Недавно Минздрав выложил таблицу с предельными ценами на жизненно необходимые лекарства, я неслабо заморочился и проверил как часто эти пределы в Москве превышаются.


BigD @BigD
IT Manager
Проброс DLNA в удаленную сеть
5 min
Предыстория:
Итак, появилась необходимость дать возможность просматривать фильмы с моего сервера на телевизоре. Ну казалось бы, поднимаем DLNA, например miniDLNA и проблема решена. Так и было, пока не появилась нужда дать такую же возможность родителям, которые живут в другом месте, и ставить им там сервер или простенький nas не хотелось. Было принято решение объединить наши сети путем туннелирования трафика и дать доступ к моей фильмотеке.
Итак, появилась необходимость дать возможность просматривать фильмы с моего сервера на телевизоре. Ну казалось бы, поднимаем DLNA, например miniDLNA и проблема решена. Так и было, пока не появилась нужда дать такую же возможность родителям, которые живут в другом месте, и ставить им там сервер или простенький nas не хотелось. Было принято решение объединить наши сети путем туннелирования трафика и дать доступ к моей фильмотеке.
Не пора ли реляционным базам данных на свалку истории?
10 min
Здравствуйте, меня зовут Дмитрий Карловский и я… антиконформист, то есть человек, который не держится за свои привычки и всегда готов их поменять, если в том есть необходимость. Например, как и многие разработчики, я начинал изучение баз данных с реляционных. Хотя реляционная алгебра и довольно красива в своей простоте, я постоянно ловил себя на мысли, что пытаюсь впихнуть круглую фигуру в квадратное отверстие и получалось как-то не герметично.

Нет, я не буду рассказывать вам про MongoDB или ещё какую неполноценную «убийцу SQL». Статей на тему «SQL vs NoSQL» сравнивающих на самом деле реляционные субд с документными и так полно:
Но у большинства из них есть фатальный недостаток — авторы просто не в курсе, что моделей данных в СУБД есть куда больше, чем два упомянутых: от узкоспециализированных «словарей», то универсальных «графов». А популярные «реляционные» и «документные» находятся лишь где-то по середине между универсальностью и специализированностью.
Давайте сравним типичных представителей упомянутых типов СУБД (от большего к меньшему).
Нет, я не буду рассказывать вам про MongoDB или ещё какую неполноценную «убийцу SQL». Статей на тему «SQL vs NoSQL» сравнивающих на самом деле реляционные субд с документными и так полно:
- MongoDB или как разлюбить SQL
- Реляционные базы данных обречены?
- NoSQL базы данных: понимаем суть
- Почему нужно 1000 раз подумать, прежде чем использовать noSQL
- SQL — гибок или почему я боюсь NoSQL
- NoSQL и Big Data – обман трудящихся?
- Чем поможет архитектору «NoSQL» и… поможет ли?
- Сравнение производительности MongoDB vs PostgreSQL. Часть I: No index
- Сравнение производительности MongoDB vs PostgreSQL. Часть II: Index
- Разбираем ACID по буквам в NoSQL
- Почему вы никогда не должны использовать MongoDB
- Почему мы выбрали MongoDB
- Недостатки RDBMS или RDBMS vs NoSQL
- Почему вы никогда не должны говорить «никогда»
- Еж с ужом в одной корзине, а также немного об отсутствии схемы
- Почему реляционные СУБД отлично подходят для стартапов: Пример из истории разработки мессенджера Kato
- Прощай, MongoDB, здравствуй, PostgreSQL
Но у большинства из них есть фатальный недостаток — авторы просто не в курсе, что моделей данных в СУБД есть куда больше, чем два упомянутых: от узкоспециализированных «словарей», то универсальных «графов». А популярные «реляционные» и «документные» находятся лишь где-то по середине между универсальностью и специализированностью.
Давайте сравним типичных представителей упомянутых типов СУБД (от большего к меньшему).
- Популярность: Oracle, MongoDB, Redis, HBase, OrientDB.
- Функциональность: OrientDB, Oracle, MongoDB, HBase, Redis.
