
Кроссдоменные запросы с помощью YQL
Как клиентский веб разработчик, я всегда хочу уменьшить расходы потребления серверных ресурсов. Может быть, я один такой, не знаю. Но есть группа задач, которые просто-напросто не реализуемы на стороне клиента. Одна из таких задач: запрос на чужой домен. Нам приходится создавать серверный скрипт, который выступает посредником между браузером и сервером, с которого хотим стянуть данные, отдавая данные как бы со своего домена.
Позавчера, один уважаемый человек с форума javascript.ru с ником melky вскользь упомянул о каком-то странном, на первый взгляд, jQuery плагине, который называется jquery.xdomainajax.js
Пытливому уму программиста не нравятся всякие плагины, без понимания сути, поэтому я выковырял самую нужную часть:
var query = 'select * from html where url="http://javascript.ru/" and xpath="*"'
var url = 'http://query.yahooapis.com/v1/public/yql?q='+encodeURI(query)+'&format=xml&callback=callback';
var script = document.createElement('script');
script.src = url;
document.body.appendChild(script);
function callback(data) {
console.log(data); //сам текст ответа находится в data.result[0]
}Откройте консоль и зупустите код. Как видно, в запрос пихается урл сайта и XML запрос в виде xpath, ответ приходит в виде jsonp. Если в урле написать format=json, то ответ придет в виде объекта с тегами.
Дальше этого применения я не пошел, поэтому лучше сами изучите матчасть здесь: developer.yahoo.com/yql
В комментариях настаивают указать на ограничения по количеству запросов с одного IP и запросов, использующих accesskey, которого у нас нет (так что, скорее всего, можно забить :) ).

 Вкратце: статья будет полезна тем программистам, кто уже заинтересовался релевантным поиском и прочитал статьи по стартовой установке сфинкс поиска, погонял на тестовых примерах и таких же синтетических задачах. Часто эти примеры не дают ответа на вопрос, а как же ощутить реальную пользу от поискового модуля Sphinx в сравнении с другими более простыми вариантами поиска. Примеры кода в статье — на php+smarty, Sphinx 2.0.1-beta, база данных — mysql, исходники и дамп структуры базы выложены отдельным архивом в подвале. В статье описан пример использования таких особенностей сфинкса, как:
Вкратце: статья будет полезна тем программистам, кто уже заинтересовался релевантным поиском и прочитал статьи по стартовой установке сфинкс поиска, погонял на тестовых примерах и таких же синтетических задачах. Часто эти примеры не дают ответа на вопрос, а как же ощутить реальную пользу от поискового модуля Sphinx в сравнении с другими более простыми вариантами поиска. Примеры кода в статье — на php+smarty, Sphinx 2.0.1-beta, база данных — mysql, исходники и дамп структуры базы выложены отдельным архивом в подвале. В статье описан пример использования таких особенностей сфинкса, как:
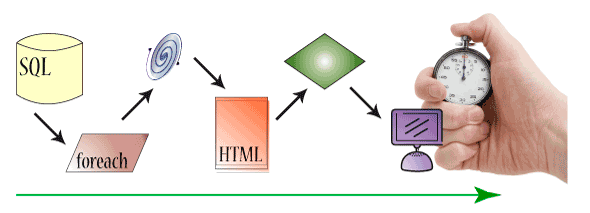

 Наверное любой современный веб-проект сложно себе представить без… без контента! Да, именно контент в разных его проявлениях сегодня «правит бал» в различных веб-проектах. Не так важно — создаваемый пользователями или получаемый из других источников автоматически — информация является основной любого (ну, или почти любого) проекта. А раз так — то вопрос поиска необходимой информации стоит очень остро. И острее с каждым днем, ввиду стремительного расширения количества этого самого контента, в основном за счёт создаваемого пользователями (это и форумы, и блоги и модные нынче сообщества, вроде
Наверное любой современный веб-проект сложно себе представить без… без контента! Да, именно контент в разных его проявлениях сегодня «правит бал» в различных веб-проектах. Не так важно — создаваемый пользователями или получаемый из других источников автоматически — информация является основной любого (ну, или почти любого) проекта. А раз так — то вопрос поиска необходимой информации стоит очень остро. И острее с каждым днем, ввиду стремительного расширения количества этого самого контента, в основном за счёт создаваемого пользователями (это и форумы, и блоги и модные нынче сообщества, вроде 