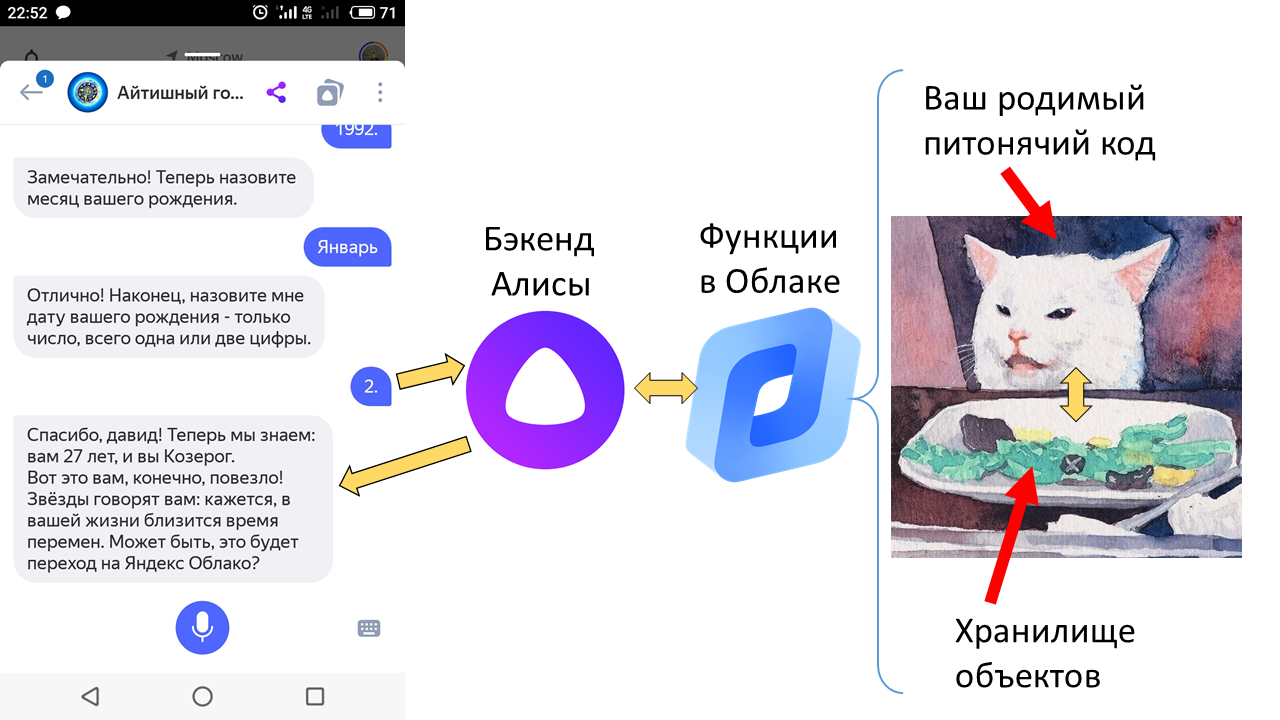
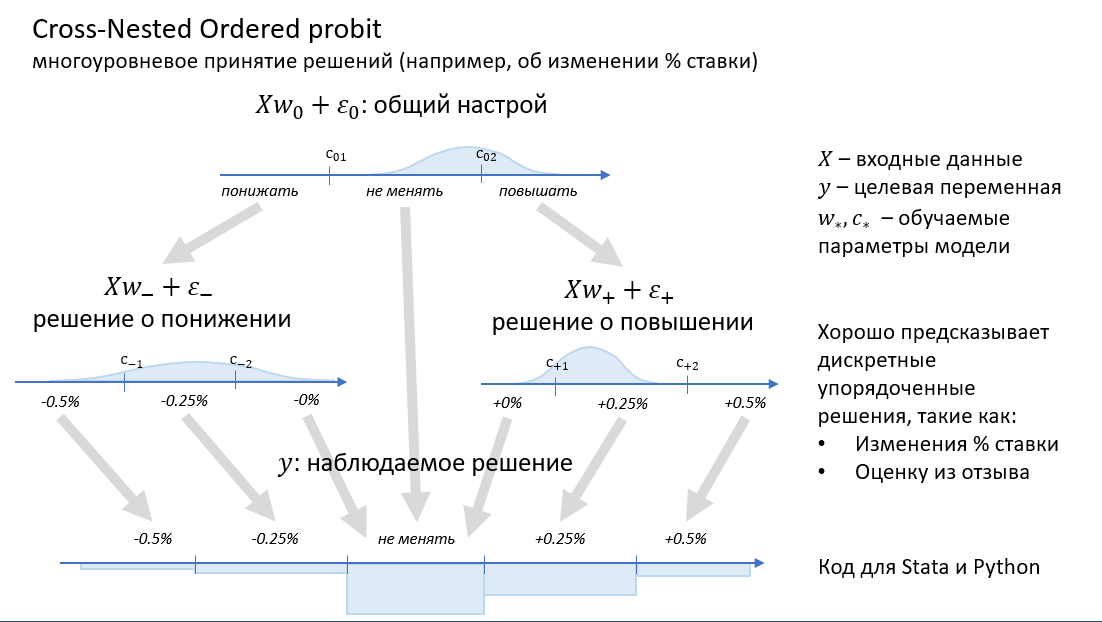
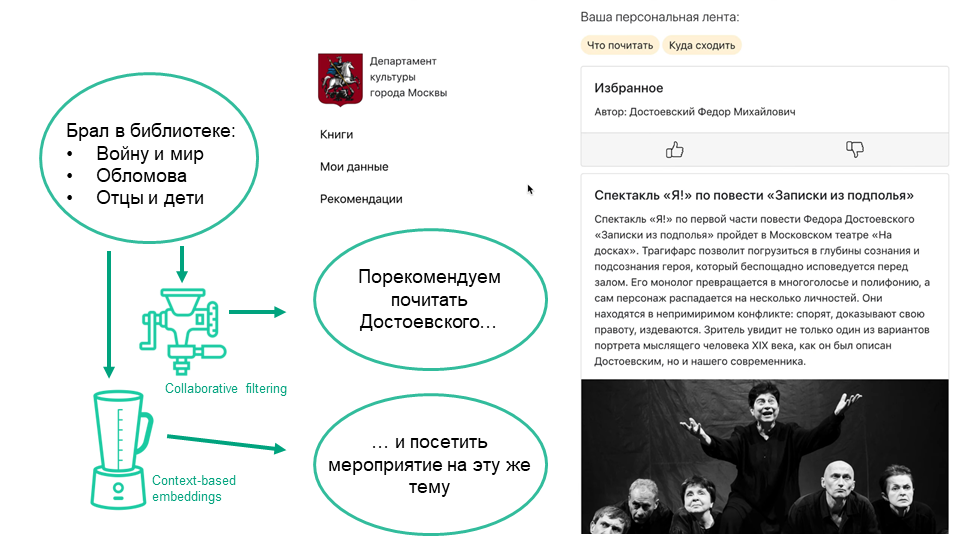
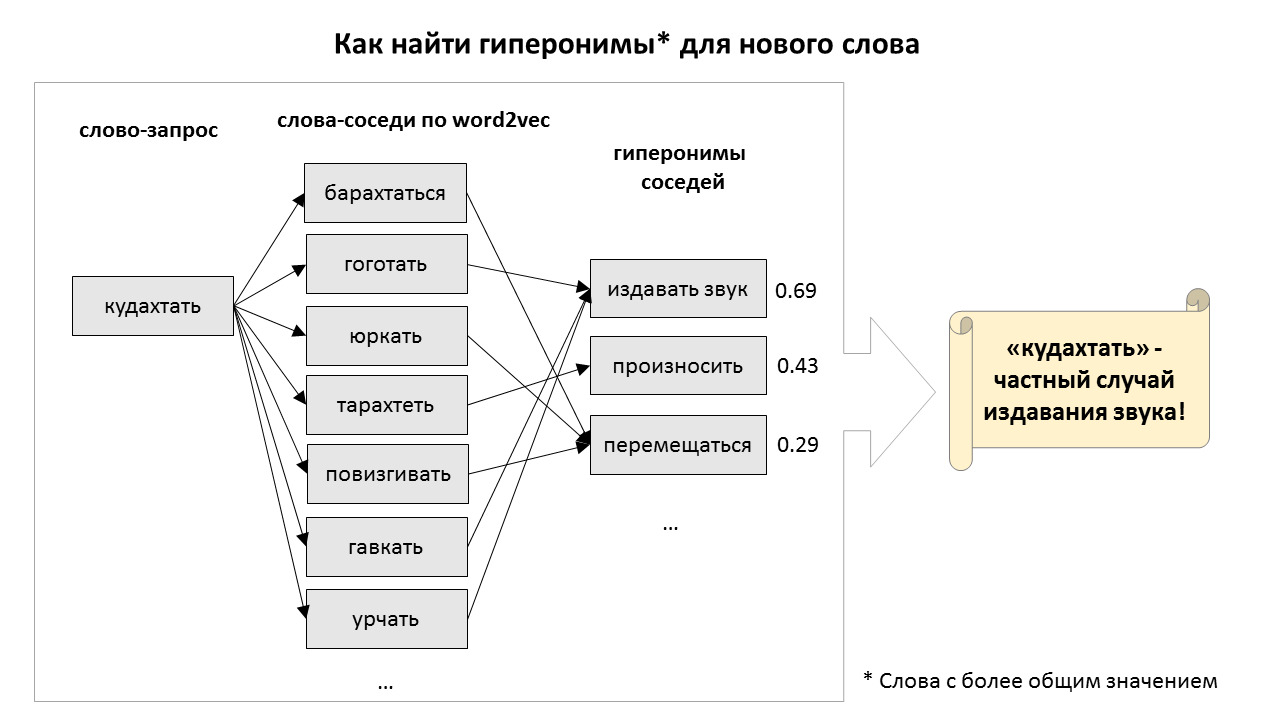
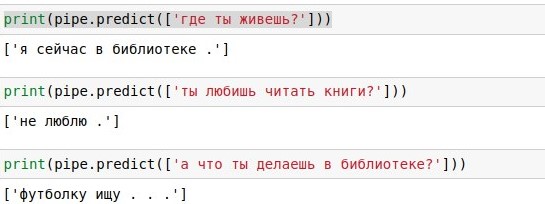
Начнём с новостей. Вчера Яндекс.Облако анонсировало запуск сервиса бессерверных вычислений Yandex Cloud Functions. Это значит: ты пишешь только код своего сервиса (например, веб-приложения или чатбота), а Облако само создаёт и обслуживает виртуальные машины, где он запускается, и даже реплицирует их, если возрастает нагрузка. Думать вообще не надо, очень удобно. И плата идёт только за время вычислений.
