Павел Филонов (во время выступления работал в Positive Technologies)

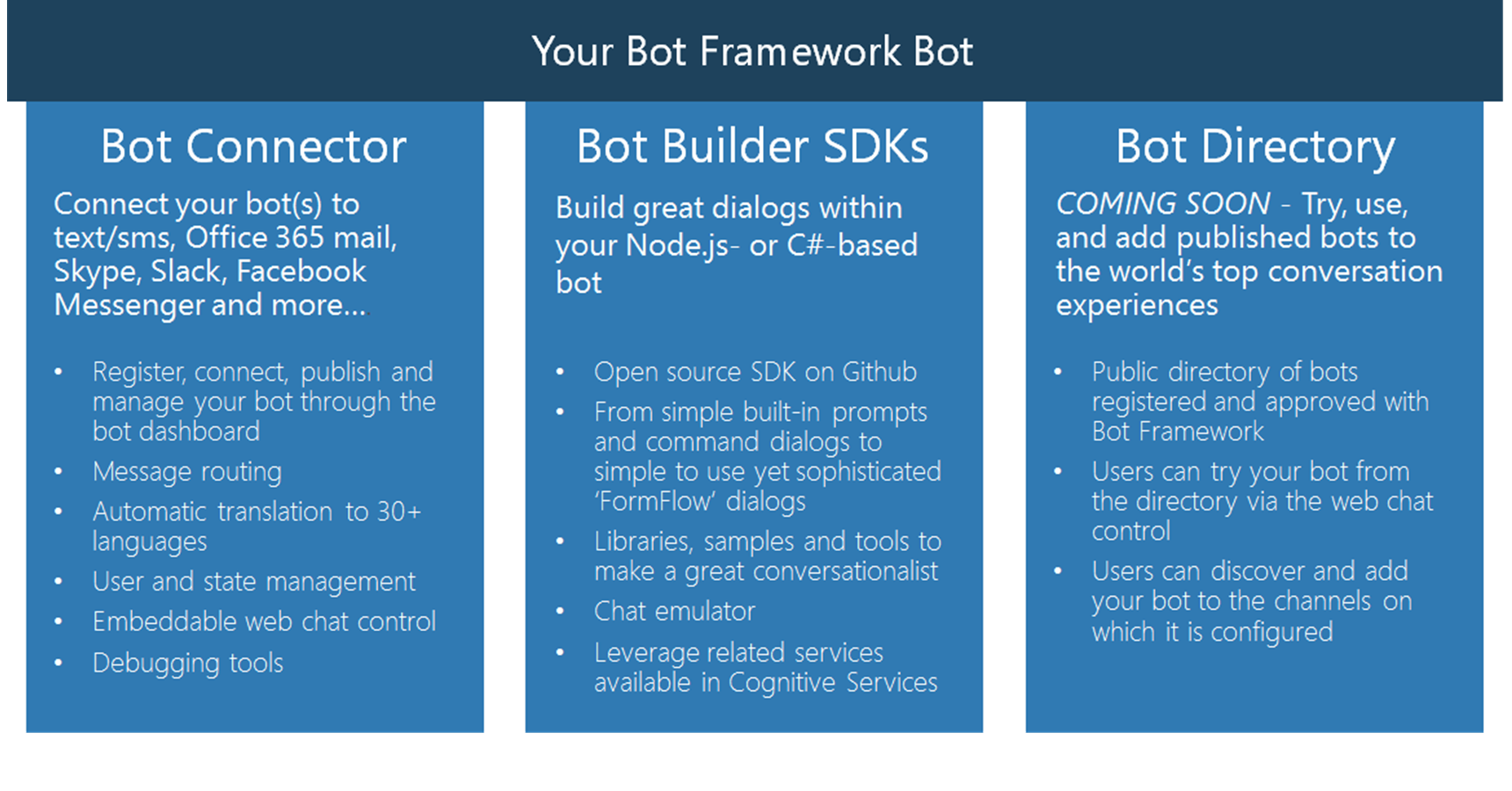
В данном докладе я хочу поговорить о пересечении RabbitMQ и Pipeline архитектуры, и о том, как оно связанно с работой нашей компании.
Сначала немного в качестве пролога. Это приятная часть.

Сценка, разворачивающаяся в будний день в офисе, наводит нас на очень приятное размышление. Перед нами встает шикарная задача, новая система. Мало что так сильно будоражит ум инженера, как просьба разработать новую систему. Не починить что-то старое, не адаптировать что-то старое, а именно что-то создать, в каком-то смысле практически с нуля.
Вместе с такой задачей приходит и целая серия проблем.
 Основным хранилищем метрик у нас является cassandra, мы используем её уже более трех лет. Для всех предыдущих проблем мы успешно находили решение, используя встроенные средства диагностики кассандры.
Основным хранилищем метрик у нас является cassandra, мы используем её уже более трех лет. Для всех предыдущих проблем мы успешно находили решение, используя встроенные средства диагностики кассандры. 



 Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как
Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как