Приветствую, Хабр. Представляю читателям перевод статьи «JavaScript Visualized: the JavaScript Engine» автора Lydia Hallie.
JavaScript — это круто, но как компьютер усваивает код, который пишется. Разработчикам JavaScript не приходится взаимодействовать с компиляторами самостоятельно. Знание основ движка JavaScript поможет разобраться, как язык обрабатывает наш дружественный человеку код, JS и превращает в то, что машины понимают.
Этот пост относится к движку V8, используется в Node.js и браузерах на основе Chromium.
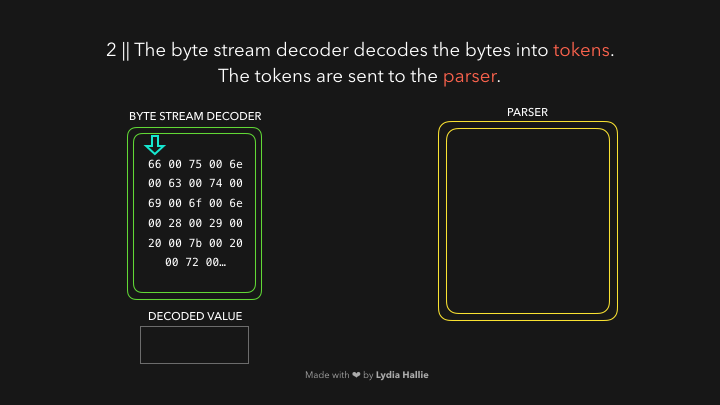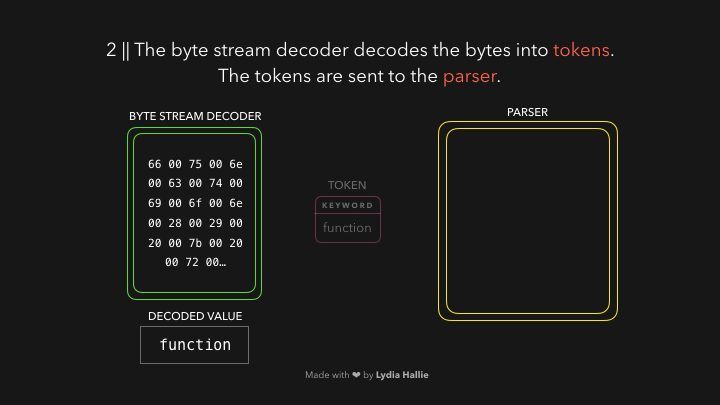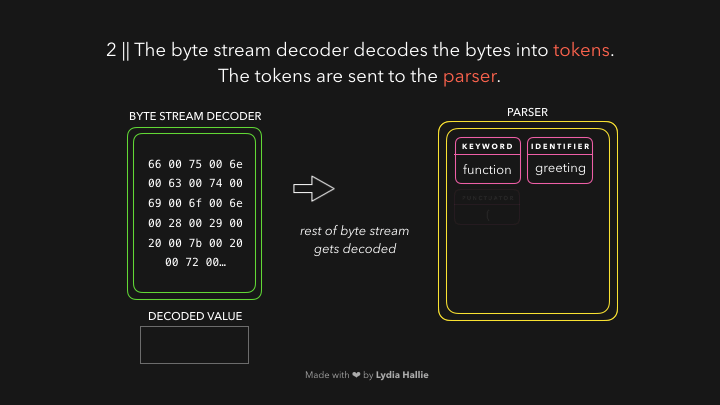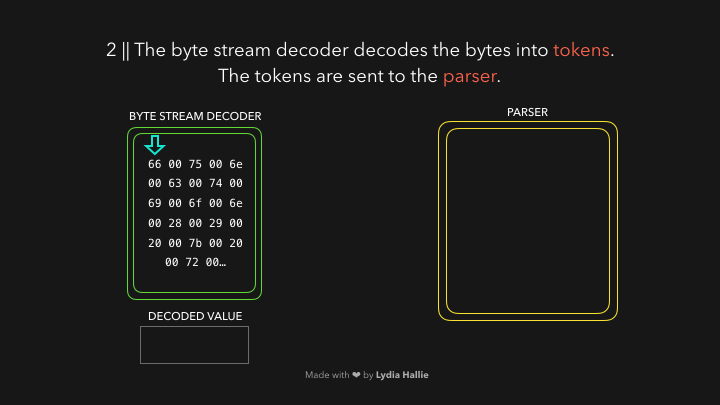
Синтаксический анализатор HTML обнаруживает тег сценария с источником. Код из этого источника загружается из сети, из кэша или с установленного рабочего сервиса. Ответом станет скрипт в виде потока байтов, о котором заботится декодер потока байтов. Декодер потока байтов декодирует поток байтов по мере загрузки.