- Скорость: очень сильно зависит от задачи, данных и реализации приложения. Я пересмотрел кучу бенчмарков, везде всё по разному.
Рисуем на тайлах электронной карты в MSSQL
37 min
Хочу рассказать читателям хабра-сообщества как используя CLR библиотеку Microsoft.SqlServer.Types можно формировать тайлы для электронной карты. В статье пойдёт речь о генерации списка картографических тайлов для их дальнейшего рендеринга. Будет описан алгоритм генерации тайлов по геометрии объектов, хранящейся в базе данных MS SQL 2008. Весь процесс рендеринга шаг за шагом будет рассмотрен на примере в конце статьи.

Проблема
Исходные данные
Решение
Хранилище тайлов
Этапы подготовки тайлов
Используемые функции
Пример с ломаной линией
Проверка пересечения
Таблицы для хранения образов тайлов
Размещение иконки на тайле
Объединение тайлов
Отрисовка геометрии на тайле
Заключение
Содержание
Проблема
Исходные данные
Решение
Хранилище тайлов
Этапы подготовки тайлов
Используемые функции
Пример с ломаной линией
Проверка пересечения
Таблицы для хранения образов тайлов
Размещение иконки на тайле
Объединение тайлов
Отрисовка геометрии на тайле
Заключение
Домашний сервер для работы и не только. Организация рабочего места ленивого инженера
6 min
 Однажды став тем или иным специалистом в сфере IT, каждый из нас начинает окружать себя всевозможными инструментами для работы и отдыха. Далее это перерастает в целый комплекс мероприятий по поддержанию привычек, установленного расписания дня, комфортных условий труда и отдыха. Не претендуя на какую-либо уникальность, все же хотелось поделиться организацией «рабочего» процесса и отдыха ленивого администратора, как результатом знакомства с разными сферами IT, близкими к основной деятельности.
Однажды став тем или иным специалистом в сфере IT, каждый из нас начинает окружать себя всевозможными инструментами для работы и отдыха. Далее это перерастает в целый комплекс мероприятий по поддержанию привычек, установленного расписания дня, комфортных условий труда и отдыха. Не претендуя на какую-либо уникальность, все же хотелось поделиться организацией «рабочего» процесса и отдыха ленивого администратора, как результатом знакомства с разными сферами IT, близкими к основной деятельности.Вспоминая слова одного преподавателя вуза: «Кто такой инженер? Это же лентяй! Вот он лежит на диване, смотрит телевзор. И захотелось ему переключить канал — но вставать то лень! „Ай, ну его, каналы вставать переключать — пойду-ка разработаю пульт дистанционного управления...“. Всегда хотелось сделать что-то интересное и максимально это автоматизировать…
Sipuni: путь разработки от виртуальной АТС к SaaS-сервису по приёму телефонных звонков
6 min
Привет, Хабр! Вот уже восемь лет я занимаюсь IP-телефонией. И за эти восемь лет она недостаточно раскрутилась, несмотря на свои безграничные возможности.
Вопреки повсеместному развитию мессенджеров, чатов, электронных писем ни один бизнес не обходится без самого человечного, быстрого и понятного способа общения с клиентами — голосовой связи. Менялись цены, качество, оборудование, но с 2007 года не изменилось одно: сложные настройки софтверной части и ещё более сложные настройки оборудования. Ну и по-прежнему IP-телефония не нашла свой рынок, за исключением нишевых решений, разве что в последнее время стало появляться всё больше интеграций с CRM-системами.

Сложность IP-телефонии для конечного клиента буквально лишала меня сна, я решил создать свой сервис Sipuni — простой в настройке, легко масштабируемый и сочетающий в себе все преимущества облачного сервиса и виртуальной АТС.
Вопреки повсеместному развитию мессенджеров, чатов, электронных писем ни один бизнес не обходится без самого человечного, быстрого и понятного способа общения с клиентами — голосовой связи. Менялись цены, качество, оборудование, но с 2007 года не изменилось одно: сложные настройки софтверной части и ещё более сложные настройки оборудования. Ну и по-прежнему IP-телефония не нашла свой рынок, за исключением нишевых решений, разве что в последнее время стало появляться всё больше интеграций с CRM-системами.
