
Я работаю архитектором. Последние лет 5 я довольно много работаю с разными enterprise компаниями и я довольно интенсивно вовлечен в процесс дизайна архитектуры. Хочу написать об устойчивом паттерне повторяющемся из компании в компанию.

User
Я работаю архитектором. Последние лет 5 я довольно много работаю с разными enterprise компаниями и я довольно интенсивно вовлечен в процесс дизайна архитектуры. Хочу написать об устойчивом паттерне повторяющемся из компании в компанию.
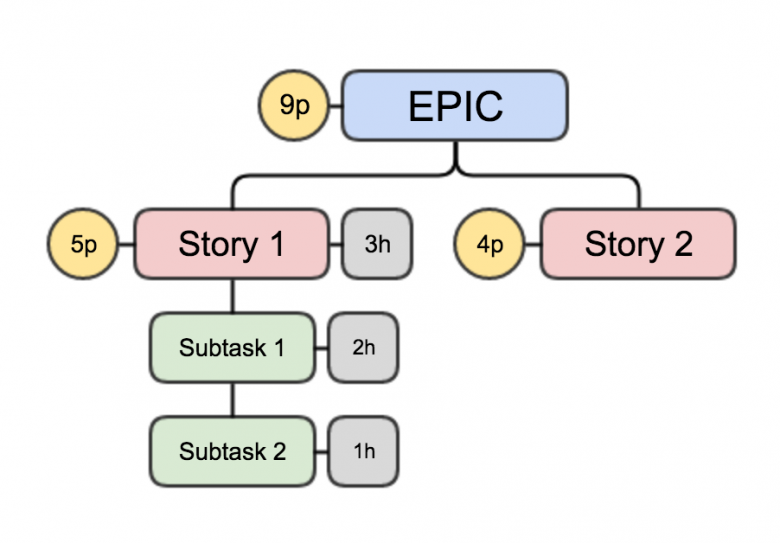
Я сейчас занимаюсь тем, что помогаю акаунту в несколько десятков разработчиков зарелизить проект качественно и в срок. Среди прочего у проекта есть проблема с разбиением задач на тикеты в JIRA. Просто для понимания масштаба – проекту год, разработчиков грубо говоря три дюжины, номер последнего тикета 12000+. При этом много тикетов с тегов investigate, много тикетов в результате которых создается pull request на 20 строк при том, что для достижения результата который «можно пощупать руками» (tangible) нужно 100 строк и остальные 80 строк размазаны по другим спринтам и другим командам. Это ведет к следующим проблемам

Последнее время я достаточно часто участвую в проектах, где надо не придумать архитектуру с нуля, а исправить то, что уже придумали и уже почти год-два-три разрабатывают. Желающих и что более важно убедительно рассказывающих как правильно делать дизайн архитектуры большой системы с нуля полно. По разным причинам, далеко не всегда такое заканчивается успешным релизом. Так сложилось, уже, наверное, последние лет 6-7, 80% моей активности это участие в проектах где «мы тут придумали классную систему и год над ней работаем, а теперь надо чтобы она заработала». Симптомы почти в каждом таком проекте одни и те же

В статье я хочу рассмотреть влияние разных факторов на сходимость проектов. Под сходимостью в данном случае я понимаю способность команды сдать проект в срок, уложившись в бюджет. По понятным причинам тема эта достаточно популярная и часто обсуждаемая. Как правило те обсуждения, которые я видел, сводились к следующим пунктам:

Вчера увидел вот этот пост в LinkedIn с фразой «First rule of programming, If it works, don't touch it» и как-то вскипело. Поясню почему.

Я работаю архитектором (Solution Architect если быть точным) в аутсорсинговой компании. В ходе работы я занимаюсь такими активностями как: дизайн и внедрение архитектурных решений, аудит систем заказчика и разного рода консультации вокруг архитектуры систем.
Иногда в разговоре с коллегами я говорю «спокойно, действуем ровно по учебнику». Но тут есть большая доля лукавства, т.к. одной книги где были бы собраны базовые принципы я так с ходу назвать не могу. По большей части это сборная солянка из разных книг, личного опыта и историй, рассказанных коллегами. Что-то освещено в одной из книг Фаулера, что-то есть в курсах от AWS.
В статье я решил собрать вместе список общих принципов, которых я стараюсь придерживаться, приступая к очередной задаче.
В IT индустрии есть одна достаточно часто встречающаяся не простая проблема. Это старые монолитные приложения, которые приносят их текущим владельцам много денег прямо сейчас. Обычно эти приложения экстенсивно развивались долгие годы или даже десятки лет и достигли предела экстенсивного развития, когда даже далекие от техники люди в бизнесе понимают, что дальше так жить нельзя.
Выбросить такой монолит невозможно, бизнес остановится. Переписать тоже либо нельзя, либо очень дорого, по причинам хорошо описанным еще у Фредерика Брукса в Мифическом человеко-месяце. Во первых как они там под капотом работают в точности, по прошествии 20+ лет уже никто не знает. Во вторых, пока приложение переписывается, а обычно это 1-2 года, бизнес успевает уйти вперед и новое приложение надо докатывать до актуального состояния и так без конца.
На данный момент в таких случаях обычно используются два возможных подхода. Либо сделать новый продукт, с похожим, но все же новым функционалом. Либо распилить монолит на несколько достаточно небольших сервисов, а уже их постепенно переписывать.
Несколько лет назад к нам пришел заказчик с нераспиливаемым монолитом и необходимостью реализовать ряд новых нефункциональных требований как можно скорее. В статье я хочу рассказать, как мы с такой ситуаций справлялись.