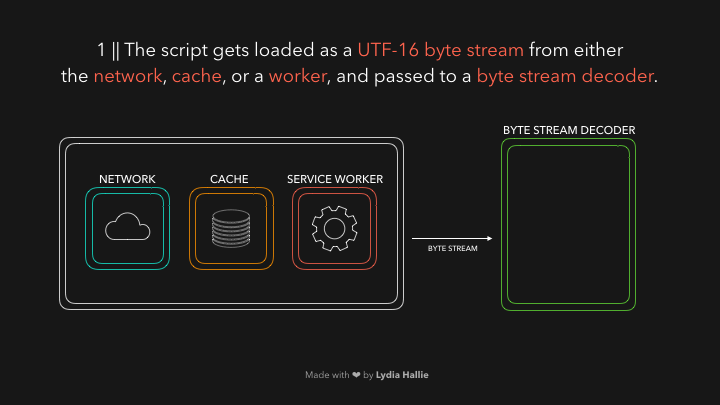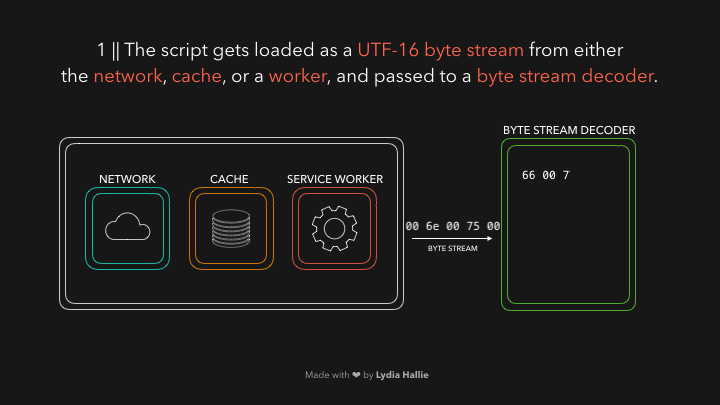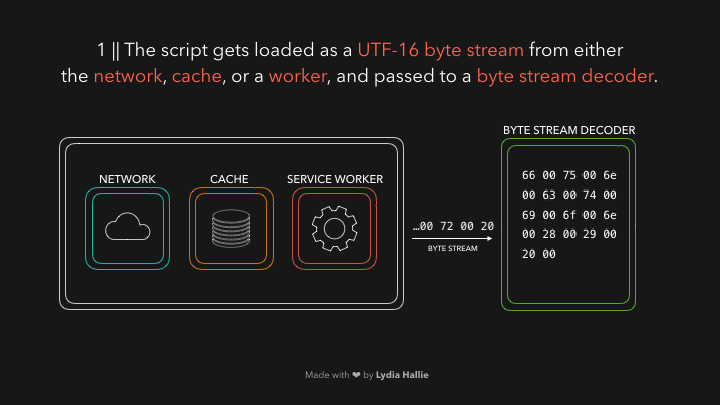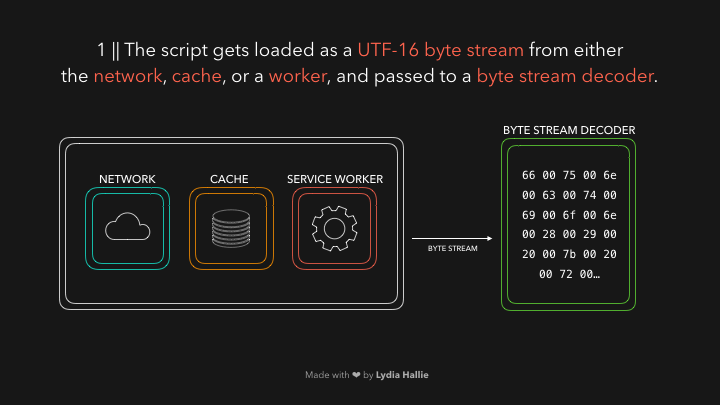
Декодер потока байтов создает токены из декодированного потока байтов. Например, 0066 декодирует до f, от 0075 до u за которым следует пробел. Произошло написание функции. Это зарезервированное слово в JavaScript, токен создается и отправляется анализатору и предварительному анализатору, который показан ниже в gifs, но объясню позже. Те же процедуры происходят с остальной частью потока байтов.