Сложность IP-телефонии для конечного клиента буквально лишала меня сна, я решил создать свой сервис Sipuni — простой в настройке, легко масштабируемый и сочетающий в себе все преимущества облачного сервиса и виртуальной АТС.
Git для профессионального программиста
4 min
Привет, Хаброжители!
У нас вышла новая книга С. Чакона и Б. Страуба

Эта книга представляет собой обновленное руководство по использованию Git в современных условиях. С тех пор как проект Git — распределенная система управления версиями — был создан Линусом Торвальдсом, прошло много лет, и система Git превратилась в доминирующую систему контроля версий, как для коммерческих целей, так и для проектов с открытым исходным кодом. Эффективный и хорошо реализованный контроль версий необходим для любого успешного веб-проекта. Постепенно эту систему приняли на вооружение практически все сообщества разработчиков ПО с открытым исходным кодом. Появление огромного числа графических интерфейсов для всех платформ и поддержка IDE позволили внедрить Git в операционные системы семейства Windows. Второе издание книги было обновлено для Git-версии 2.0 и уделяет большое внимание GitHub.
У нас вышла новая книга С. Чакона и Б. Страуба
Эта книга представляет собой обновленное руководство по использованию Git в современных условиях. С тех пор как проект Git — распределенная система управления версиями — был создан Линусом Торвальдсом, прошло много лет, и система Git превратилась в доминирующую систему контроля версий, как для коммерческих целей, так и для проектов с открытым исходным кодом. Эффективный и хорошо реализованный контроль версий необходим для любого успешного веб-проекта. Постепенно эту систему приняли на вооружение практически все сообщества разработчиков ПО с открытым исходным кодом. Появление огромного числа графических интерфейсов для всех платформ и поддержка IDE позволили внедрить Git в операционные системы семейства Windows. Второе издание книги было обновлено для Git-версии 2.0 и уделяет большое внимание GitHub.
Как работает реляционная БД
51 min
Tutorial
Translation
 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.На самом деле, мало кто действительно понимает, как работают реляционные БД. А многие разработчики очень не любят, когда они чего-то не понимают. Если реляционные БД используют порядка 40 лет, значит тому есть причина. РБД — штука очень интересная, поскольку в ее основе лежат полезные и широко используемые понятия. Если вы хотели бы разобраться в том, как работают РБД, то эта статья для вас.
Кластеризация СХД NetApp используя подручные свичи
9 min
