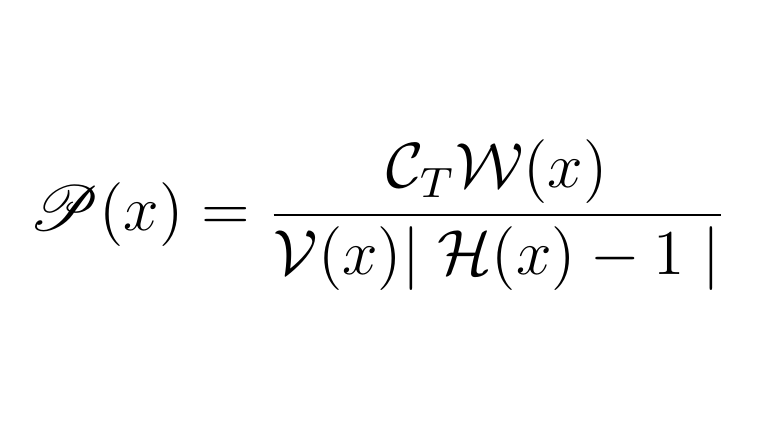Программисты постоянно стараются сделать код лучше, используя для этого различные практики. Однако само понятие хорошего кода крайне расплывчато, о чём свидетельствует одно только количество книг, посвящённых этой теме, а также их объём. Например, книга "Чистый код'' Р. Мартина содержит почти 500 страниц. Неужели нет возможности выразить хотя бы основные критерии хорошего кода короче?
Чтобы обнаружить такие критерии, нужно обратить внимание на тот факт, что программирование есть отражение мышления. Целесообразно поискать критерии хорошего кода в модели, которая описывает ключевые моменты этого явления.
Основными функциями мышления являются рассуждение и балансировка.
Под рассуждением понимаются действия, связанные со структурами, а именно синтез (конструирование) и анализ (декомпозиция). Под балансировкой понимается нахождение оптимального решения между двумя крайними случаями.
Кроме того, для мышления необходимы память и время. Любая модель мышления (модель вычислений) обязана включать эти два понятия. Действительно, в машине Тьюринга роль памяти играет лента, а роль времени – головка. Аналогично, в современном компьютере эти две роли выполняют RAM и CPU, соответственно.
Итак, в нашем распоряжении три аспекта, относящиеся к мышлению: рассуждение, балансировка и природа памяти/времени. Эти аспекты напрямую относятся к самой сути программирования. Каждый из этих аспектов несёт в себе математику, которая и будет использоваться для вывода критериев хорошего кода.