Мониторим всё: расширение агентов Windows и Linux при помощи скриптов
10 мин
Туториал
Если нам нужно мониторить состояние серверов и прочих компьютеризированных рабочих мест при помощи Zabbix, то это можно сделать двумя способами.
Первый способ — это при помощи SNMP-запросов, с отправкой которых Zabbix замечательно справляется. Так можно вытащить и загрузку сетевых интерфейсов, и загрузку процессора, памяти. Поверх этого, производители сервера могут выдать нам по SNMP еще много информации о состоянии железа.
Второй заключается в использовании Zabbix агента, который мы будем запускать на наблюдаемой системе. Список наблюдаемых параметров включает в себя как и такие простые вещи, как загрузка процессора, использование памяти, так и более хитрые, такие как чтение текстовых лог-файлов с поддержкой ротации или отслеживание факта изменения любого файла. Можно даже в качестве параметра использовать вывод любой произвольной команды на системе. Возможности Zabbix агента растут от версии к версии.
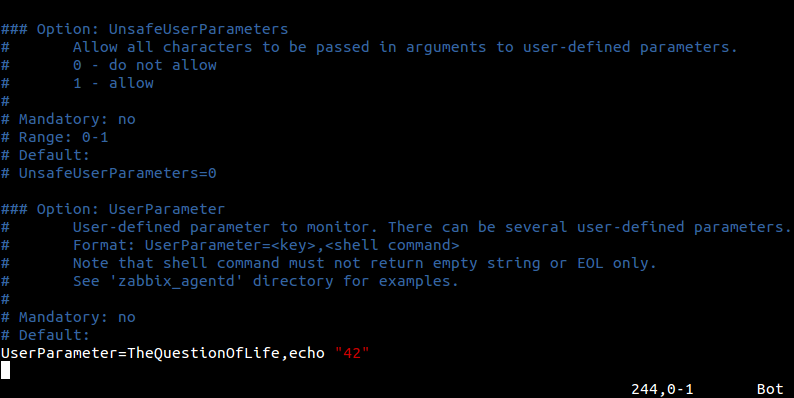
Что делать, если того, что мы хотим контролировать через Zabbix нет в списке возможностей Zabbix агента? Ждать пока это имплементируют разработчики в следующем релизе? Не обязательно.
Первый способ — это при помощи SNMP-запросов, с отправкой которых Zabbix замечательно справляется. Так можно вытащить и загрузку сетевых интерфейсов, и загрузку процессора, памяти. Поверх этого, производители сервера могут выдать нам по SNMP еще много информации о состоянии железа.
Второй заключается в использовании Zabbix агента, который мы будем запускать на наблюдаемой системе. Список наблюдаемых параметров включает в себя как и такие простые вещи, как загрузка процессора, использование памяти, так и более хитрые, такие как чтение текстовых лог-файлов с поддержкой ротации или отслеживание факта изменения любого файла. Можно даже в качестве параметра использовать вывод любой произвольной команды на системе. Возможности Zabbix агента растут от версии к версии.
Что делать, если того, что мы хотим контролировать через Zabbix нет в списке возможностей Zabbix агента? Ждать пока это имплементируют разработчики в следующем релизе? Не обязательно.
 Тех, кто использует или собирается использовать Zabbix в промышленных масштабах, всегда волновал вопрос: сколько реально данных сможет Заббикс «переварить» перед тем как окончательно поперхнется и подавится? Часть моей недавней работы как раз касалось этого вопроса. Дело в том, что у меня есть огромная сеть, насчитывающая более 32000 узлов, и которая потенциально может полностью мониториться Заббиксом в будущем. На форуме давно идут обсуждения о том, как оптимизировать Zabbix для работы в больших масштабах, но, к сожалению, мне так и не удалось найти законченное решение.
Тех, кто использует или собирается использовать Zabbix в промышленных масштабах, всегда волновал вопрос: сколько реально данных сможет Заббикс «переварить» перед тем как окончательно поперхнется и подавится? Часть моей недавней работы как раз касалось этого вопроса. Дело в том, что у меня есть огромная сеть, насчитывающая более 32000 узлов, и которая потенциально может полностью мониториться Заббиксом в будущем. На форуме давно идут обсуждения о том, как оптимизировать Zabbix для работы в больших масштабах, но, к сожалению, мне так и не удалось найти законченное решение.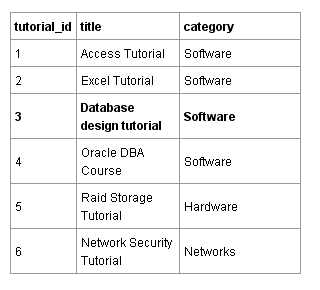


 Эта статья не для матёрых укротителей Python’а, для которых распутать этот клубок змей — детская забава, а скорее поверхностный обзор многопоточных возможностей для недавно подсевших на питон.
Эта статья не для матёрых укротителей Python’а, для которых распутать этот клубок змей — детская забава, а скорее поверхностный обзор многопоточных возможностей для недавно подсевших на питон.