Кластеризация систем хранения данных сейчас набирает оборотов, особенно в свете бурно развивающихся Flash технологий, которые требуют наличия большего количества контроллеров способных обрабатывать выскокопроизводительные накопители. Кроме поддерживаемых кластерных свичей есть множетсво других, которые временно можно исспользовать для этих целей. В этой статье я хотел бы привести пример настройки нескольких свичей, которые мною протестированны для кластерной сети. Многие другие свичи, уверен, тоже будут работать, ведь это обычный Ethernet
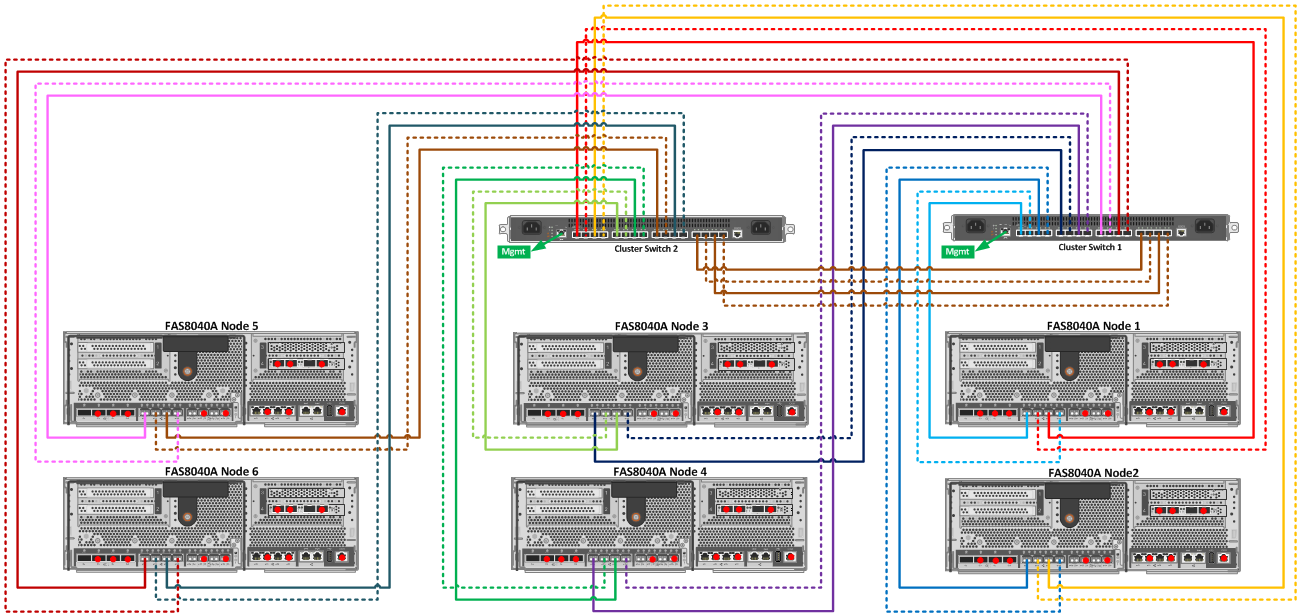
Схема подключения свичей для Cluster Interconnect
Когда у вас есть на руках (хотябы временно) больше двух контроллеров FAS, кластерный свич может понадобится, в случае:
Схема подключения свичей для Cluster Interconnect
Когда у вас есть на руках (хотябы временно) больше двух контроллеров FAS, кластерный свич может понадобится, в случае:
CHECK CONSTRAINT в MS SQL — Грабли по которым мы прошлись
9 min
Tutorial

Данная статья будет про то, как одна дружная команда веб разработчиков, не имея в своём составе опытного SQL разработчика, добавила Check Constraint в таблицу и прошлась по нескольким простым, но не сразу очевидным граблям. Будут разобраны особенности синтаксиса T-SQL, а также нюансы работы ограничений (СONSTRAINT’ов), не зная которые, можно потратить не мало времени на попытки понять, почему что-то работает не так. Так же будет затронута особенность работы SSDT, а именно как генерируется миграционный скрипт, при необходимости добавить или изменить ограничения (CONSTRAINT’ы).
Дабы читатель поскорей понял, стоит читать статью или нет, я сначала рассмотрю абстрактную задачу, по ходу решения которой будут заданы вопросы «А почему так?». Если вы сразу будете знать ответ, то смело бросайте чтение и переходите к следующей статье.
Asterisk и Truecaller. Определение имени неизвестного абонента при входящих звонках
6 min
TrueCaller — это сервис по определению имени абонента при входящих звонках, а также блокировка спама. На смартфонах с CyanogenOS 12.1 он вшит в штатную звонилку. Также можете установить себе TrueDialler/TrueCaller с GooglePlay/AppStore/BlackBerryWorld/WindowsPhoneStore.
Если вы активировали данный функционал в вашем смартфоне, то ваша книга контактов полностью слита на сервера Truecaller'а? Проверить, есть ли ваш номер в базе можно по ссылке, например: https://www.truecaller.com/ru/74996813210 (необходима аутентификация).
На данный момент сервис насчитывает 1.6 миллиарда номеров по всему миру. Выписать свой номер из базы возможно по ссылке https://www.truecaller.com/unlist.
Если вы активировали данный функционал в вашем смартфоне, то ваша книга контактов полностью слита на сервера Truecaller'а? Проверить, есть ли ваш номер в базе можно по ссылке, например: https://www.truecaller.com/ru/74996813210 (необходима аутентификация).
