Чтобы собирать образы Docker в контейнере и при этом обойтись без Docker, можно использовать kaniko. Давайте узнаем, как запускать kaniko локально и в кластере Kubernetes.

Дальше будет многабукаф

User
Чтобы собирать образы Docker в контейнере и при этом обойтись без Docker, можно использовать kaniko. Давайте узнаем, как запускать kaniko локально и в кластере Kubernetes.
Дальше будет многабукаф
Ядро Linux предоставляет широкий спектр параметров конфигурации, которые могут повлиять на производительность. Главное — выбрать правильную конфигурацию для вашего приложения и рабочей нагрузки. Как и любой другой базе данных, PostgreSQL необходима оптимальная настройка ядра Linux. Неправильные настройки могут привести к снижению производительности. Важно проводить сравнительный анализ производительности базы данных после каждого сеанса настройки. В одном из своих предыдущих постов под названием "Tune Linux Kernel Parameters For PostgreSQL Optimization" я описал некоторые из наиболее полезных параметров ядра Linux и то, как они помогают повысить производительность базы данных. Теперь я поделюсь результатами сравнительного тестирования после настройки HugePages в Linux под различными нагрузками PostgreSQL. Я провел полный набор тестов под множеством различных нагрузок PostgreSQL с различным числом параллельных клиентов.


В октябре этого года я выступил с докладом на конференции HashiConf 2018, где рассказал о 5 ключевых уроках, которые я и мои коллеги из Gruntwork усвоили в процессе создания и поддержки библиотеки из более чем 300 000 строк инфраструктурного кода, используемой в производственных системах сотнями компаний. В этой публикации я поделюсь видео и слайдами с выступления, а также сокращенной текстовой версией описания 5 основных уроков.
Несмотря на то, что индустрия полна модных прогрессивных слов: Kubernetes, микросервисы, сервисные сетки, неизменяемая инфраструктура, большие данные, озера данных и т. д., — реальность такова, что, когда ты с головой погружен в создание инфраструктуры, ты не чувствуешь себя таким уж модным и прогрессивным.

Одно дело обезопасить кластер Kubernetes, а вот поддерживать защиту — задачка та еще. Впрочем, в Kubernetes добавилось новых средств: теперь выполнять и то, и другое намного проще.
1-3 февраля пройдёт Слёрм-3, интенсив по Kubernetes. Анонс и программа тут.
Сегодня расскажу немного о внутренней кухне: как мы помогаем студентам справляться с практикой и что из этого получается. Заодно будущие участники поймут, чего ждать от поддержки.

