
В блоге FreshInbox опубликован пост об интересной экспериментальной техники реализации пагинации в письмах мобильных почтовых рассылок. Ее использование позволяет создавать письма, получатели которых могут перемещаться по контенту без необходимости скроллинга.
Развитие адаптивного дизайна сделало чтение писем на мобильных устройствах легче. С другой стороны, побочным эффектом стал тот факт, что для чтения «массивных» писем теперь нужно много скроллить. В итоге до конца послания добираются только самые стойкие читатели. Если дать людям возможность быстрой навигации по письму, это бы значительно улучшило ситуацию.
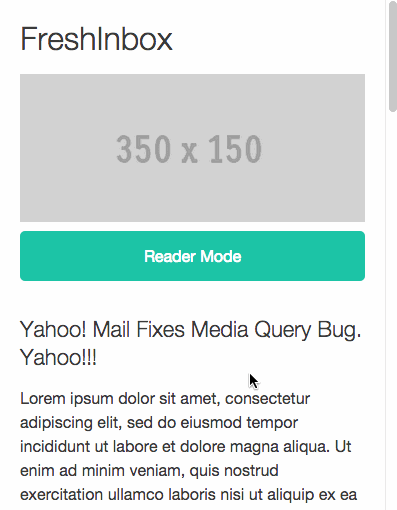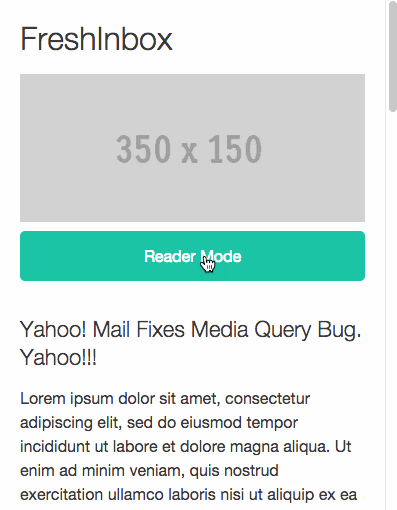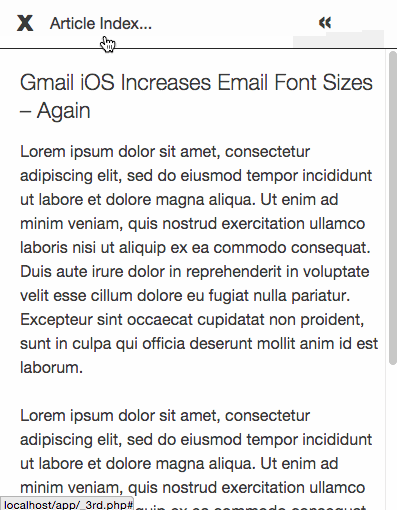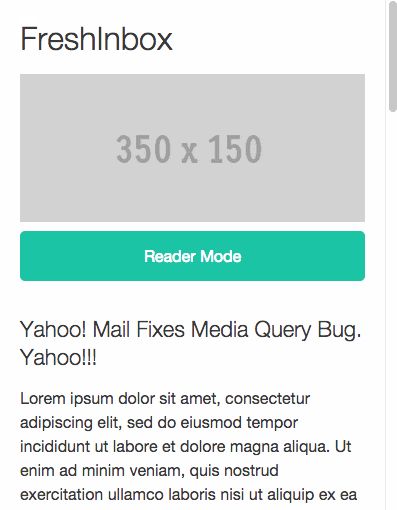
Описываемая техника работает только в почтовом приложении Mail для iPhone (версия для Android в разработке).
Развитие адаптивного дизайна сделало чтение писем на мобильных устройствах легче. С другой стороны, побочным эффектом стал тот факт, что для чтения «массивных» писем теперь нужно много скроллить. В итоге до конца послания добираются только самые стойкие читатели. Если дать людям возможность быстрой навигации по письму, это бы значительно улучшило ситуацию.
Описываемая техника работает только в почтовом приложении Mail для iPhone (версия для Android в разработке).




 Близится выход Visual Studio 2015 и многим интересны новые возможности этого инструмента разработки и сопутствующих технологий. Промежуточные версии, которые выпускали на протяжении последних месяцев уже показали, что нас действительно ждет замечательный продукт, и в этом посте хотелось бы собрать наиболее интересные материалы, которые рассказывают об этих функциях.
Близится выход Visual Studio 2015 и многим интересны новые возможности этого инструмента разработки и сопутствующих технологий. Промежуточные версии, которые выпускали на протяжении последних месяцев уже показали, что нас действительно ждет замечательный продукт, и в этом посте хотелось бы собрать наиболее интересные материалы, которые рассказывают об этих функциях.