На данный момент сервис насчитывает 1.6 миллиарда номеров по всему миру. Выписать свой номер из базы возможно по ссылке https://www.truecaller.com/unlist.
Рефакторинг схем баз данных
19 min
Tutorial
Я хочу рассказать о рефакторинге схем баз данных MS SQL Server.
О рефакторинге кода говорят уже давно. На данный момент написано немало литературы, создано множество инструментов, помогающих выполнять рефакторинг кода.
А вот про рефакторинг схем баз данных не так уж и много информации. Я решил немного восполнить этот пробел и поделиться своим опытом.
Рефакторинг — изменение во внутренней структуре программного обеспечения, имеющее целью облегчить понимание его работы и упростить модификацию, не затрагивая наблюдаемого поведения.— Martin Fowler
О рефакторинге кода говорят уже давно. На данный момент написано немало литературы, создано множество инструментов, помогающих выполнять рефакторинг кода.
А вот про рефакторинг схем баз данных не так уж и много информации. Я решил немного восполнить этот пробел и поделиться своим опытом.
Краткая история масштабирования LinkedIn
9 min
Translation
Примечание переводчика: Мы в «Латере» занимаемся созданием биллинга для операторов связи. Мы будем писать об особенностях системы и деталях ее разработки в нашем блоге на Хабре (например, об обеспечении отказоустойчивости), но почерпнуть что-то интересное можно и из опыта других компаний. Сегодня мы представляем вашему вниманию адаптированный перевод заметки главного инженера LinkedIn Джоша Клемма о процессе масштабирования инфраструктуры социальной сети.
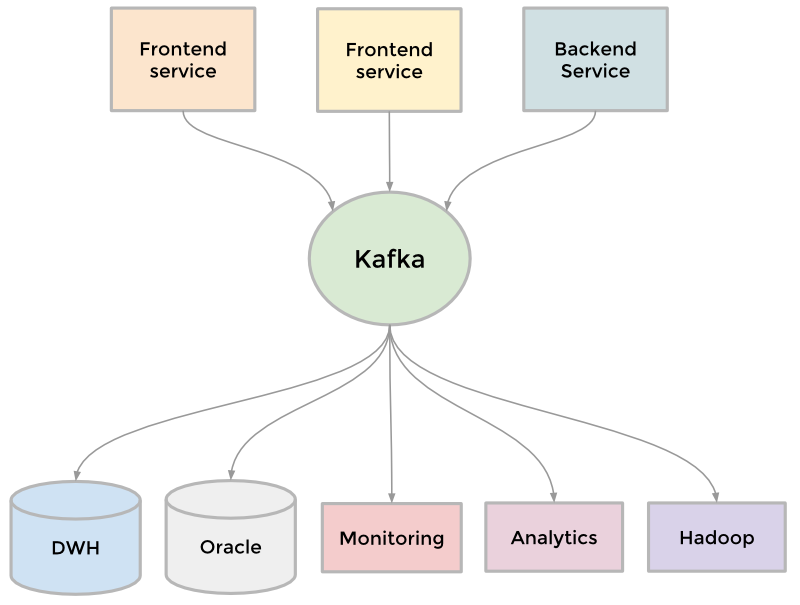
Сервис LinkedIn был запущен в 2003 году с целью создания и поддержания сети деловых контактов и расширения возможностей поиска работы. За первую неделю в сети зарегистрировалось 2 700 человек. Спустя несколько лет число продуктов, клиентская база и нагрузка на серверы заметно выросли.
Сегодня в LinkedIn насчитывается более 350 миллионов пользователей по всему миру. Мы проверяем десятки тысяч веб-страниц каждую секунду, каждый день. На мобильные устройства сейчас приходится более 50% нашего трафика по всему миру. Пользователи запрашивают данные из наших бэкенд-систем, которые, в свою очередь, обрабатывают по несколько миллионов запросов в секунду. Как же мы этого добились?
Сервис LinkedIn был запущен в 2003 году с целью создания и поддержания сети деловых контактов и расширения возможностей поиска работы. За первую неделю в сети зарегистрировалось 2 700 человек. Спустя несколько лет число продуктов, клиентская база и нагрузка на серверы заметно выросли.
