Речь идет о необычных учебниках, которые стоят посередине между вузовскими учебниками и чисто научно-популярными брошюрами. Тем не менее между научпопом и такими учебниками есть четкий водораздел — последние нацелены именно на обучение, развлекательные фишки — лишь форма подачи серьезного материала. Общее для всех таких книг, как мне представляется — подача материала в виде комикса и\или в виде диалога двух или больше людей. Обычно два собеседника — ученик и учитель, один постоянно задает вопросы, часто глупые или смешные, второй пытается объяснить в игровой форме.
В посте много скриншотов нескольких книг. Одну из них, которая про катастрофы я полностью переснял и выложил pdf. Прошу учесть, под хабракатом не один мегабайт картинок, текста много меньше. Заранее прошу прощения за качество некоторых кадров — ночная пересъемка не способствовала. Возможно, картинок больше, чем нужно, но я старался и показать основные принципы — графический, игровой способ подачи материала, сюжет и диалоги.
Я сделал что-то вроде ретроспективы: первая книга — свежий японский комикс-манга о матстатистики издания 2010 года, дальше — книга из 80-х о математике, теории катасроф. Последняя — учебник радиоэлектроники для начинающих, знакомый нескольким поколениям читателей по всему миру, начиная с 30-х годов.
В качестве иллюстрации поста приведу обложку другой манги из той же серии, что и книга о статистике:







![[скриншот 2013-06-13 10:23:32]](https://habrastorage.org/getpro/habr/post_images/201/785/a25/201785a257e8795ae984677f06e114a2.png "скриншот (1864×1140 пикселов)")

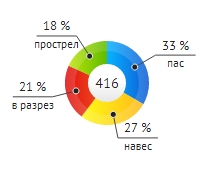
 В этой статье я расскажу об одном необычном подходе к генерации лабиринтов. Он основан на модели Амари́ нейронной активности коры головного мозга, являющейся непрерывным аналогом нейронных сетей. При определенных условиях она позволяет создавать красивые лабиринты очень сложной формы, подобные тому, что приведен на картинке.
В этой статье я расскажу об одном необычном подходе к генерации лабиринтов. Он основан на модели Амари́ нейронной активности коры головного мозга, являющейся непрерывным аналогом нейронных сетей. При определенных условиях она позволяет создавать красивые лабиринты очень сложной формы, подобные тому, что приведен на картинке.