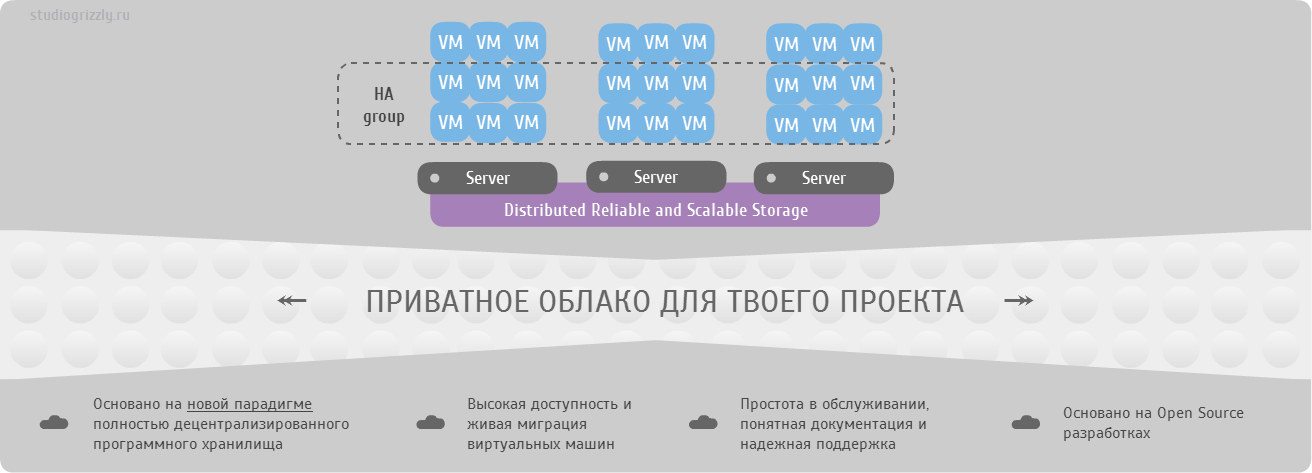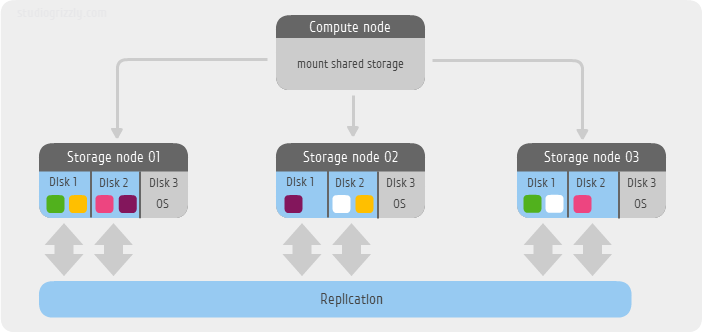
Нам понадобится всего лишь несколько минут для того что бы поднять распределенную файловую систему Ceph FS
Краткая справка
Ceph — это open source разработка эластичного легко масштабируемого петабайтного хранилища. В основе лежит объединение дисковых пространств нескольких десятков серверов в объектное хранилище, что позволяет реализовать гибкую многократную псевдослучайную избыточность данных. Разработчики Ceph дополняют такое объектное хранилище еще тремя проектами:
- RADOS Gateway — S3- и Swift-совместимый RESTful интерфейс
- RBD — блочное устройство с поддержкой тонкого роста и снапшотами
- Ceph FS — распределенная POSIX-совместимая файловая система
Описание примера
В моем небольшом примере я использую всего 3 сервера в качестве хранилища. В каждом сервере мне доступно 3 SATA диска:
/dev/sda как системный и /dev/sdb и /dev/sdc под данные файловой системы Ceph FS. ОС в этом примере будет Ubuntu 12.04 LTS. Еще один сервер будет монтировать файловую систему, то есть по сути выступать клиентом. Используем уровень избыточности по-умолчанию, то есть две реплики одного блока. На момент написания статьи разработчики предлагают два метода создания простых конфигураций — старый, используя
mkcephfs или новый ceph-deploy. Для новых версий, начиная с ветки 0.6x (cuttlefish), уже рекомендуется использовать ceph-deploy. Но в данном примере я использую более ранний, стабильный релиз ветки 0.56.x (bobtail), применяя mkcephfs.Сразу предупрежу — Ceph FS на данный момент все еще находится в препрадакшн статусе, но по активности сообщества этот проект называют одним из самых горячих среди software defined storage.
Приступим.