Движок использует два парсера: предварительный и динамический. Предварительный анализатор проверяет токены заранее, чтобы увидеть, присутствие синтаксических ошибок ical. Это уменьшит количество, необходимое для обнаружения ошибок в коде, которые в противном случае обнаружатся динамическим парсером позже.Если ошибок нет, парсер создает узлы на основе токенов, которые получает декодер потока байтов. С этими узлами создается абстрактное синтаксическое дерево или AST.

Далее пришло время для переводчика. Интерпретатор, который проходит через AST и генерирует байт-код на основе информации, содержатся в AST. Как только байт-код сформируются, AST удаляется, очищает память. Теперь у пользователя появилось информация, с чем машина работает.

Хотя байт-код работает быстрее. Когда байт-код работает, информация генерируется и определяет, часто ли происходит это повторение, и типы используемых файлов, если функция используется десятки раз: пришло время оптимизации, чтобы работа стала еще быстрее.
Байт-код вместе со сформировавшейся обратной связью отправляется оптимизирующему компилятору. Оптимизирующий компилятор принимает байт-код и тип обратной связи и генерирует из них оптимизированный машинный код.

JavaScript — динамически типизированный язык, типы файлов могут постоянно меняться. Было бы медленно, если бы движку JavaScript приходилось каждый раз проверять, какой тип файлов подходит по значению.
Вместо этого движок использует технику, называемую встроенным кэшированием. Кэширование происходит в коде памяти в надежде, что в будущем вернется то же значение с тем же повтором, если функция вызывается 100 раз и возвращает одно и то же значение. Скорее всего вернет это значение в 101-й раз, когда вызовется.
Допустим, следующая функция sum, которая вызывалась с числовыми значениями в качестве аргументов каждый раз:

Это возвращает номер 3. В следующий раз, когда произойдет вызов, функция будет предполагать, что вызов произойдет снова с двумя числовыми значениями.
Если это так, динамический поиск не требуется, и используется результат, сохраненный в слоте памяти, на который уже ссылался. Иначе, если предположение было неверным, будет де-оптимизироваться код и вернется к исходному байт-коду вместо оптимизированного машинного кода.
Например, в следующий раз, когда при вызове, передается строке вместо числа. Так как JavaScript динамически типизирован, возможно сделать это без ошибок!

Это означает, что число 2 будет приведено в строку, а функция вернет строку «12». При возвращении к выполнению интерпретированного байт-кода обновляется и обратная связь.
Надеюсь этот пост станет полезным. Конечно, в движке много частей, некоторые не рассмотрены в этой статье. О которых я мог бы рассказать позже. Определенно, призываю начать некоторое изучение самостоятельно, если интересуетесь устройством JavaScript, V8 содержит открытый исходный код и документацию о том, как работает.
V8 Документы || V8 Github || Университет Chrome 2018: Жизнь или Код
Не стесняйтесь обращаться. Twitter || Instagram || GitHub || LinkedIn
FAQ: Для создания анимации и записи на экране использовано приложение Keynote. Не стесняйтесь перевести этот блог на родной язык, и спасибо за это. Оставьте ссылку на оригинальную статью и дайте знать, если перевели, пожалуйста.
