

Помни: сила рыцаря-джедая — это сила Вселенной.
Но помни: гнев, страх — это всё ведет на темную сторону Силы.
Как только ты сделаешь первый шаг по темному пути,
ты уже не сможешь с него свернуть…
Добрый день, уважаемый галактический сенат! На связи снова Денис Мельский, и сегодня на повестке дня — определение теоретического минимума познания *nix систем для юного падавана web-мастерства.
Хотелось бы начать с того, что все мы прекрасно знаем: на 67.4 % наши любимые интернеты крутятся на *nix-based-серверах, а в жизни среднестатистического web-разработчика в вакууме — так и на все 90 %.

Для любителей пруфов — welcome.
Т. ч. в нашем ремесле без знания *nix-систем никак. Давайте проведем экскурс в мир *nix и поймем, какими знаниями должен обладать юный падаван.
Предлагаю рассмотреть три юниорских степени познания дзена управлением шайтан-машиной ака *nix-сервак на примере всеми любимой ubuntu.






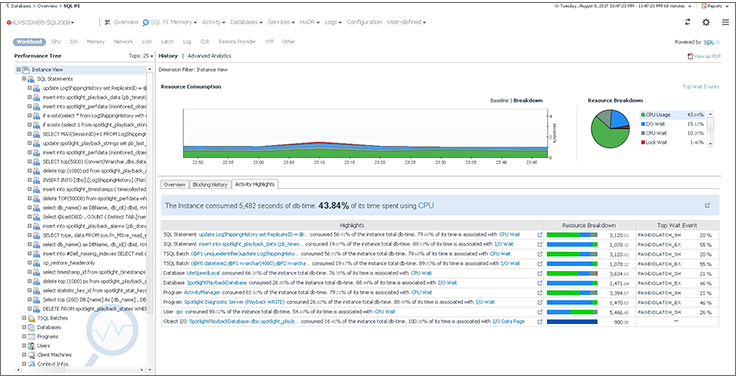
 Настройка производительности базы данных — разработчики обычно либо любят это, либо ненавидят. Я получаю удовольствие от этого и хочу поделиться некоторыми методами, которые я использовал в последнее время для настройки плохо выполняющихся запросов в PostgreSQL. Мои методы не является исчерпывающими, скорее учебником для тех, кто просто тащится от тюнинга.
Настройка производительности базы данных — разработчики обычно либо любят это, либо ненавидят. Я получаю удовольствие от этого и хочу поделиться некоторыми методами, которые я использовал в последнее время для настройки плохо выполняющихся запросов в PostgreSQL. Мои методы не является исчерпывающими, скорее учебником для тех, кто просто тащится от тюнинга.



{kind=link}