Наверное все уже и так знают, что всегда хорошо иметь большой и сложный пароль. Многие так же знают про менеждеры паролей и как удобно, а главное безопасно можно хранить в них информацию.
По специфике моей работы мне часто приходится записывать и хранить большое количество паролей и другой конфиденциальной информации, поэтому я пользуюсь Keepass2 — менеджером паролей со свободной лицензией. Я не стану рассказывать о его возможностях и преимуществах перед другими, все это и так уже обсуждалось не раз. Если кто хочет познакомиться подробнее, вот несколько ссылок: wiki, обзорная статья, сравнения с другими: 1 2.
Вместо этого я хотел бы рассказать об одной его интересной функции:
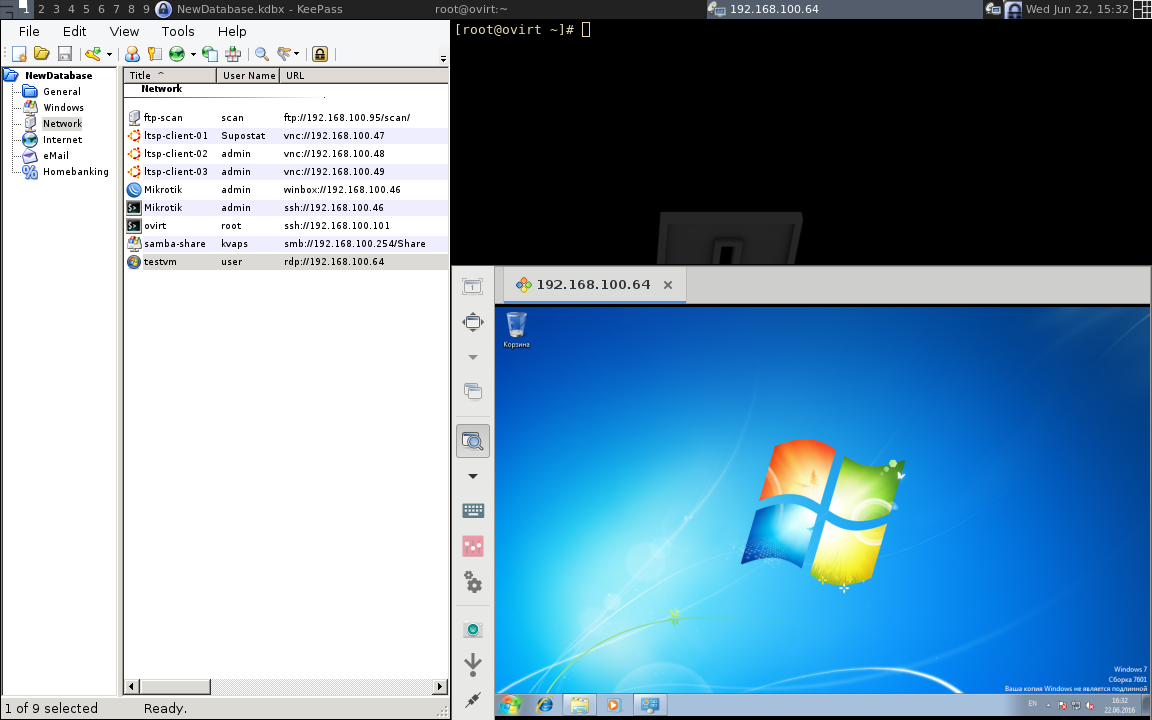
Функция называется "URL Overrides", и представляет ссобой возможность запускать ассоциированные с записями программы и передавать им данные для аутентификации прямо из Keepass'а.
Например, вы можете хранить в keepass'е список учеток для подключения к удаленному серверу, а в определенный момент выбрать нужную и простым нажатием Ctrl+U, запустить клиент удаленного подключения, и моментально получить доступ к вашему серверу.
Это очень удобно, так как все логины и пароли не хранятся абы где, а надежно зашифрованны в вашей базе keepass и передаются программе-клиенту только в момент подключения.
Идея состоит в том, что бы использовать Keepass как единую точку входа на все удаленные сервера.









 Здравствуйте. Сегодня я расскажу как можно создать единый установочный носитель с множеством разных версий Windows не прибегая к использованию стороннего ПО. Таким образом вы будете полностью понимать какие манипуляции мы выполняем.
Здравствуйте. Сегодня я расскажу как можно создать единый установочный носитель с множеством разных версий Windows не прибегая к использованию стороннего ПО. Таким образом вы будете полностью понимать какие манипуляции мы выполняем. Каждый раз поднимая новый сервер в облаках, вы получаете случайный IP-адрес. Не все понимают, что IP-адрес может попасть к вам с "историей". Часто приходится тратить время на удаление IP из публичных черных списков. В моём случае в последний раз это была очень неторопливая переписка с mail.ru, которая ни к чему не привела. После этого, создав новый сервер, я задумался: как же сделать так, чтобы не огребать проблем с такими IP-адресами?
Каждый раз поднимая новый сервер в облаках, вы получаете случайный IP-адрес. Не все понимают, что IP-адрес может попасть к вам с "историей". Часто приходится тратить время на удаление IP из публичных черных списков. В моём случае в последний раз это была очень неторопливая переписка с mail.ru, которая ни к чему не привела. После этого, создав новый сервер, я задумался: как же сделать так, чтобы не огребать проблем с такими IP-адресами?
 У многих сейчас стоят счетчики воды. И большинство сталкиваются с проблемой снятия показаний с этих счетчиков и их своевременной сдачей. Я не стал исключением. Показания у меня было снимать удобно, но вот сдавать я их постоянно забывал и вспоминал в самый неподходящий момент. Было решено автоматизировать процесс снятие показаний, чтобы можно было их просмотреть в любой момент времени. Кому интересно как получить картинку слева у себя на телефоне прошу под кат.
У многих сейчас стоят счетчики воды. И большинство сталкиваются с проблемой снятия показаний с этих счетчиков и их своевременной сдачей. Я не стал исключением. Показания у меня было снимать удобно, но вот сдавать я их постоянно забывал и вспоминал в самый неподходящий момент. Было решено автоматизировать процесс снятие показаний, чтобы можно было их просмотреть в любой момент времени. Кому интересно как получить картинку слева у себя на телефоне прошу под кат.
 Blockchain технологии в данный момент являются слишком раздутыми. О нем пишут и говорят все: от конференций
Blockchain технологии в данный момент являются слишком раздутыми. О нем пишут и говорят все: от конференций