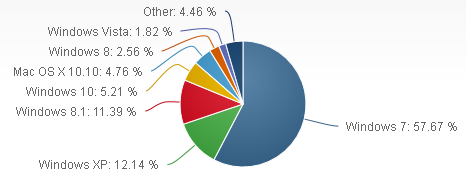
На этой неделе стало известно, что Microsoft Windows версий 7 и 8
закачивают на компьютеры пользователей обновление до Windows 10, даже если они этого не просили. Компания подтвердила, что это поведение системы было преднамеренным. Подробнее об этих событиях и о том, как найти и удалить нежелательные обновления, мы расскажем вам без регистрации и смс.
Как выяснили пытливые пользователи системы, подобный казус может случиться с теми пользователями, кто включил автоматическое обновление системы. В компании Microsoft посчитали, что такого повода достаточно для того, чтобы автоматически скачать обновление целой операционки объёмом до 6 Гб и обновить систему пользователя.
Во всём повинно обновление KB3035583, выводящее в трей значок, приглашающий обновить систему до 10-й версии. В то время как жаждущие новых приключений пользователи, у которых этот значок почему-то не появлялся,
пытались вызвать его разными способами, более консервативные пользователи, совсем не желавшие обновляться, столкнулись с принуждением в этом вопросе.
По отзывам пользователей, Microsoft не просто придумала новый способ обновления систем, но решила сделать его ещё и крайне настойчивым. Кто-то жаловался на то, что Internet Explorer прописал себе домашней страницей MSN, и каждый раз при загрузке этой страницы
выводил закрывающий её баннер с предложением (требованием?) немедля получить обновление до Windows 10.
А один из пользователей
пожаловался в издание The Inquirer, что начал копаться в системе после того, как его медленный DSL-интернет неделю ползал со скоростью хромой черепахи на пенсии. Он нашёл в каталоге «Windows» скрытый каталог "$Windows.~BT", который имел размер в несколько гигабайт.