Сегодня в LinkedIn насчитывается более 350 миллионов пользователей по всему миру. Мы проверяем десятки тысяч веб-страниц каждую секунду, каждый день. На мобильные устройства сейчас приходится более 50% нашего трафика по всему миру. Пользователи запрашивают данные из наших бэкенд-систем, которые, в свою очередь, обрабатывают по несколько миллионов запросов в секунду. Как же мы этого добились?
Надежное обслуживание баз MS SQL Server для занятых
12 min
Вероятно, вы знаете, что обслуживание баз данных это целый комплекс процедур: создание бэкапов, проверка целостности, обслуживание индексов, статистики и т.д. На просторах сети (да и на Хабре в том числе) на эту тему написано множество статей и рекомендаций. Однако занимаясь внедрением «1С: Предприятие», нам частенько приходится сталкиваться с тем, что обслуживание баз данных настраивается либо неправильно, либо по очень упрощённой схеме. Например, чтобы не заморачиваться с управлением журналами транзакций, для «боевых» баз устанавливается Простая модель восстановления (Simple Recovery model). И это несмотря на то, что потеря информации за пару часов уже критична для компании. Иногда задача по сжатию файлов БД включается в регулярное обслуживание («шобы не росло»), или после обновления индексов идёт уничтожение статистики и прочие подобные ляпы. Так происходит потому, что чаще всего в компаниях нет опытного администратора БД и обслуживанием приходится заниматься кому-то из сотрудников ИТ-службы – «невольному» администратору баз данных (DBA). При этом такой DBA не всегда осознаёт все риски и возложенную на него ответственность.

Как за месяц сильно прокачаться в Data Science
12 min
Привет, хабр!

Меня зовут Глеб, я долгое время работаю в ритейловой аналитике и сейчас занимаюсь применением машинного обучения в данной области. Не так давно я познакомился с ребятами из MLClass.ru, которые за очень короткий срок довольно сильно прокачали меня в области Data Science. Благодаря им, буквально за месяц я стал активно сабмитить на kaggle. Поэтому данная серия публикаций будет описывать мой опыт изучения Data Science: все ошибки, которые были допущены, а также ценные советы, которые мне передали ребята. Сегодня я расскажу об опыте участия в соревновании The Analytics Edge (Spring 2015). Это моя первая статья — не судите строго.
Меня зовут Глеб, я долгое время работаю в ритейловой аналитике и сейчас занимаюсь применением машинного обучения в данной области. Не так давно я познакомился с ребятами из MLClass.ru, которые за очень короткий срок довольно сильно прокачали меня в области Data Science. Благодаря им, буквально за месяц я стал активно сабмитить на kaggle. Поэтому данная серия публикаций будет описывать мой опыт изучения Data Science: все ошибки, которые были допущены, а также ценные советы, которые мне передали ребята. Сегодня я расскажу об опыте участия в соревновании The Analytics Edge (Spring 2015). Это моя первая статья — не судите строго.
Продать за 60 секунд. Call-центр в облаке и специальная сим-карта
5 min
Про колл-центры, облачные, безоблачные и заоблачные, написано очень много и каждый, кто берется выдать на гора «еще один крутой материал про облачный колл-центр» практически наверняка задается вопросом — « чего бы еще такого выдумать, чтобы выглядеть достойнее своих конкурентов?» Честно говоря, при написании этого хаба мы озадачились абсолютно тем же, но сомнения не длились долго, поскольку, как минимум, одна «киллер фича» у нас все-таки есть — это тесная и навороченная интеграция VoIP-технологий и корпоративной мобильной связи. Помимо этого, наша облачная АТС AltegroCloud сама по себе достаточно любопытный продукт, хотя бы потому, что еще на стадии проработки проекта, мы решили не использовать соблазнительно моргающий светодиодами сервер с бесплатным Астериском внутри и не только из-за бесплатности сыра, но и по ряду технологическо-идеологических причин. Иногда лучше, когда за тебя работают другие, а ты просто оплачиваешь работу, но работа выполняется качественно и в срок. С точки зрения эксплуатации платформа от уважаемого вендора, пусть и платная, всегда лучше чистокровного, пусть даже и породистого, опенсорса.

