
Создаем простую систему RAG на Python

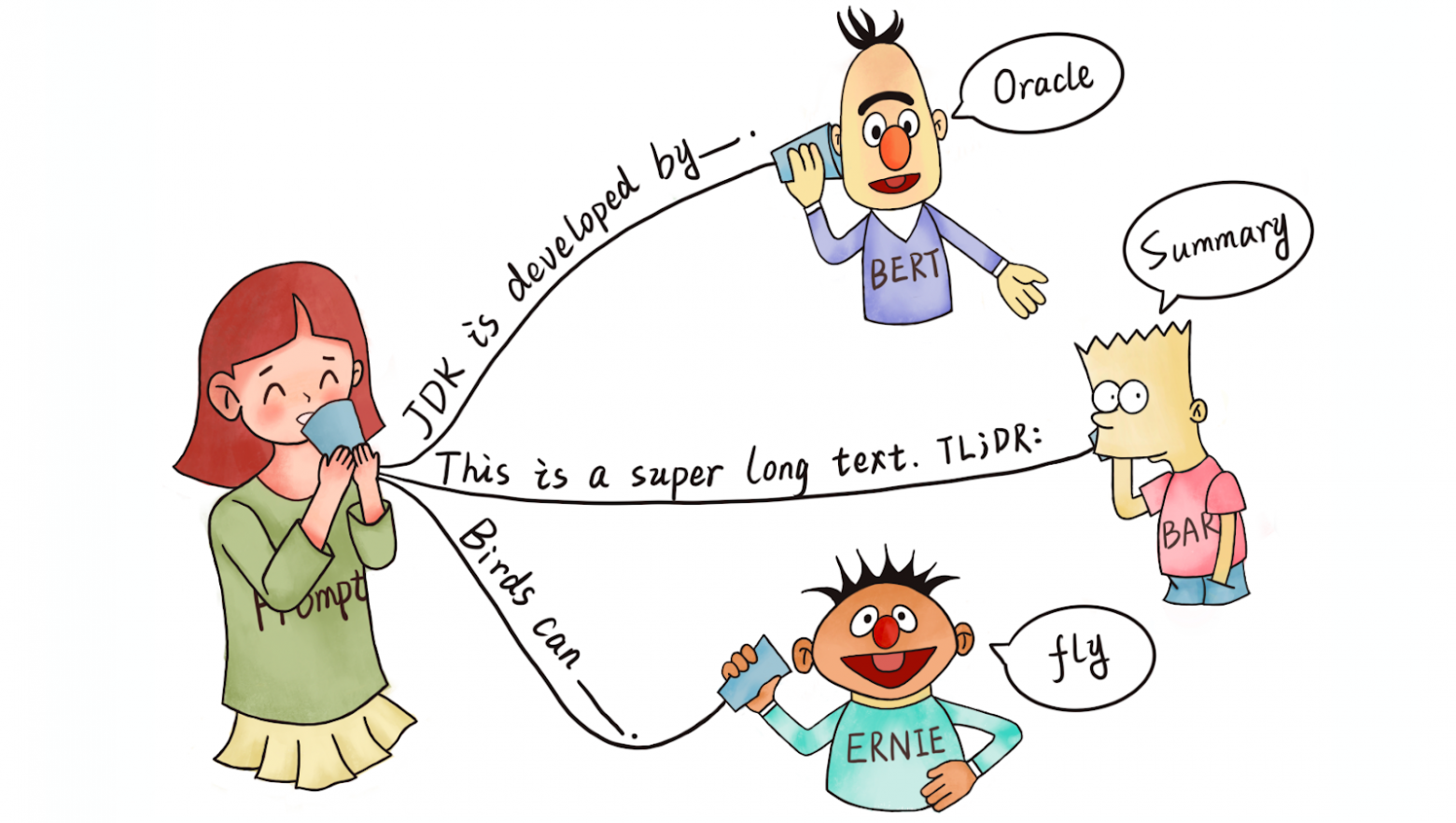
Представьте, что вы предоставляете своему ИИ конкретные релевантные документы (или фрагменты), которые он может быстро просмотреть, чтобы найти необходимую информацию, прежде чем ответить на ваши вопросы. То есть, вместо поиска по всей базе данных (которая может не поместиться в контекстное окно модели LLM, или даже если поместится, это потребует много токенов для ответов), мы предоставляем LLM только релевантные документы (фрагменты), которые ему необходимо найти, чтобы ответить на вопрос пользователя.
Для того, чтобы решить эту проблему, мы построим простую систему RAG (Retrieval-Augmented Generation) – в которой генеративная языковая модель (LLM) получает доступ к внешним источникам информации для улучшения точности и достоверности ответов. То есть, вместо того чтобы использовать только внутренние знания модели, RAG будет обращаться к внешним источникам: базам данных, текстовым архивам и другим.









 7 сентября 2021 года мне пришло электронное письмо:
7 сентября 2021 года мне пришло электронное письмо: