Data Engineering: концепции, процессы и инструменты
Medium
16 min
Review
Translation
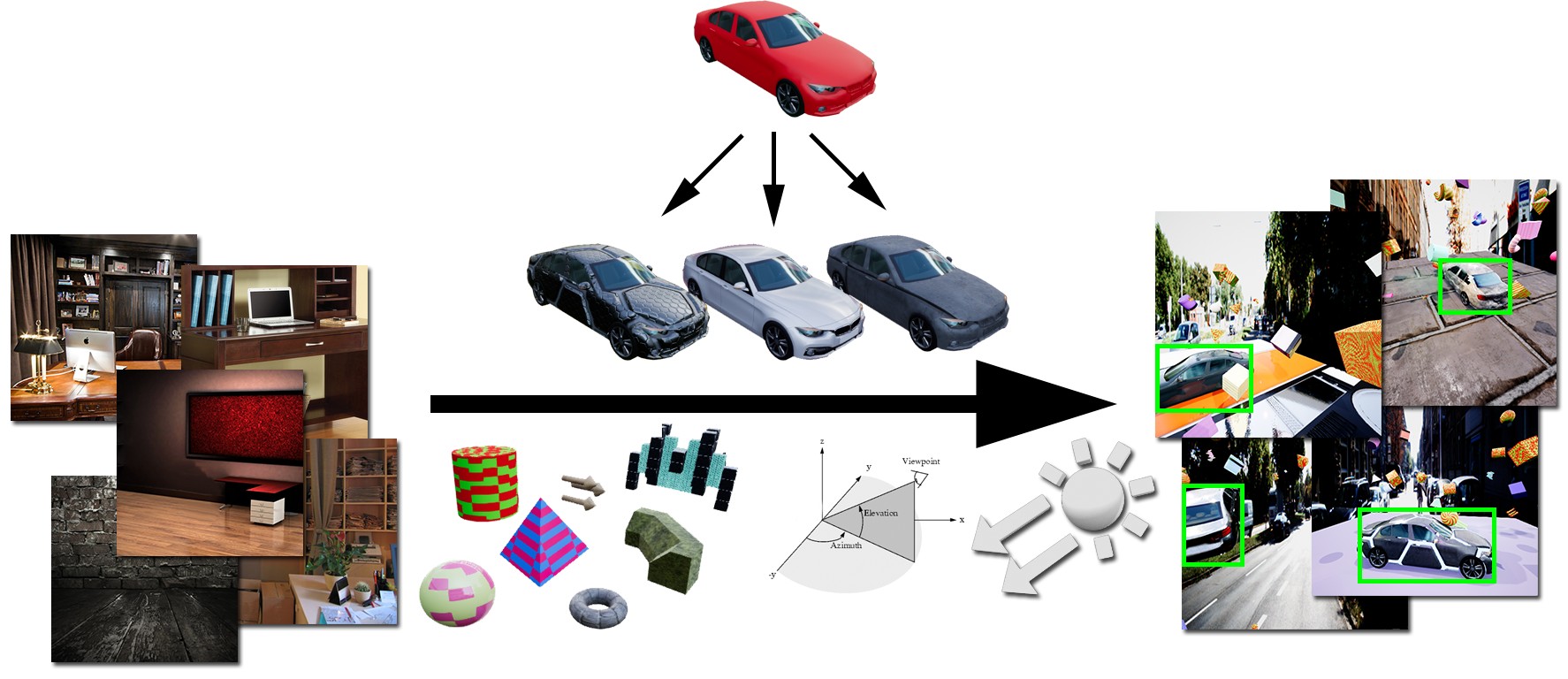
Data science, машинное обучение и искусственный интеллект — не просто громкие слова: многие организации стремятся их освоить. Но прежде чем создавать интеллектуальные продукты, необходимо собрать и подготовить данные, которые станут топливом для ИИ. Фундамент для аналитических проектов закладывает специальная дисциплина — data engineering. Связанные с ней задачи занимают первые три слоя иерархии потребностей data science, предложенной Моникой Рогати.
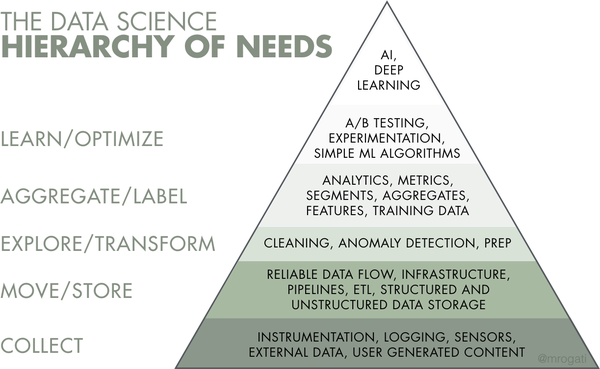
Слои data science для реализации ИИ.
В этой статье мы рассмотрим процесс data engineering, расскажем о его базовых компонентах и инструментах, опишем роль дата-инженера.
Слои data science для реализации ИИ.
В этой статье мы рассмотрим процесс data engineering, расскажем о его базовых компонентах и инструментах, опишем роль дата-инженера.