Новая версия ожидается только в октябре, но уже можно почитать, что нас ждет в ней и потестить предварительный релиз.
В этой статье самые интересные, на мой взгляд, изменения.

Во-первых, нам напоминают, что слои, поддерживающие обратную совместимость с версией 2.7, потихоньку удаляют и просят обратить внимание на DeprecationWarning и устранить их. Несколько предупреждений еще останутся в 3.9, но лучше избавляться и от них.
Оператор объединения словарей (PEP-584)
До этих пор, объединить словари можно было несколькими способами, однако каждый из них имел небольшие недостатки или нюансы.
Теперь можно писать просто
Таким образом новая возможность объединения словарей одним оператором, думаю, придется многим по вкусу.
Упрощение аннотаций для контейнеров и других типов, которые могут быть параметризованы (PEP-0585)
Следующее нововведение очень пригодится тем, кто пользуется аннотацией типов.
Теперь упрощается аннотация коллекций, таких как list и dict, и вообще параметризованных типов.
Для таких типов вводится термин Generic — это тип который может быть параметризован, обычно контейнер. Например, dict. И вопрос в том, как следует корректно переводить его, так чтобы не ломило зубы. Очень уж не хочется пользоваться словом «дженерик». Так что в комментариях очень жду другие предложения. Может где-то в переводах встречалось получше название?
Параметризованный generic: dict[str, int].
Так вот для таких типов теперь не надо импортировать соответствующие аннотации из typing, а можно использовать просто названия типов.
Для строк появились методы removeprefix() и removesuffix() (PEP 616)
Здесь всё просто. Если строка начинается с префикса, то вернется строка без этого префикса. Если префикс повторяется несколько раз, то он удалится только один раз. Аналогично с суффиксом:
Несколько изменений в модуле math
Функция math.gcd() нахождения наибольшего общего делителя теперь принимает список целых чисел, так что можно находить одной функцией общий делитель больше, чем для двух чисел.
Появилась функция для определения наименьшего общего кратного math.lcm(), которая так же принимает неограниченное количество целых чисел.
Следующие две функции взаимосвязаны.
math.nextafter(x, y) — вычисляет ближайшее к x число с плавающей точкой, если двигаться в направлении y.
math.ulp(x) — расшифровывается как «Unit in the Last Place» и зависит от точности расчетов вашего компьютера. Для положительных чисел вернется наименьшее значение числа, такое что при его прибавлении x + ulp(x) получится ближайшее число с плавающей точкой.
Теперь любое валидное выражение может быть декоратором (PEP-0614)
С декораторов снимается ограничение, по которому декоратором может выступать только имя и его синтаксис допускал только разделение точками.
Не думаю, что многие задумывались о существовании такого ограничения, но в описании pep приведен пример, когда нововведение делает код стройнее. По аналогии, можно привести такой
В модуль ast добавили метод unparse (bpo-38870)
Как понятно из названия он может по ast.AST объекту скомпилировать исходную строку. Однажды, мне даже хотелось таким воспользоваться и было удивительно, что такого метода нет.
Новый класс functools.TopologicalSorter для топологической сортировки направленных ациклических графов (bpo-17005)
Граф который передается в сортировщик, должен быть словарем, в котором ключи выступают вершинами графа, а значением является итерируемый объект с предшественниками (вершинами, дуги которых указывают на ключ). В качестве ключа, как обычно, подойдет любой хешируемый тип.
В http.HTTPStatus добавлены новые статусы, которые мы так долго ждали:
103 EARLY_HINTS
418 IM_A_TEAPOT
425 TOO_EARLY
И еще несколько изменений:
Так как версия 3.9 еще в разработке, и, возможно, будут добавлены еще изменения, я планирую дополнять эту статью по необходимости.
Более подробно можно почитать:
docs.python.org/3.9/whatsnew/3.9.html
www.python.org/downloads/release/python-390b3
В общем, не сказать, что грядущие изменения — это то чего все давно ждали и без чего невозможно обойтись, хотя есть некоторые приятные моменты. А что вам показалось наиболее интересным в новой версии?
