Добрый день.
Логи часто и абсолютно не заслуженно обделены вниманием разработчиков. И когда программистам необходимо пропарсить log-файлы, иногда с нескольких десятков серверов одновременно, задача эта ложится на системных администраторов и отнимает у них много времени и сил.
Поэтому, когда случаются проблемы и надо найти ошибку в логах какого-нибудь сервиса, все зависит от того, насколько силен админ и насколько программисты знают, что искать. А еще от того, отработал ли logrotate и не грохнул ли он старые данные…
В таких ситуациях отлично помогает
Logstash. Он активно развивается последний год, уже наделал много шуму, и на хабре, например
тут и
тут, достаточно статей о том, как его поставить и заставить работать на одном сервере. В этой статье я затрону Logstash в качестве сервера обработки, потому что, как агент, он по некоторым параметрам нам не подошел.
Почему? Maxifier представляет собой SaaS-продукт с клиентами в США, Бразилии, в нескольких странах Европы и в Японии, так что у нас около сотни серверов, раскиданных по всему миру. Для оперативной работы нам необходимо иметь удобный доступ к логам наших приложений и быстрый поиск ошибок в них в случае проблем на сторонних сервисах/api, появления некорректных данных т.д. Кстати,
похожей системой сборки логов пользуются The Guardian (одни из наших клиентов).
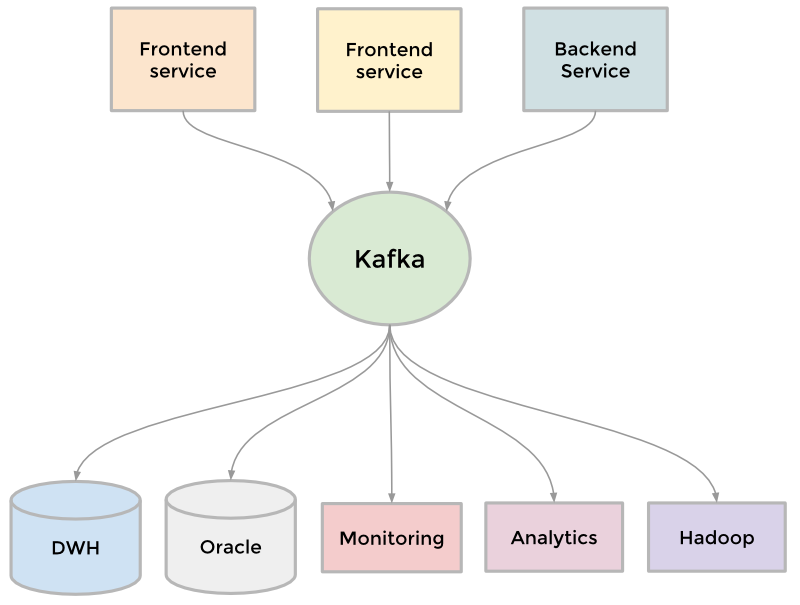
После нескольких случаев сборки логов Rsync-ом со множества серверов мы задумались над альтернативой, менее долгой и трудоемкой. И недавно мы разработали свою систему сборки логов для разных приложений. Поделюсь собственным опытом и описанием, как это работает.