JavaScript — это круто, но как компьютер усваивает код, который пишется. Разработчикам JavaScript не приходится взаимодействовать с компиляторами самостоятельно. Знание основ движка JavaScript поможет разобраться, как язык обрабатывает наш дружественный человеку код, JS и превращает в то, что машины понимают.
Этот пост относится к движку V8, используется в Node.js и браузерах на основе Chromium.
Синтаксический анализатор HTML обнаруживает тег сценария с источником. Код из этого источника загружается из сети, из кэша или с установленного рабочего сервиса. Ответом станет скрипт в виде потока байтов, о котором заботится декодер потока байтов. Декодер потока байтов декодирует поток байтов по мере загрузки.
Декодер потока байтов создает токены из декодированного потока байтов. Например, 0066 декодирует до f, от 0075 до u за которым следует пробел. Произошло написание функции. Это зарезервированное слово в JavaScript, токен создается и отправляется анализатору и предварительному анализатору, который показан ниже в gifs, но объясню позже. Те же процедуры происходят с остальной частью потока байтов.
Движок использует два парсера: предварительный и динамический. Предварительный анализатор проверяет токены заранее, чтобы увидеть, присутствие синтаксических ошибок ical. Это уменьшит количество, необходимое для обнаружения ошибок в коде, которые в противном случае обнаружатся динамическим парсером позже.Если ошибок нет, парсер создает узлы на основе токенов, которые получает декодер потока байтов. С этими узлами создается абстрактное синтаксическое дерево или AST.
Далее пришло время для переводчика. Интерпретатор, который проходит через AST и генерирует байт-код на основе информации, содержатся в AST. Как только байт-код сформируются, AST удаляется, очищает память. Теперь у пользователя появилось информация, с чем машина работает.
Хотя байт-код работает быстрее. Когда байт-код работает, информация генерируется и определяет, часто ли происходит это повторение, и типы используемых файлов, если функция используется десятки раз: пришло время оптимизации, чтобы работа стала еще быстрее.
Байт-код вместе со сформировавшейся обратной связью отправляется оптимизирующему компилятору. Оптимизирующий компилятор принимает байт-код и тип обратной связи и генерирует из них оптимизированный машинный код.
JavaScript — динамически типизированный язык, типы файлов могут постоянно меняться. Было бы медленно, если бы движку JavaScript приходилось каждый раз проверять, какой тип файлов подходит по значению.
Вместо этого движок использует технику, называемую встроенным кэшированием. Кэширование происходит в коде памяти в надежде, что в будущем вернется то же значение с тем же повтором, если функция вызывается 100 раз и возвращает одно и то же значение. Скорее всего вернет это значение в 101-й раз, когда вызовется.
Допустим, следующая функция sum, которая вызывалась с числовыми значениями в качестве аргументов каждый раз:
Это возвращает номер 3. В следующий раз, когда произойдет вызов, функция будет предполагать, что вызов произойдет снова с двумя числовыми значениями.
Если это так, динамический поиск не требуется, и используется результат, сохраненный в слоте памяти, на который уже ссылался. Иначе, если предположение было неверным, будет де-оптимизироваться код и вернется к исходному байт-коду вместо оптимизированного машинного кода.
Например, в следующий раз, когда при вызове, передается строке вместо числа. Так как JavaScript динамически типизирован, возможно сделать это без ошибок!
Это означает, что число 2 будет приведено в строку, а функция вернет строку «12». При возвращении к выполнению интерпретированного байт-кода обновляется и обратная связь.
Надеюсь этот пост станет полезным. Конечно, в движке много частей, некоторые не рассмотрены в этой статье. О которых я мог бы рассказать позже. Определенно, призываю начать некоторое изучение самостоятельно, если интересуетесь устройством JavaScript, V8 содержит открытый исходный код и документацию о том, как работает.
V8 Документы || V8 Github || Университет Chrome 2018: Жизнь или Код
Не стесняйтесь обращаться. Twitter || Instagram || GitHub || LinkedIn
FAQ: Для создания анимации и записи на экране использовано приложение Keynote. Не стесняйтесь перевести этот блог на родной язык, и спасибо за это. Оставьте ссылку на оригинальную статью и дайте знать, если перевели, пожалуйста.