
What is HDB++?
This is a TANGO archiving system, allows you to save data received from devices in the TANGO system.
Working with Linux will be described here (TangoBox 9.3 on base Ubuntu 18.04), this is a ready-made system where everything is configured.
What is the article about?
- System architecture.
- How to set up archiving.
It took me ~ 2 weeks to understand the architecture and write my own scripts for python for this case.
What is it for?
Allows you to store the history of the readings of your equipment.
- You don't need to think about how to store data in the database.
- You just need to specify which attributes to archive from which equipment.
Where to get?
Architecture
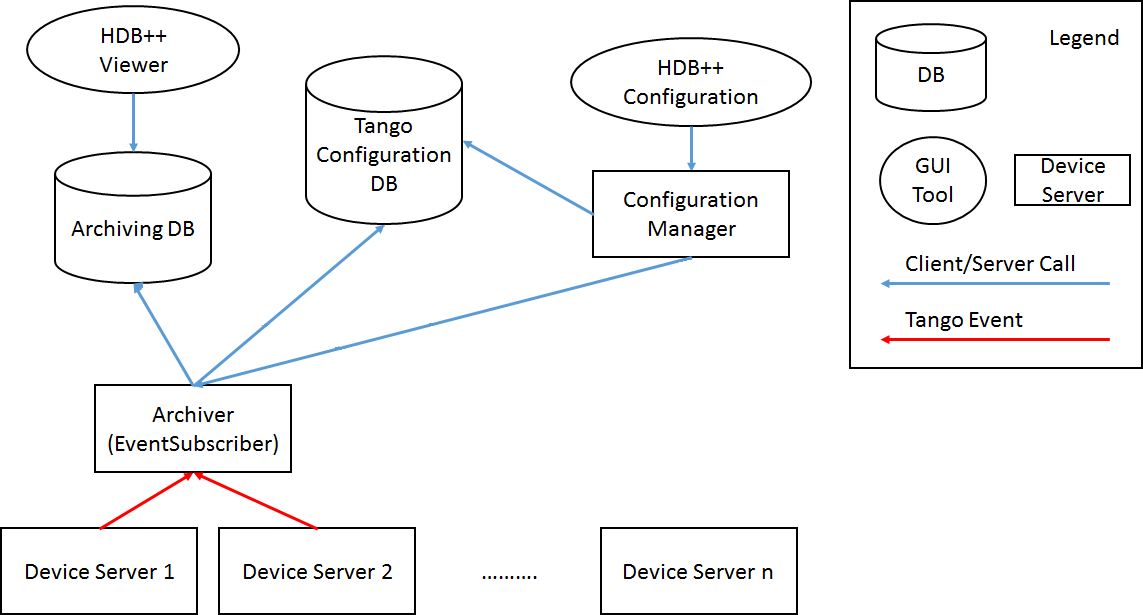
The two most important things here are Archiver and Archiving DB. HDB++ Configuration graphical utility for managing Archiver. HDB ++ Viewer Archiving DB viewer utility.
Archiver interrogates our Device Server and writes history to the Archiving DB.
Archiver is the same Device Server:

Archiving DB in our system is based on MySQL , it is in docker tangobox-hdbpp.

Archiver

Let's see the list of commands for this server.

The picture shows a list of commands for managing this Device Server.
Here we are interested in:
- AttibuteAdd — add attribute.
- AttibutePause — pause archiving attribute.
- AttibuteRemove — delete attribute.
- AttibuteStart — start archiving.
- AttibuteStatus — status attribute.
- AttibuteStop — stop archiving.
Let's look through the Jive list of attributes that Archiver is watching:
jive
Double click on the device.

This Device Server is controlled through the HDB ++ Configuration utility, this is a graphical utility that sends the above commands to archiving/hdbpp/eventsubscriber.1. Further it will be shown how to do this programmatically.
HDB++ Configuration
hdbpp-configurator -configure

It starts/stops archiving and sets the archiving parameters. Double click on the attribute:

- TTL — how many days the history will be archived.
- absolute change — changing the attribute in units.
- relative change — attribute change in percentage.
- event period — if the values have changed, then write every ms.
- Attibute polling period — write every ms.
Archiving DB
In it, we will be interested in the hdbpp database:

You will also need to configure access to the database, from which machine and who is allowed to connect (Because I was too lazy to study how the system was already configured, it is easier to set my user.):
GRANT ALL PRIVILEGES on *.* to 'root'@'172.18.0.1' IDENTIFIED BY 'tango'; FLUSH PRIVILEGES;
Our main system is at 172.18.0.1, the docker database is at 172.18.0.7.
Now let's move on to the database structure, here is the main table att_conf. It contains the attributes that have entered the archiving system:

The important fields here are att_conf_id and att_conf_data_type_id. Using att_conf_data_type_id from the att_conf_data_type table, we get the data type of the attribute. For example scalar_devushort_ro, having received the data type, we find out the table in which the history is stored. The name of the table will be att_scalar_devushort_ro, from this table by att_conf_id we get the data archive of the attribute we are interested in.
Python
Python mechanisms for working with HDB ++.
There is an official python2.7 library for working with HDB++ PyTangoArchiving. I managed to deal with it only when I wrote my library. There is not enough documentation on what is passed to the methods, what data types, what to pass in the arguments (This is my opinion).
My module is built for version >= 3.7. Here, all the standard settings for working on TangoBox 9.3 are set by default.
Installing the module
sudo pip3 install -r requirements.txt sudo python3 setup.py install
Dependencies:
- mysql-connector>=2.2.9
- pytango>=9.3.2
- distribute>=0.7.3
How to use
from hdbpp import HDBPP if __name__ == '__main__': hdbpp = HDBPP() # semantics: # __init__(self, host="172.18.0.7", user="root", password="tango", database="hdbpp", # archive_server_name="archiving/hdbpp/eventsubscriber.1", # server_default = "tango://tangobox:10000") # Connect to the archive server and the database with archives. if hdbpp.connect() == False : exit(0) # Get the history of an attribute for all time. archive = hdbpp.get_archive('tango://tangobox:10000/ECG/ecg/1/Lead') for a in archive: print(a) # The current archive status of the attribute. ret = hdbpp.archiving_status('tango://tangobox:10000/ECG/ecg/1/Lead') print(ret) # Add Attribute to Archive Server. hdbpp.archiving_add(['tango://tangobox:10000/ECG/ecg/1/Lead']) # Start archiving the attribute. hdbpp.archiving_start('tango://tangobox:10000/ECG/ecg/1/Lead', 10 * 60 * 1000, 5 * 60 * 1000, 2, 1) # где: # 10 * 60 * 1000 - poll and archive the attribute every ms # 5 * 60 * 1000 - archive the attribute every ms if the value exceeds the threshold # 2 - attribute change threshold in units # 1 - attribute change threshold in percent # Stop archiving an attribute hdbpp.archiving_stop('tango://tangobox:10000/ECG/ecg/1/Lead') # Close connection hdbpp.close()
More detailed documentation in the code.
It can be viewed like this:
pydoc3 hdbpp.HDBPP
Links
Thank you for attention.
