Кластеры Patroni 4.0.7 и etcd 3.6.5 в docker-контейнерах
Medium
13 min
Tutorial

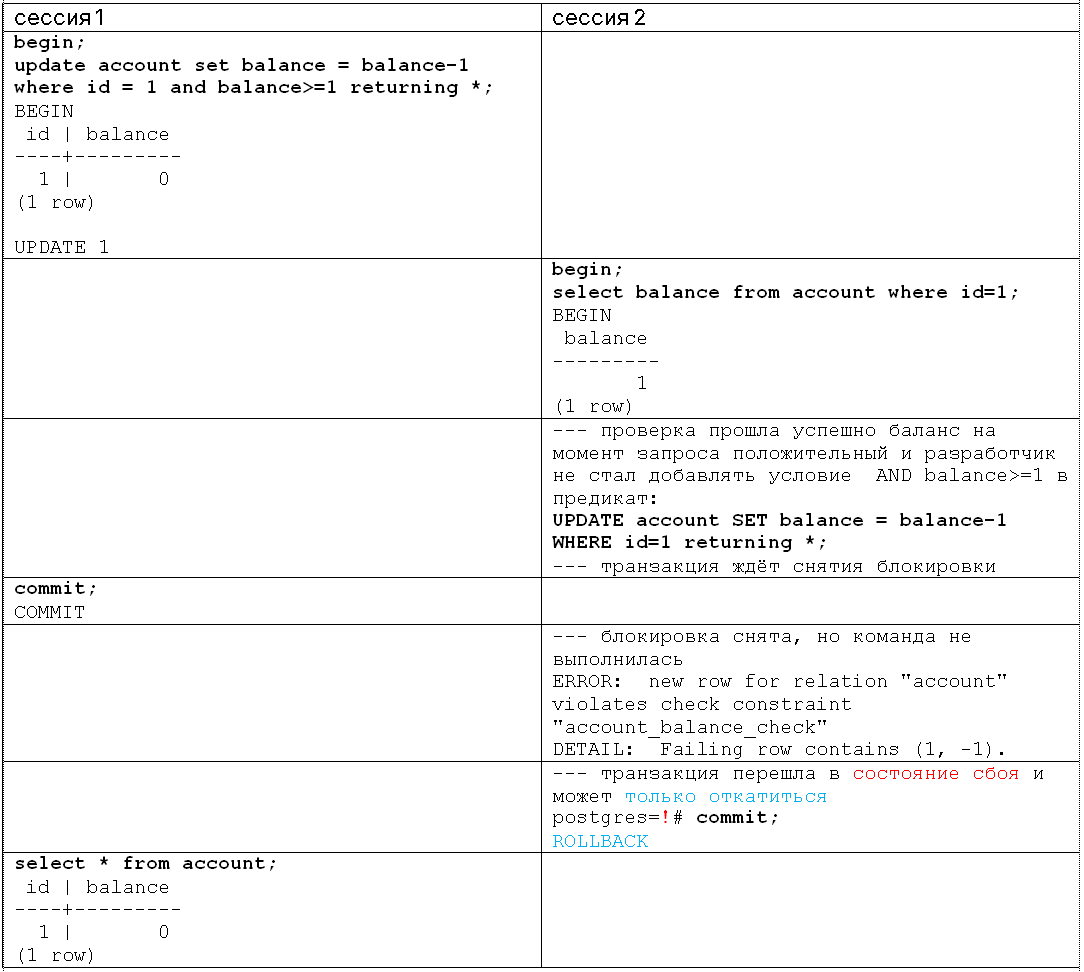
В статье рассматривается создание кластера Patroni последней версии 4.0.7 и etcd 3.6.5 в контейнерах docker. Приводится пример, когда Patroni не может автоматически восстановить и запустить кластер PostgreSQL.
Patroni в докере
Задача запуска Patroni в докере обсуждалась на реддит и гитхаб. Приводился пример наиболее простой сборки batonogov/patroni-docker, которая состоит из 7 контейнеров: трёх с кластером etcd и трёх с PostgreSQL 17 под управлением Patroni (мастер и две реплики), один контейнер с HAProxy.