Шаг 0. Установка ОС
Выполняем минимальную установку. Дополнительно необходимо установить
ntpdate и ваш любимый редактор, например vim.aptitude update && aptitude install ntpdate vim
Шаг 1. Инсталлируем пакеты Ceph
На каждую ноду кластера и клиент устанавливаем пакеты Ceph
wget -q -O- 'https://ceph.com/git/?p=ceph.git;a=blob_plain;f=keys/release.asc' | sudo apt-key add - echo deb http://ceph.com/debian-bobtail/ $(lsb_release -sc) main | tee /etc/apt/sources.list.d/ceph.list aptitude update && aptitude install ceph
Шаг 2. Создаем конфигурационный файл
На каждой ноде и клиенте создаем единый файл конфигурации
/etc/ceph/ceph.conf[global] auth cluster required = cephx auth service required = cephx auth client required = cephx [osd] osd journal size = 2000 osd mkfs type = xfs osd mkfs options xfs = -f -i size=2048 osd mount options xfs = rw,noatime,inode64 [mon.a] host = node01 mon addr = 192.168.2.31:6789 [mon.b] host = node02 mon addr = 192.168.2.32:6789 [mon.c] host = node03 mon addr = 192.168.2.33:6789 [osd.0] host = node01 devs = /dev/sdb [osd.1] host = node01 devs = /dev/sdc [osd.2] host = node02 devs = /dev/sdb [osd.3] host = node02 devs = /dev/sdc [osd.4] host = node03 devs = /dev/sdb [osd.5] host = node03 devs = /dev/sdc [mds.a] host = node01
Делаем файл читаемым для всех
chmod 644 /etc/ceph/ceph.conf
Шаг 3. Делаем безпарольный вход между нодами
Задаем рутовый пароль, генерируем ssh ключи без указания пассфразы
passwd root ssh-keygen
Создаем ssh алиасы в
/root/.ssh/config соответственно наименованию нод в вашем случаеHost node01 Hostname node01.ceph.labspace.studiogrizzly.com User root Host node02 Hostname node02.ceph.labspace.studiogrizzly.com User root Host node03 Hostname node03.ceph.labspace.studiogrizzly.com User root
Добавляем публичные ключи на соседние ноды кластера.
ssh-copy-id root@node02 ssh-copy-id root@node03
Шаг 4. Разворачиваем кластер
Для начала подготовим необходимые диски к работе
mkfs -t xfs fs-options -f -i size=2048 /dev/sdb mkfs -t xfs fs-options -f -i size=2048 /dev/sdc
Далее подготавливаем рабочие каталоги и монтируем диски соответственно нашему дизайну
Так для node01 выполним
mkdir -p /var/lib/ceph/osd/ceph-0 mkdir -p /var/lib/ceph/osd/ceph-1 mount /dev/sdb /var/lib/ceph/osd/ceph-0 -o noatime,inode64 mount /dev/sdc /var/lib/ceph/osd/ceph-1 -o noatime,inode64
для node02
mkdir -p /var/lib/ceph/osd/ceph-2 mkdir -p /var/lib/ceph/osd/ceph-3 mount /dev/sdb /var/lib/ceph/osd/ceph-2 -o noatime,inode64 mount /dev/sdc /var/lib/ceph/osd/ceph-3 -o noatime,inode64
и для node03
mkdir -p /var/lib/ceph/osd/ceph-4 mkdir -p /var/lib/ceph/osd/ceph-5 mount /dev/sdb /var/lib/ceph/osd/ceph-4 -o noatime,inode64 mount /dev/sdc /var/lib/ceph/osd/ceph-5 -o noatime,inode64
И наконец, на node01 запускаем скрипт создания хранилища Ceph
mkcephfs -a -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.keyring
а затем скопируем ключ
ceph.keyring на другие ноды кластераscp /etc/ceph/ceph.keyring node02:/etc/ceph/ceph.keyring scp /etc/ceph/ceph.keyring node03:/etc/ceph/ceph.keyring
и на клиентскую ноду, в моем случае —
192.168.2.39scp /etc/ceph/ceph.keyring 192.168.2.39:/etc/ceph/ceph.keyring
Ключам выставляем доступ на чтения
chmod 644 /etc/ceph/ceph.keyring
Шаг 5. Запуск и статус
Благодаря беспарольному входу между нодами выполняем старт всего кластера с любой ноды
service ceph -a start
Там же проверяем состояния кластера
ceph -s
Наиболее ожидаемый статус при нормальной работе это
HEALTH_OKСо стороны клиента создаем каталог в необходимом месте, например
/mnt/cephfs, парсим ключ для модуля ядра ceph и монтируем файловую системуmkdir /mnt/cephfs ceph-authtool --name client.admin /etc/ceph/ceph.keyring --print-key | tee /etc/ceph/admin.secret mount -t ceph node01:6789,node02:6789,node03:6789:/ /mnt/cephfs -o name=admin,secretfile=/etc/ceph/admin.secret,noatime
Послесловие
Вот таким образом получаем распределенную файловую систему Ceph FS всего за 15 минут. Вопросы производительности, безопасности и обслуживания требуют более детального погружения и это материал на отдельную статью, а то и не одну.
P.S.
Забабахали связку OpenNebula+Ceph используя только объектное хранение Ceph, без файловой системы Ceph FS. Читать подробнее в хабе Я пиарюсь.