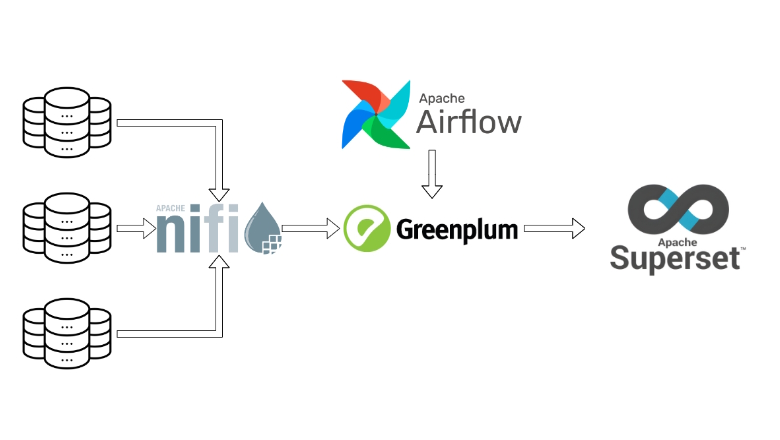
В этой статье речь пойдет об архитектуре хранилищ данных. Чем руководствоваться при ее построении, какие подходы работают – и почему.
 Посадил дед… хранилище. И выросло хранилище большое-пребольшое. Вот только толком не знал, как оно устроено. И затеял дед ревью. Позвал дед бабку, внучку, кота и мышку на семейный совет. И молвит такую тему: «Выросло у нас хранилище. Данные со всех систем стекаются, таблиц видимо-невидимо. Пользователи отчеты свои стряпают. Вроде бы все хорошо – жить да жить. Да только одна печаль – никто не знает, как оно устроено. Дисков требует видимо-невидимо – не напасешься! А тут еще пользователи ко мне ходить повадились с жалобами разными: то отчет зависает, то данные устаревшие. А то и совсем беда – приходим мы с отчетами к царю-батюшке, а цифры-то между собой не сходятся. Не ровен час – разгневается царь – не сносить тогда головы – ни мне, ни вам. Вот решил я вас собрать и посоветоваться: что делать-то будем?».
Посадил дед… хранилище. И выросло хранилище большое-пребольшое. Вот только толком не знал, как оно устроено. И затеял дед ревью. Позвал дед бабку, внучку, кота и мышку на семейный совет. И молвит такую тему: «Выросло у нас хранилище. Данные со всех систем стекаются, таблиц видимо-невидимо. Пользователи отчеты свои стряпают. Вроде бы все хорошо – жить да жить. Да только одна печаль – никто не знает, как оно устроено. Дисков требует видимо-невидимо – не напасешься! А тут еще пользователи ко мне ходить повадились с жалобами разными: то отчет зависает, то данные устаревшие. А то и совсем беда – приходим мы с отчетами к царю-батюшке, а цифры-то между собой не сходятся. Не ровен час – разгневается царь – не сносить тогда головы – ни мне, ни вам. Вот решил я вас собрать и посоветоваться: что делать-то будем?».
«Сказка ложь – да в ней намек…»
Посадил дед… хранилище. И выросло хранилище большое-пребольшое. Вот только толком не знал, как оно устроено. И затеял дед ревью. Позвал дед бабку, внучку, кота и мышку на семейный совет. И молвит такую тему: «Выросло у нас хранилище. Данные со всех систем стекаются, таблиц видимо-невидимо. Пользователи отчеты свои стряпают. Вроде бы все хорошо – жить да жить. Да только одна печаль – никто не знает, как оно устроено. Дисков требует видимо-невидимо – не напасешься! А тут еще пользователи ко мне ходить повадились с жалобами разными: то отчет зависает, то данные устаревшие. А то и совсем беда – приходим мы с отчетами к царю-батюшке, а цифры-то между собой не сходятся. Не ровен час – разгневается царь – не сносить тогда головы – ни мне, ни вам. Вот решил я вас собрать и посоветоваться: что делать-то будем?».