Как мы масштабируем машинное обучение
13 min
Translation
Введение
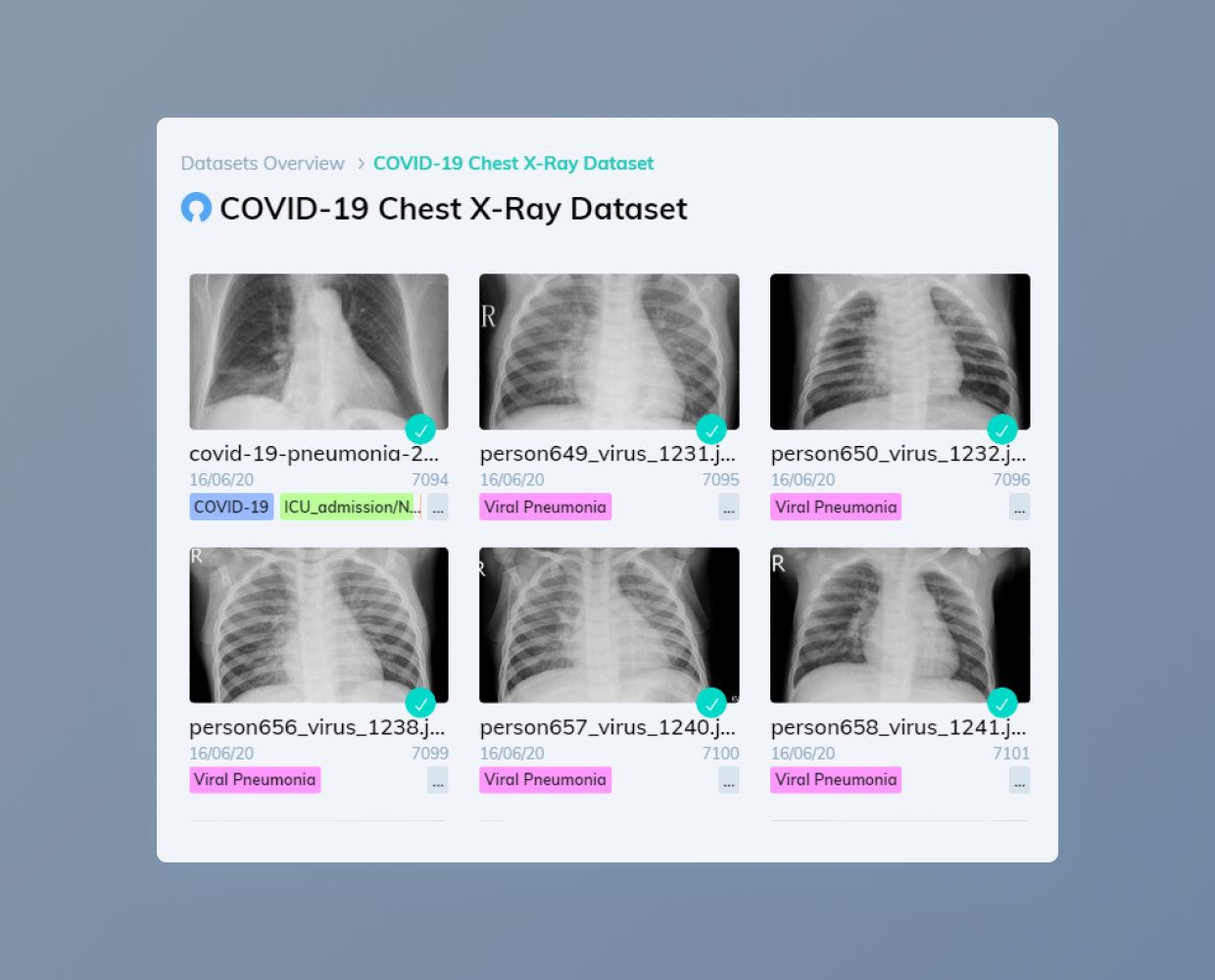
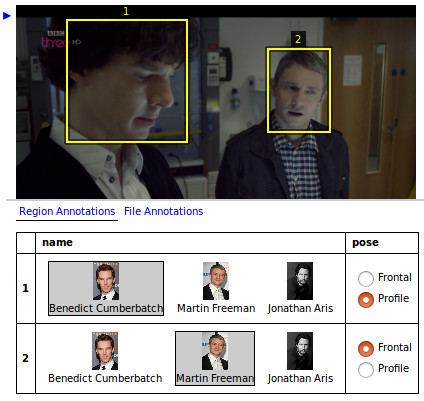
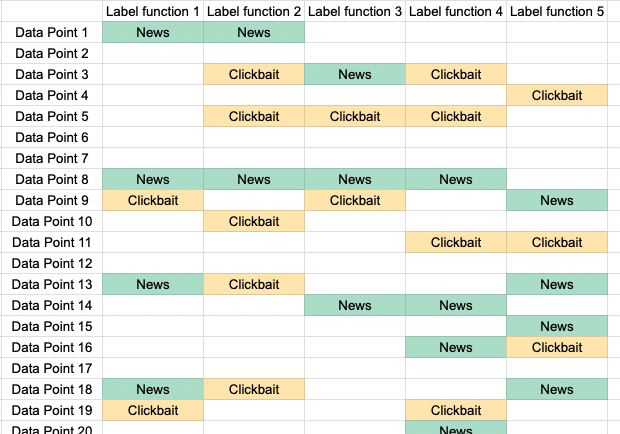
Наша компания еженедельно размечает порядка 10 миллиардов аннотаций. Чтобы обеспечивать высокое качество аннотаций для такого огромного объёма данных, мы разработали множество методик, в том числе sensor fusion для выявления подробностей о сложных окружениях, активный инструментарий для ускорения процесса разметки и автоматизированные бенчмарки для измерения