UPD:
обновлена ссылка на последний релиз
добавлен PEP-0585 про аннотацию типов
В этой статье самые интересные, на мой взгляд, изменения.
Во-первых, нам напоминают, что слои, поддерживающие обратную совместимость с версией 2.7, потихоньку удаляют и просят обратить внимание на DeprecationWarning и устранить их. Несколько предупреждений еще останутся в 3.9, но лучше избавляться и от них.
Оператор объединения словарей (PEP-584)
До этих пор, объединить словари можно было несколькими способами, однако каждый из них имел небольшие недостатки или нюансы.
Несколько способов объединения словарей
1. Использовать метод update словаря
2. Распаковка двух словарей в один
Про это даже Гвидо говорит, что это выглядит не очень, да и надо еще догадаться или вспомнить про такую опцию, но многих устроило бы.
3. Еще вариант похожий на предыдущий dict(d1, **d2), о котором тоже не сразу можно догадаться.Да к тому же не будет работать, если в d2 присутствую не строковые ключи.
4. collections.ChainMap
Еще один неочевидный способ.
Мне кажется странным импортировать даже из стандартной библиотеки, для такого рядового действия, как объединение двух словарей.
При этом, если вы захотите изменить элемент в объединенном словаре, то изменится и элемент в изначальном словаре, о чем очень критично помнить. Мне сложно представить, что для кого-то подобная фича окажется полезной.
d1 = {'one': 1}
d2 = {'two': 2}
# Приходится либо обновлять уже существующий,..
d1.update(d2)
# ...либо создавать копию.
united_dict = d1.copy()
united_dict.update(d2)
2. Распаковка двух словарей в один
united_dict = {**d1, **d2}
Про это даже Гвидо говорит, что это выглядит не очень, да и надо еще догадаться или вспомнить про такую опцию, но многих устроило бы.
3. Еще вариант похожий на предыдущий dict(d1, **d2), о котором тоже не сразу можно догадаться.Да к тому же не будет работать, если в d2 присутствую не строковые ключи.
4. collections.ChainMap
Еще один неочевидный способ.
Мне кажется странным импортировать даже из стандартной библиотеки, для такого рядового действия, как объединение двух словарей.
from collections import ChainMap
d1 = {'one': 1}
d2 = {'two': 2}
united_dict = ChainMap(d1, d2)
При этом, если вы захотите изменить элемент в объединенном словаре, то изменится и элемент в изначальном словаре, о чем очень критично помнить. Мне сложно представить, что для кого-то подобная фича окажется полезной.
Теперь можно писать просто
united_dict = d1 | d2
# или, для того чтобы добавить элементы одного словаря другому, что аналогично методу update():
d1 |= d2
Таким образом новая возможность объединения словарей одним оператором, думаю, придется многим по вкусу.
Упрощение аннотаций для контейнеров и других типов, которые могут быть параметризованы (PEP-0585)
Следующее нововведение очень пригодится тем, кто пользуется аннотацией типов.
Теперь упрощается аннотация коллекций, таких как list и dict, и вообще параметризованных типов.
Для таких типов вводится термин Generic — это тип который может быть параметризован, обычно контейнер. Например, dict. И вопрос в том, как следует корректно переводить его, так чтобы не ломило зубы. Очень уж не хочется пользоваться словом «дженерик». Так что в комментариях очень жду другие предложения. Может где-то в переводах встречалось получше название?
Параметризованный generic: dict[str, int].
Так вот для таких типов теперь не надо импортировать соответствующие аннотации из typing, а можно использовать просто названия типов.
Например
Что конечно намного удобнее и понятнее.
Другой пример:
# вместо
from typing import List
List[str]
# теперь
list[int]
Что конечно намного удобнее и понятнее.
