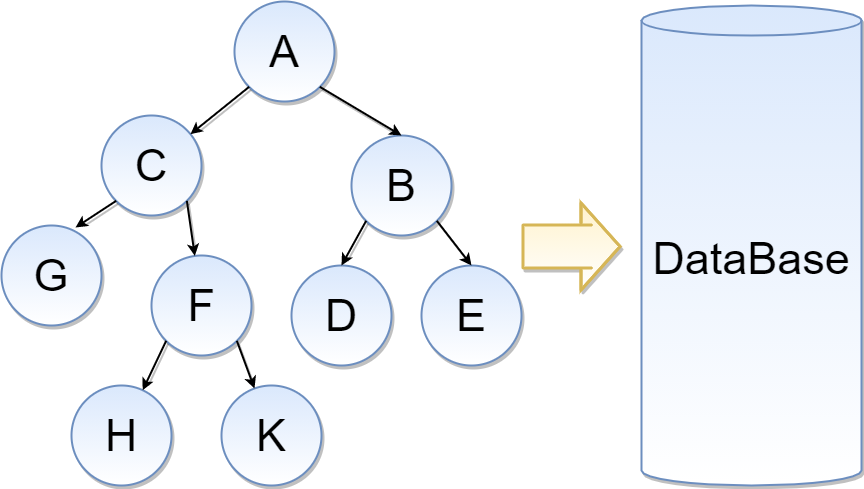
Здравствуйте! В этой статье, я постараюсь кратко рассказать о четырёх достаточно известных способах хранения деревьев с указанием преимуществ и недостатков. На идею написать подобную статью подтолкнул не раз слышимый мною вопрос: "А как это будет в Hibernate?", то есть как реализовать какой-либо из способов хранения дерева с использованием ORM Hibernate. Сразу замечу, что данная статья не является каким-либо призывом использовать именно реляционные БД для решения задач связанных с деревьями, так как понятно что реляционные базы не заточены конкретно для целей хранения\обработки таких данных. Для иерархии подходят и используются графовые базы данных. Поэтому эта статья будет полезная тем, кому необходимо по каким-либо причинам реализовать хранение дерева именно в реляционной БД. Необходимо также отметить, что и ORM Hibernate также не содержит каких-либо готовых решений из коробки для хранения\обработки деревьев по крайней мере на данный момент, поэтому реализация таких решений практически полностью ложиться на плечи разработчика. В примерах далее для полной и целостной картины, кроме сущностей(entity), рассмотрим кратко и такие базовые операции, как получение всех потомков с уровнем вложенности, получение всех родителей с уровнем вложенности, а также операции добавления, удаления и перемещения узла в дереве. В качестве примера дерева послужит структура папок на файловой системе, которая будет отражена в таблицах(е) БД. На такие моменты, как инициализация сущности(entity) не будем акцентировать внимание, полагаю что рассматривать это не имеет смысла, так как алгоритмы обхода дерева известны и описаны во многих книгах и публикациях и будут мало кому интересны. В любом случае мои реализации обхода дерева представлены на GitHub и с ними при желании можно ознакомиться.