R: геопространственные библиотеки
4 мин
Перевод
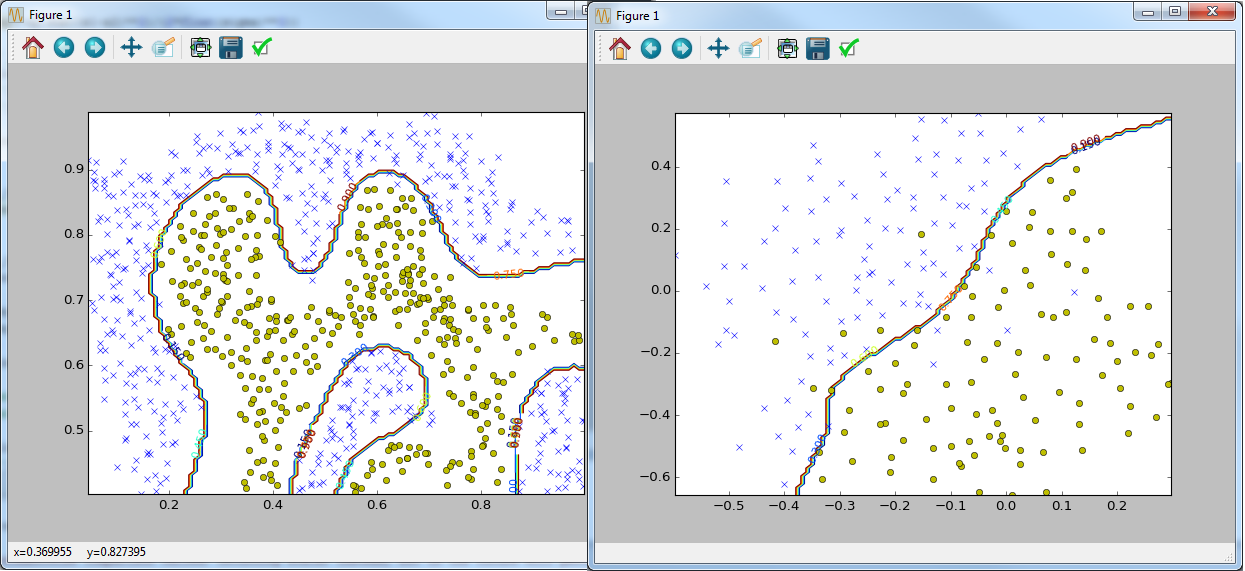
Ввод/вывод, изменение и визуализация геопространственных данных — задачи, общие для многих дисциплин. Поэтому многие заинтересованы в создании хороших инструментов для их решения. Набор инструментов для работы с пространственными данными постоянно растет. Мы поверхностно рассмотрим каждый из них. Подробности можно получить по ссылкам на cran или github.
Мы не пытаемся заменить уже существующие в R геопространственные библиотеки — скорее, дополнить и создать небольшие инструменты, позволяющие легко воспользоваться только необходимыми вам функциями.
Мы не пытаемся заменить уже существующие в R геопространственные библиотеки — скорее, дополнить и создать небольшие инструменты, позволяющие легко воспользоваться только необходимыми вам функциями.

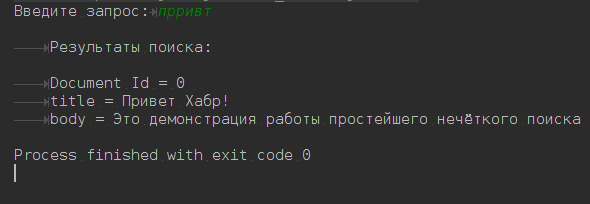 Пост расcчитан на начинающих, на людей незнакомых с технологией Apache Lucene. В нем нет материала о том, как устроен Apache Lucene внутри, какие алгоритмы, структуры данных и методы использовались для создания фреймворка. Пост является обучающим материалом-тизером, написанным для того, чтобы показать, как организовать простейший нечёткий поиск по тексту.
Пост расcчитан на начинающих, на людей незнакомых с технологией Apache Lucene. В нем нет материала о том, как устроен Apache Lucene внутри, какие алгоритмы, структуры данных и методы использовались для создания фреймворка. Пост является обучающим материалом-тизером, написанным для того, чтобы показать, как организовать простейший нечёткий поиск по тексту.  Сначала я хотел честно и подробно написать о методах снижения размерности данных —
Сначала я хотел честно и подробно написать о методах снижения размерности данных —