Другой пример:
# раньше
from typing import OrderedDict
OrderedDict[str, int]
# теперь
from collections import OrderedDict
OrderedDict[str, int]
Полный список типов
tuple # typing.Tuple
list # typing.List
dict # typing.Dict
set # typing.Set
frozenset # typing.FrozenSet
type # typing.Type
collections.deque
collections.defaultdict
collections.OrderedDict
collections.Counter
collections.ChainMap
collections.abc.Awaitable
collections.abc.Coroutine
collections.abc.AsyncIterable
collections.abc.AsyncIterator
collections.abc.AsyncGenerator
collections.abc.Iterable
collections.abc.Iterator
collections.abc.Generator
collections.abc.Reversible
collections.abc.Container
collections.abc.Collection
collections.abc.Callable
collections.abc.Set # typing.AbstractSet
collections.abc.MutableSet
collections.abc.Mapping
collections.abc.MutableMapping
collections.abc.Sequence
collections.abc.MutableSequence
collections.abc.ByteString
collections.abc.MappingView
collections.abc.KeysView
collections.abc.ItemsView
collections.abc.ValuesView
contextlib.AbstractContextManager # typing.ContextManager
contextlib.AbstractAsyncContextManager # typing.AsyncContextManager
re.Pattern # typing.Pattern, typing.re.Pattern
re.Match # typing.Match, typing.re.Match
list # typing.List
dict # typing.Dict
set # typing.Set
frozenset # typing.FrozenSet
type # typing.Type
collections.deque
collections.defaultdict
collections.OrderedDict
collections.Counter
collections.ChainMap
collections.abc.Awaitable
collections.abc.Coroutine
collections.abc.AsyncIterable
collections.abc.AsyncIterator
collections.abc.AsyncGenerator
collections.abc.Iterable
collections.abc.Iterator
collections.abc.Generator
collections.abc.Reversible
collections.abc.Container
collections.abc.Collection
collections.abc.Callable
collections.abc.Set # typing.AbstractSet
collections.abc.MutableSet
collections.abc.Mapping
collections.abc.MutableMapping
collections.abc.Sequence
collections.abc.MutableSequence
collections.abc.ByteString
collections.abc.MappingView
collections.abc.KeysView
collections.abc.ItemsView
collections.abc.ValuesView
contextlib.AbstractContextManager # typing.ContextManager
contextlib.AbstractAsyncContextManager # typing.AsyncContextManager
re.Pattern # typing.Pattern, typing.re.Pattern
re.Match # typing.Match, typing.re.Match
Для строк появились методы removeprefix() и removesuffix() (PEP 616)
Здесь всё просто. Если строка начинается с префикса, то вернется строка без этого префикса. Если префикс повторяется несколько раз, то он удалится только один раз. Аналогично с суффиксом:
some_str = 'prefix of some string and here suffix'
some_str.removeprefix('prefix')
>> ' of some string and here suffix'
some_str.removesuffix('suffix')
>> 'prefix of some string and here '
Текущие альтернативы
1. Проверять, если строка начинается с префикса, то вычитать из строки количество букв префикса — именно так будет работать новый метод removeprefix.
2. Использовать lstrip, rstrip:
Но есть риск удалить больше чем нужно в случае, когда строка начинается с повторения префикса, а надо удалить только один.
def removeprefix(self: str, prefix: str, /) -> str:
if self.startswith(prefix):
return self[len(prefix):]
else:
return self[:]
2. Использовать lstrip, rstrip:
'foobar'.lstrip(('foo',))
Но есть риск удалить больше чем нужно в случае, когда строка начинается с повторения префикса, а надо удалить только один.
Несколько изменений в модуле math
Функция math.gcd() нахождения наибольшего общего делителя теперь принимает список целых чисел, так что можно находить одной функцией общий делитель больше, чем для двух чисел.
Появилась функция для определения наименьшего общего кратного math.lcm(), которая так же принимает неограниченное количество целых чисел.