Налаживаем коммуникацию между клиентом и UX: как избежать испорченного телефона
5 min
Tutorial
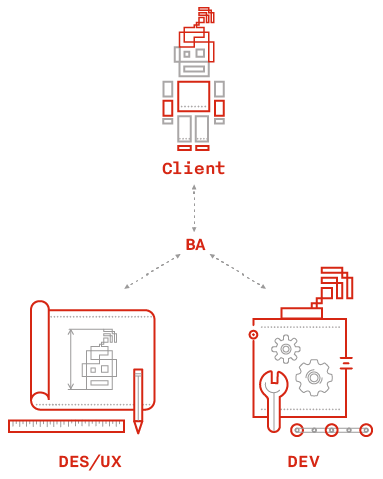 Аналитик — арбитр между бизнесом, проектированием и разработкой, который периодически смещается в ту или иную сторону, но при этом удерживает процесс создания мобильного продукта в поле здравого смысла. Он обеспечивает коммуникацию между всеми участниками процесса, транслируя знания от одной группы в другую, чтобы выдвинутые гипотезы и принятые впоследствии решения были обеспечены достаточным количеством информации.
Аналитик — арбитр между бизнесом, проектированием и разработкой, который периодически смещается в ту или иную сторону, но при этом удерживает процесс создания мобильного продукта в поле здравого смысла. Он обеспечивает коммуникацию между всеми участниками процесса, транслируя знания от одной группы в другую, чтобы выдвинутые гипотезы и принятые впоследствии решения были обеспечены достаточным количеством информации.- Бизнес — всегда думает о достижении своих KPI, но редко понимает сложность разрабатываемой системы и удобство для пользователей.
- UX-проектировщик — всегда думает о пользователе, иногда в ущерб бизнесу. Не всегда явно понимает цель бизнеса и пытается навязывать свои идеи.
- Разработчик — думает, как сделать все классно с точки зрения архитектуры системы и программного кода. Пытается примерять пользовательские сценарии на себя, но является технически подкованным человеком, что не свойственно для большинства пользователей.
Asterisk. Начало
10 min
На написание этой статьи меня побудило практически полное отсутствие how-to по настройке Астериска, с понятными новичку примерами. В сети можно найти кучу информации по настройке IVR, по настройке авторизации SIP-пользователей через LDAP, мануалов по созданию HA-кластеров с Астерисками внутри, etc., но нет ни одной статьи о том, как завести его с нуля, да и еще с примерами. Практически везде предлагается сразу же использовать все возможности, которые предлагает Астериск, а если убрать часть функционала, предлагаемого в мануале, то в большинстве случаев это приведет к получению неработоспособной конструкции. Эта статья — результат хождения по граблям… чтения мануалов. Если вы находитесь в такой же ситуации, что и я пару лет назад — добро пожаловать под кат.
Автоматизация настройки резервного копирования MS SQL с помощью .NET приложения
13 min
Я долго созревал, чтобы написать данную статью и выложить свое приложение. Надеюсь вам будет интересно.
В ней описан тот способ, как с помощью разработанного мною .NET приложения можно распространять план резервного копирования и проводить все необходимые настройки над БД средствами СУБД с уведомлением администратора о выполнении задач.
По максимум постараюсь описать те нюансы, с которыми мне пришлось столкнуться в ходе разработки приложения и настройки БД.
Для описанных ниже задач можно использовать мастер планов обслуживания, но мне больше понравился такой подход. Основное преимущество описанного мною метода, что данный способ можно применять ко всем версиям MS SQL (кроме Express, там немного другой подход). План обслуживания можно переносить, но у вас должна быть соответствующая в версия MS SQL и все равно будет создан Job для запуска плана обслуживания.
Сравнить редакции MS SQL и их функционал вы можете вот здесь.
