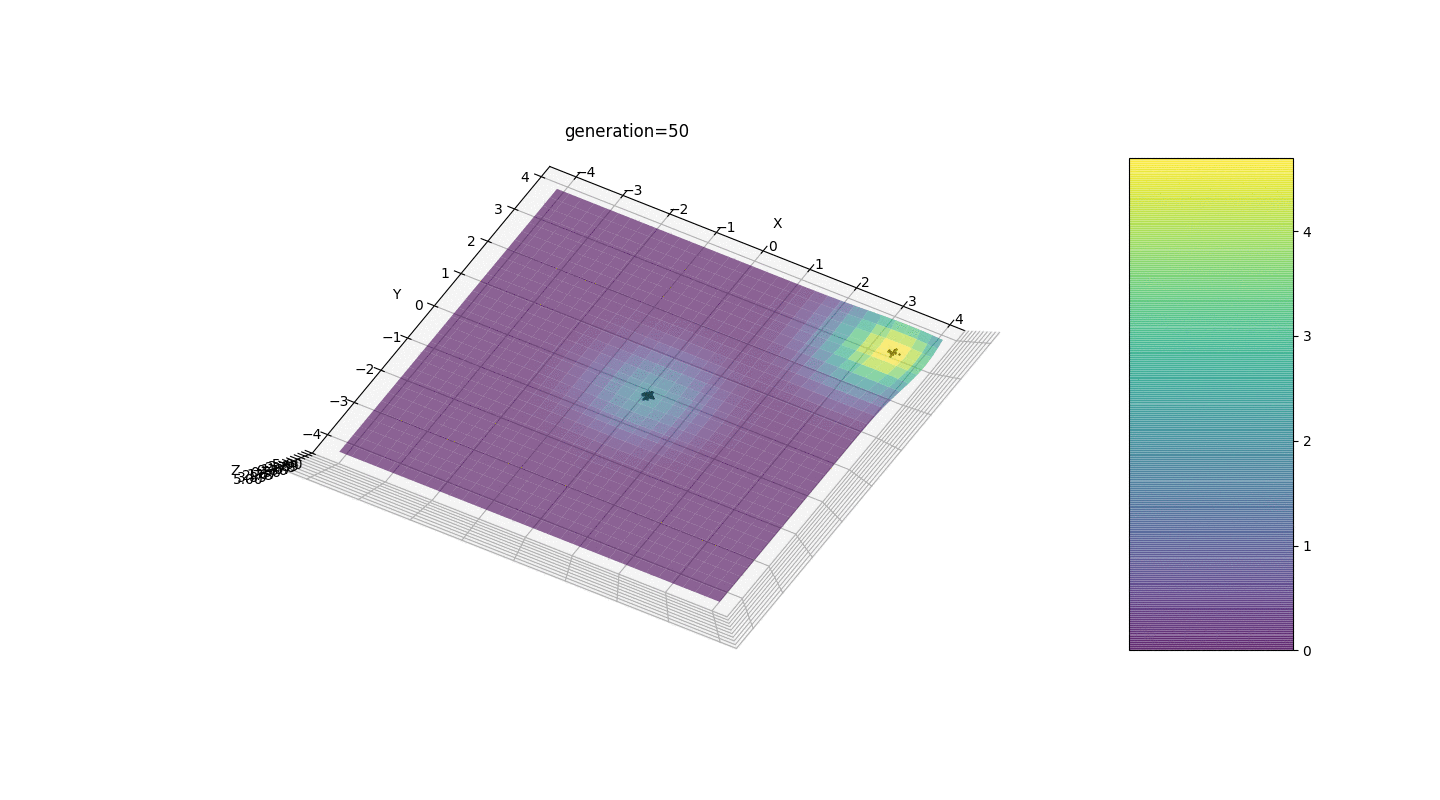

Видим, что теперь идея с разделением популяции на части работает так, как было задумано. Без этой сегментации особи ранних поколений могли бы выявить ложный доминирующий генотип в локальном экстремуме, что привело бы к неправильному ответу в поставленной задаче. Также заметно качественное улучшение в точности ответа благодаря введенной зависимости мутации от номера поколения.
Итоги
Резюмирую полученный результат:
- Правильный набор параметров позволяет достаточно точно найти глобальный экстремум функции от двух переменных
- Разбиение популяции на части позволяет во многих случаях избежать сходимости к локальному оптимуму
- Введение силы мутации позволяет также избежать сходимости к локальному оптимуму и в разы увеличивает точность результата
- Визуализация может помочь в отладке и улучшении алгоритма, а так же помогает понимать ход и принципы самого генетического алгоритма
- повертеть графики, попроверять свои гипотезы и посмотреть код можно тут
В следующих сериях...
- Реализация других функций селекции, скрещивания и мутации. Например, интересно посмотреть, как в поставленной задаче будет работать турнирный метод селекции aka естественный отбор
- Сравнение по времени и эффективности подобных алгоритмов со стандартными методами оптимизации, например, градиентным спуском
- Новые функции пакета (вероятно)
