Всем привет.
С середины 2016 года мы проектируем и разрабатываем новое поколение платформы. Принципиальное отличие от первого поколения — поддержка API "тонкого" клиента. Если старая платформа предполагает, что на клиента при запуске загружается метаинформация о всем контенте, который доступен для абонента, то новая платформа должна отдавать срезы данных отфильтрованные и отсортированы для отображения на каждом экране/странице.
Высокоуровневая архитектура на уровне хранения данных внутри системы — постоянное хранение всех данных в централизованном реляционном SQL хранилище. Выбор пал на Postgres, тут никаких откровений. В качестве основного языка для разработки — выбрал golang.
У системы порядка 10м пользователей. Мы посчитали, что с учетом профиля теле-смотрения, 10М пользователей может дать сотни тысяч RPS на всю систему.

Это означает, что запросы от клиентов и близко не стоит подпускать к реляционной SQL БД без кэширования, а между SQL БД и клиентами должен быть хороший кэш.
Посмотрели на существующие решения — погоняли прототипы. Данных, по современным меркам у нас немного, но параметры фильтрации (читай бизнес-логика) — сложные, и главное персонализированные — зависящие от сессии пользователя, т.е. использовать параметры запроса как ключ кэширования в K-V кэше будет очень накладно, тем более пейджинг и богатый набор сортировок никто не отменял. По сути, под каждый запрос от пользователя формируется полностью уникальный набор отфильтрованных записей.

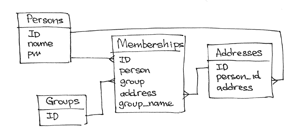 Одна из самых разрекламированных фич MongoDB — это гибкость. Я сам не раз подчеркивал это в бесчисленных разговорах о MongoDB. Однако, гибкость — это палка о двух концах: большая гибкость подразумевает более широкий выбор решений для моделирования данных. Тем не менее, мне нравится гибкость, которую предоставляет MongoDB, просто нужно иметь ввиду некоторые рекомендации, прежде чем начать разрабатывать модель данных.
Одна из самых разрекламированных фич MongoDB — это гибкость. Я сам не раз подчеркивал это в бесчисленных разговорах о MongoDB. Однако, гибкость — это палка о двух концах: большая гибкость подразумевает более широкий выбор решений для моделирования данных. Тем не менее, мне нравится гибкость, которую предоставляет MongoDB, просто нужно иметь ввиду некоторые рекомендации, прежде чем начать разрабатывать модель данных.