Осторожно: перфекционисты могут испытать жжение и боль при просмотре кода моего приложения, т.к. оно было написано на скорую руку и заточено под решение конкретной задачи.
Кому подойдет данная статья:
Оглавление:
Теория о резервном копирование
Используем приложение
Как восстанавливать резервные копии
О чем данная статья
В ней описан тот способ, как с помощью разработанного мною .NET приложения можно распространять план резервного копирования и проводить все необходимые настройки над БД средствами СУБД с уведомлением администратора о выполнении задач.
По максимум постараюсь описать те нюансы, с которыми мне пришлось столкнуться в ходе разработки приложения и настройки БД.
Для описанных ниже задач можно использовать мастер планов обслуживания, но мне больше понравился такой подход. Основное преимущество описанного мною метода, что данный способ можно применять ко всем версиям MS SQL (кроме Express, там немного другой подход). План обслуживания можно переносить, но у вас должна быть соответствующая в версия MS SQL и все равно будет создан Job для запуска плана обслуживания.
Сравнить редакции MS SQL и их функционал вы можете вот здесь.
Осторожно: перфекционисты могут испытать жжение и боль при просмотре кода моего приложения, т.к. оно было написано на скорую руку и заточено под решение конкретной задачи.
Кому подойдет данная статья:
- Тем, у кого MS SQL Express и нет возможности запускать с помощью Job задачи
- Тем, кто в ближайшем будущем планирует перейти с MS SQL 2008 на более новую версию и не хочет настраивать зеркалирование БД, а сразу на новой версии настроить AlwaysOn
- Тем, у кого нет средств для поднятия еще резервных серверов и приходится обходиться тем, что есть.
- У кого нет сжатых сроков на время восстановления БД. Главное – это результат
- Кому лень что-то делать
- Просто любопытным людям.
Оглавление:
Теория о резервном копирование
- Журнал транзакций
- Разностная копия БД
- Системные базы данных
- План бекапирования
- Общие рекомендации по резервному копированию
Используем приложение
- Настройка уведомления администратора
- Дополнительные уведомления для администратора
- Решение проблем при настройке DatabaseMail
- Настраиваем резервное копирование с помощью приложения для SQL Standart
- Настраиваем резервное копирование с помощью приложения для SQL Express
- Удаление задач из БД
- Удаление копий БД
Как восстанавливать резервные копии
Медиана: точно, иногда точно и почти точно
5 min
Если пройтись по коллегам и спросить сколько у них сотовых телефонов, то окажется, что в среднем их около 2.5, но при этом у подавляющего большинства их не больше одного. Тут возникает сразу множество вопросов начиная от того, почему их вдруг не целое число и как же все-таки оценить сколько телефонов в среднем у человека.

Для таких целей подойдет оценка медианы. То есть такая статистика, что половина значений выборки меньше, а половина больше. Более формально: упорядочим значения выборки) по порядку
по порядку ![(x_{[1]}, ..., x_{[n]})](http://tex.s2cms.ru/svg/(x_%7B%5B1%5D%7D%2C%20...%2C%20x_%7B%5Bn%5D%7D)) и выберем среди них с порядковым номером
и выберем среди них с порядковым номером ) . У такой оценки есть несколько преимуществ. Она менее подвержена влиянию ошибочных данных, значение всегда будет из того множества, что встречалось в выборке, но есть и неприятные недостатки, главный из них, это сложность подсчета, даже для довольно распространенных распределений не существует общей формулы расчета (точнее есть, но ее сложно применить на практике, смотрите Распределение порядковой статистики).
. У такой оценки есть несколько преимуществ. Она менее подвержена влиянию ошибочных данных, значение всегда будет из того множества, что встречалось в выборке, но есть и неприятные недостатки, главный из них, это сложность подсчета, даже для довольно распространенных распределений не существует общей формулы расчета (точнее есть, но ее сложно применить на практике, смотрите Распределение порядковой статистики).
Для таких целей подойдет оценка медианы. То есть такая статистика, что половина значений выборки меньше, а половина больше. Более формально: упорядочим значения выборки