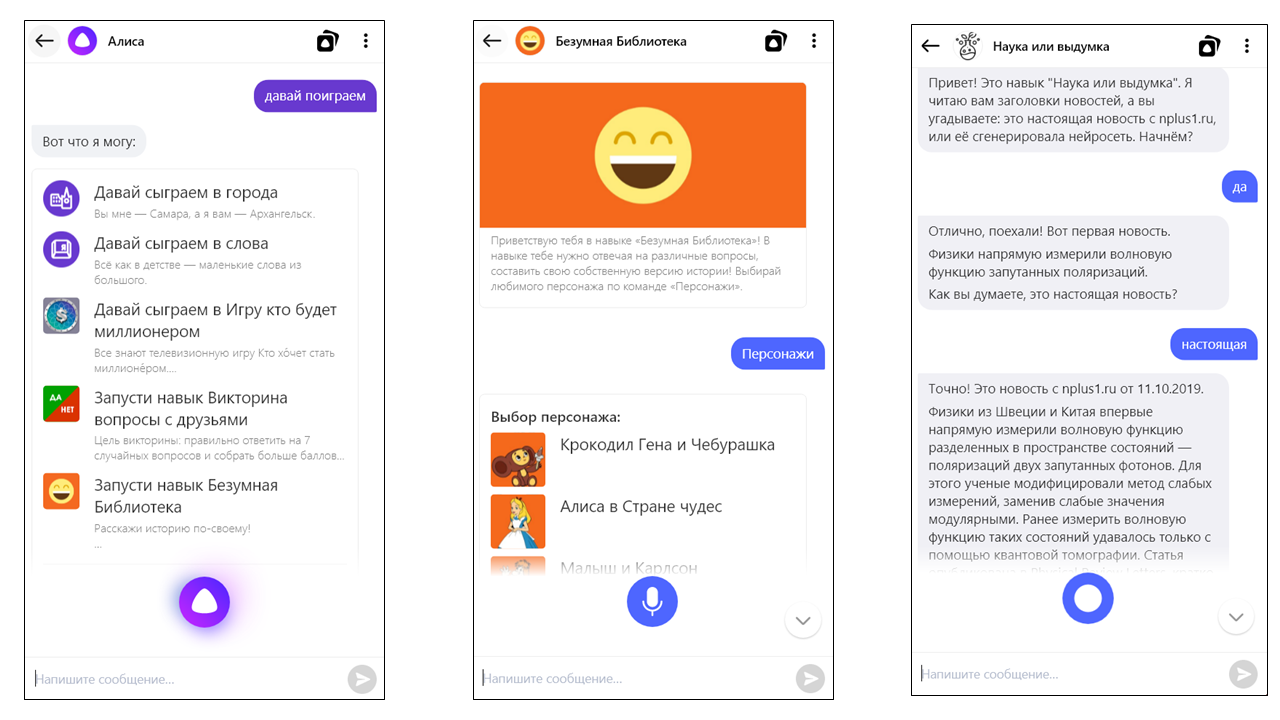
Впрочем, кое-кто может вообще не платить. Это — разработчики внешних навыков Алисы, то есть встроенных в неё чатботов. Написать, захостить и зарегистрировать такой навык может любой разработчик, а с сегодняшнего дня навыки даже не надо хостить — достаточно залить их код в облако в виде той самой бессерверной функции.
Но есть пара нюансов. Во-первых, ваш питонячий код может требовать каких-то зависимостей, и затаскивать их в Облако — нетривиально. Во-вторых, любому нормальному чатботу нужно хранить где-то состояние диалога (stateful поэтому); как сделать это в бессерверной функции проще всего? В третьих, а как вообще можно быстро-грязно написать навык для Алисы или вообще какого-то бота с ненулевым сюжетом? Об этих нюансах, собственно, статья.