Следующие две функции взаимосвязаны.
math.nextafter(x, y) — вычисляет ближайшее к x число с плавающей точкой, если двигаться в направлении y.
math.ulp(x) — расшифровывается как «Unit in the Last Place» и зависит от точности расчетов вашего компьютера. Для положительных чисел вернется наименьшее значение числа, такое что при его прибавлении x + ulp(x) получится ближайшее число с плавающей точкой.
import math
math.gcd(24, 36)
>> 12
math.lcm(12, 18)
>> 36
math.nextafter(3, -1)
>> 2.9999999999999996
3 - math.ulp(3)
>> 2.9999999999999996
math.nextafter(3, -1) + math.ulp(3)
>> 3.0
Теперь любое валидное выражение может быть декоратором (PEP-0614)
С декораторов снимается ограничение, по которому декоратором может выступать только имя и его синтаксис допускал только разделение точками.
Не думаю, что многие задумывались о существовании такого ограничения, но в описании pep приведен пример, когда нововведение делает код стройнее. По аналогии, можно привести такой
упрощенный и искусственный пример:
def a(func):
def wrapper():
print('a')
func()
return wrapper
def b(func):
def wrapper():
print('b')
func()
return wrapper
decorators = [a, b]
@decorators[0] # в версии 3.8 и ранее интерпретатор споткнулся бы на этих скобках
def some_func():
print('original')
some_func()
>> a
>> original
В модуль ast добавили метод unparse (bpo-38870)
Как понятно из названия он может по ast.AST объекту скомпилировать исходную строку. Однажды, мне даже хотелось таким воспользоваться и было удивительно, что такого метода нет.
Пример:
import ast
parsed = ast.parse('import pprint; pprint.pprint({"one":1, "two":2})')
unparsed_str = ast.unparse(parsed)
print(unparsed_str)
>> import pprint
>> pprint.pprint({'one': 1, 'two': 2})
exec(unparsed_str)
>> {'one': 1, 'two': 2}
Новый класс functools.TopologicalSorter для топологической сортировки направленных ациклических графов (bpo-17005)
Граф который передается в сортировщик, должен быть словарем, в котором ключи выступают вершинами графа, а значением является итерируемый объект с предшественниками (вершинами, дуги которых указывают на ключ). В качестве ключа, как обычно, подойдет любой хешируемый тип.
Пример:
Возьмем к примеру граф из статьи википедии:
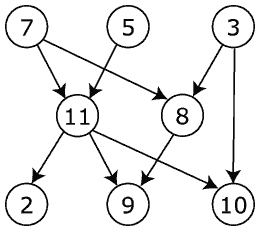
Граф можно передавать не сразу, а заполнять TopologicalSorter с помощью метода add. Кроме того класс адаптирован к параллельным вычислениям и может быть использован, например, для создания очереди задач.
from functools import TopologicalSorter
graph = graph = {8: [3, 7], 11: [5, 7], 2: [11], 9: [8, 11], 10: [3, 11]}
t_sorter = TopologicalSorter(graph)
t_sorted_list = list(t_sorted_list.static_order()) # в случае, когда распараллеливания не требуется, можно использовать напрямую метод static_order.
>> [3, 7, 5, 8, 11, 2, 9, 10]
Граф можно передавать не сразу, а заполнять TopologicalSorter с помощью метода add. Кроме того класс адаптирован к параллельным вычислениям и может быть использован, например, для создания очереди задач.
В http.HTTPStatus добавлены новые статусы, которые мы так долго ждали:
103 EARLY_HINTS
418 IM_A_TEAPOT
425 TOO_EARLY
И еще несколько изменений:
- Ускорены встроенные типы (range, tuple, set, frozenset, list) (PEP-590)
- "".replace("", s, n) теперь возвращает s, а не пустую строку, для всех ненулевых n. Это выполняется и для bytes и bytearray.
- ipaddress теперь поддерживает парсинг адресов IPv6 с назначениями.
Так как версия 3.9 еще в разработке, и, возможно, будут добавлены еще изменения, я планирую дополнять эту статью по необходимости.
Более подробно можно почитать:
docs.python.org/3.9/whatsnew/3.9.html
www.python.org/downloads/release/python-390b3
В общем, не сказать, что грядущие изменения — это то чего все давно ждали и без чего невозможно обойтись, хотя есть некоторые приятные моменты. А что вам показалось наиболее интересным в новой версии?
UPD:
обновлена ссылка на последний релиз
добавлен PEP-0585 про аннотацию типов
