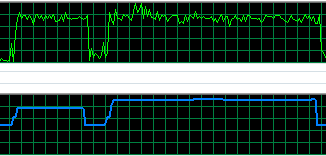
Как правильно мерять производительность диска
14 min
Tutorial
abstract: разница между текущей производительностью и производительностью теоретической; latency и IOPS, понятие независимости дисковой нагрузки; подготовка тестирования; типовые параметры тестирования; практическое copypaste howto.
Предупреждение: много букв, долго читать.
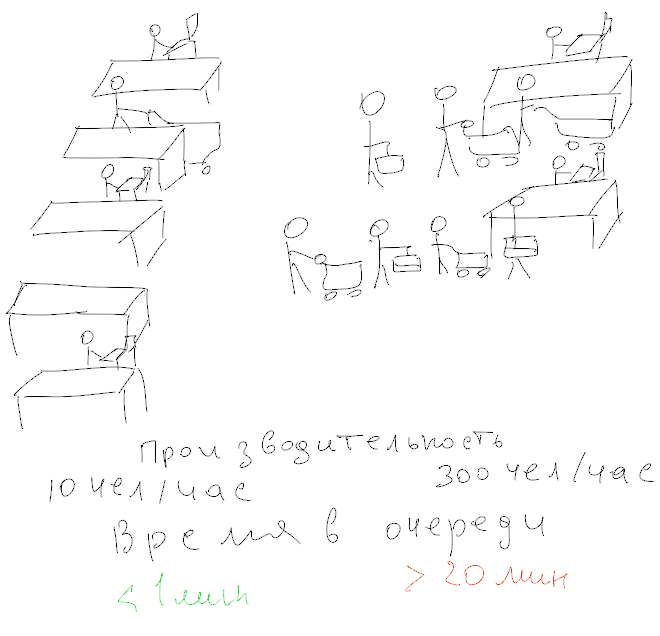
Очень частой проблемой, является попытка понять «насколько быстрый сервер?» Среди всех тестов наиболее жалко выглядят попытки оценить производительность дисковой подсистемы. Вот ужасы, которые я видел в своей жизни:
Это всё совершенно ошибочные методы. Дальше я разберу более тонкие ошибки измерения, но в отношении этих тестов могу сказать только одно — выкиньте и не используйте.
Предупреждение: много букв, долго читать.
Лирика
Очень частой проблемой, является попытка понять «насколько быстрый сервер?» Среди всех тестов наиболее жалко выглядят попытки оценить производительность дисковой подсистемы. Вот ужасы, которые я видел в своей жизни:
- научная публикация, в которой скорость кластерной FS оценивали с помощью dd (и включенным файловым кешем, то есть без опции direct)
- использование bonnie++
- использование iozone
- использование пачки cp с измерениема времени выполнения
- использование iometer с dynamo на 64-битных системах
Это всё совершенно ошибочные методы. Дальше я разберу более тонкие ошибки измерения, но в отношении этих тестов могу сказать только одно — выкиньте и не используйте.


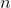 ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то
ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то  запросов могут отнять
запросов могут отнять 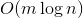 времени. Здравый смысл подсказывает, что оценку можно оптимизировать до
времени. Здравый смысл подсказывает, что оценку можно оптимизировать до 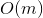 , надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности.
, надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности. , что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.
, что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.
 Как случилось, что искусственный интеллект успешно развивается, а «правильного» определения для него до сих пор нет? Почему не оправдались надежды, возлагавшиеся на нейрокомпьютеры, и в чем заключаются три главные задачи, стоящие перед создателем искусственного интеллекта?
Как случилось, что искусственный интеллект успешно развивается, а «правильного» определения для него до сих пор нет? Почему не оправдались надежды, возлагавшиеся на нейрокомпьютеры, и в чем заключаются три главные задачи, стоящие перед создателем искусственного интеллекта?