и поддержания качества работы разметчиков. С расширением количества заказчиков, разметчиков и объёмов данных мы продолжаем совершенствовать эти методики, чтобы повышать качество, эффективность и масштабируемость разметки.
Как мы используем ML
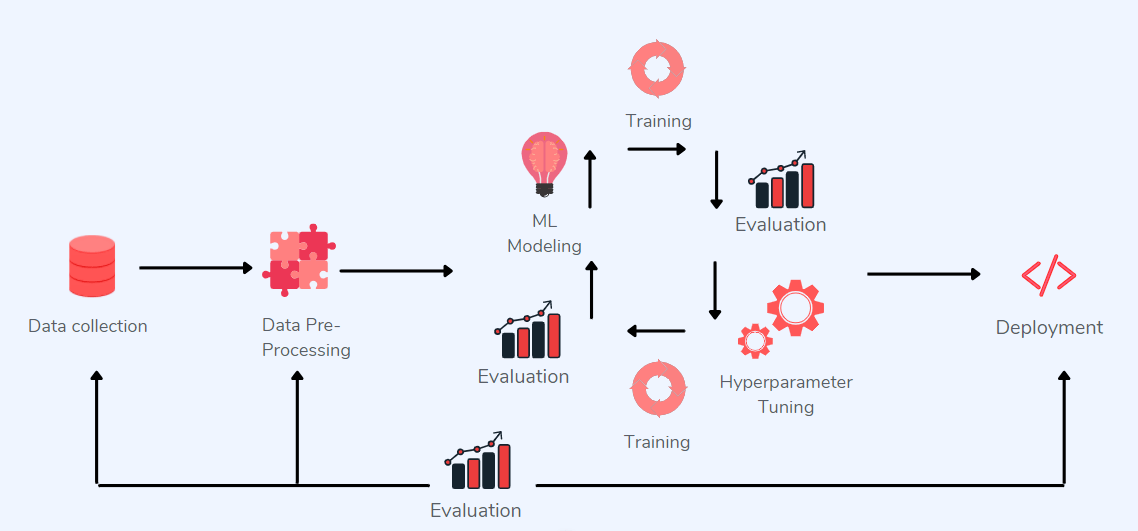
Обширные объёмы передаваемых компании данных предоставляют ей бесценные возможности обучения и надстройки наших процессов аннотирования, и в то же время позволяют нашей команде разработчиков машинного обучения обучать модели, расширяющие набор доступных нам функций.