Я сам 2-3 раза в год прохожу платные курсы, всегда беру варианты с практикой, и очень редко доделываю ее до конца. Для меня ситуация выглядит, как если бы я заказал в ресторане килограммовый стейк: съел, сколько мог, остальное оставил на тарелке. Но в тех, кто едет на Слёрм, хотелось бы запихнуть всю порцию.
На первом Слёрме мы отнеслись к практике спокойно, мол, мы даем задания, а участники справляются как могут. И это привело бы к катастрофе, если бы в аудитории не нашлось инициативных и талантливых парней: «15 минут назад я писал в чат о проблеме, я ее уже решил сам и помог еще пятерым».
Поэтому на втором Слёрме кроме трех спикеров со студентами работал десяток саппортов: системных администраторов из команды Southbridge.
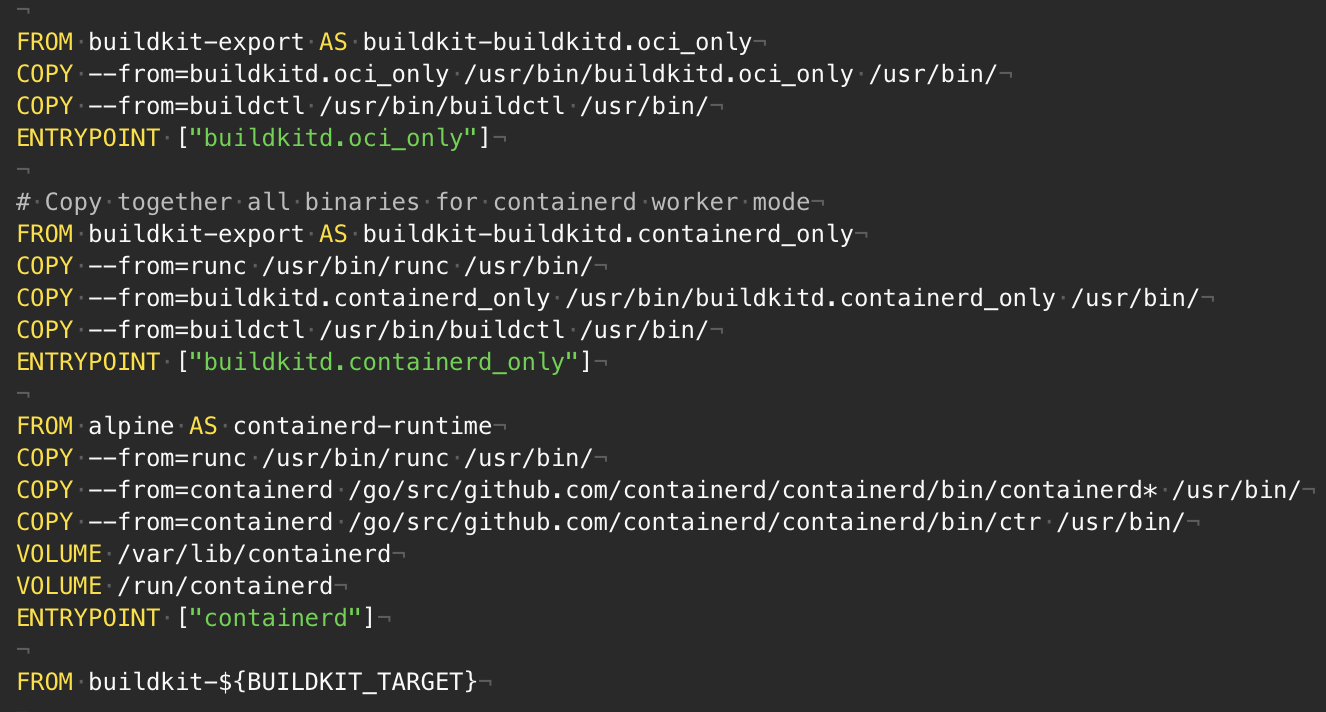
Функция многоэтапной сборки в файлах Dockerfile позволяет создавать небольшие образы контейнеров с более высоким уровнем кэширования и меньшим объемом защиты. В этой статье я покажу несколько расширенных шаблонов — нечто большее, чем копирование файлов между этапами сборки и выполнения. Они позволяют добиться максимальной эффективности функции. Однако, если Вы — новичок в сфере многоэтапной сборки, то сперва, наверное, не лишним будет прочесть руководство по использованию.

Как всегда, спасибо Фреду Хеберту и Саргуну Дхиллону за то, что прочли черновик этой статьи и предложили нескольких бесценных советов.
В своем докладе о скорости Тамар Берковичи из Box подчеркнула важность проверок работоспособности при автоматическом аварийном переключении баз данных. В частности, она отметила, что мониторинг времени выполнения сквозных запросов, как метод определения работоспособности базы данных, — лучше, чем простое эхо-тестирование (пингирование).
... перебрасывая трафик на другую ноду (реплику), чтобы устранить бездействие, надо построить средства защиты от дребезга и других пограничных ситуаций. Это не сложно. Фокус при организации эффективной работы в том, чтобы знать, когда перевести базу данных в первую позицию, т.е. надо быть в состоянии правильно оценить работоспособность базы данных. Сейчас многие параметры, на которые мы привыкли обращать внимание, — например, загрузка процессора, время ожидания блокировки, частота ошибок, — являются вторичными сигналами. Ни один из этих параметров на самом деле не говорит о способности базы данных к обработке клиентского трафика. Поэтому, если используете их для принятия решения о переключении, можете получить как ложноположительные, так и ложноотрицательные результаты. Наше устройство проверки работоспособности фактически выполняет простые запросы к узлам базы данных и использует данные о выполненных и невыполненных запросах для более точной оценки работоспособности базы данных.
Я обсудила это с другом, и он предположил, что проверки работоспособности должны быть предельно простыми, и что реальный трафик — это лучший критерий для оценки работоспособности процесса.
14 сентября служба поддержки GitLab сообщила о критической проблеме, которая возникла у одного из наших клиентов: сначала GitLab работает нормально, а потом у пользователей возникает ошибка. Они пытались клонировать некоторые репозитории через Git, и вдруг появлялось непонятное сообщение об устаревшем файле: Stale file error. Ошибка сохранялась надолго и не давала работать, пока системный администратор вручную не запускал ls в самом каталоге.
Пришлось изучать внутренние механизмы Git и сетевой файловой системы NFS. В итоге мы нашли баг в клиенте Linux v4.0 NFS, Тронд Мюклебуст (Trond Myklebust) написал патч для ядра, и с 26 октября этот патч входит в основное ядро Linux.
В этом посте я расскажу, как мы изучали проблему, в каком направлении думали и какие инструменты использовали, чтобы отследить баг. Мы вдохновлялись отличной детективной работой Олега Дашевского, описанной в посте «Как я две недели охотился за утечкой памяти в Ruby».

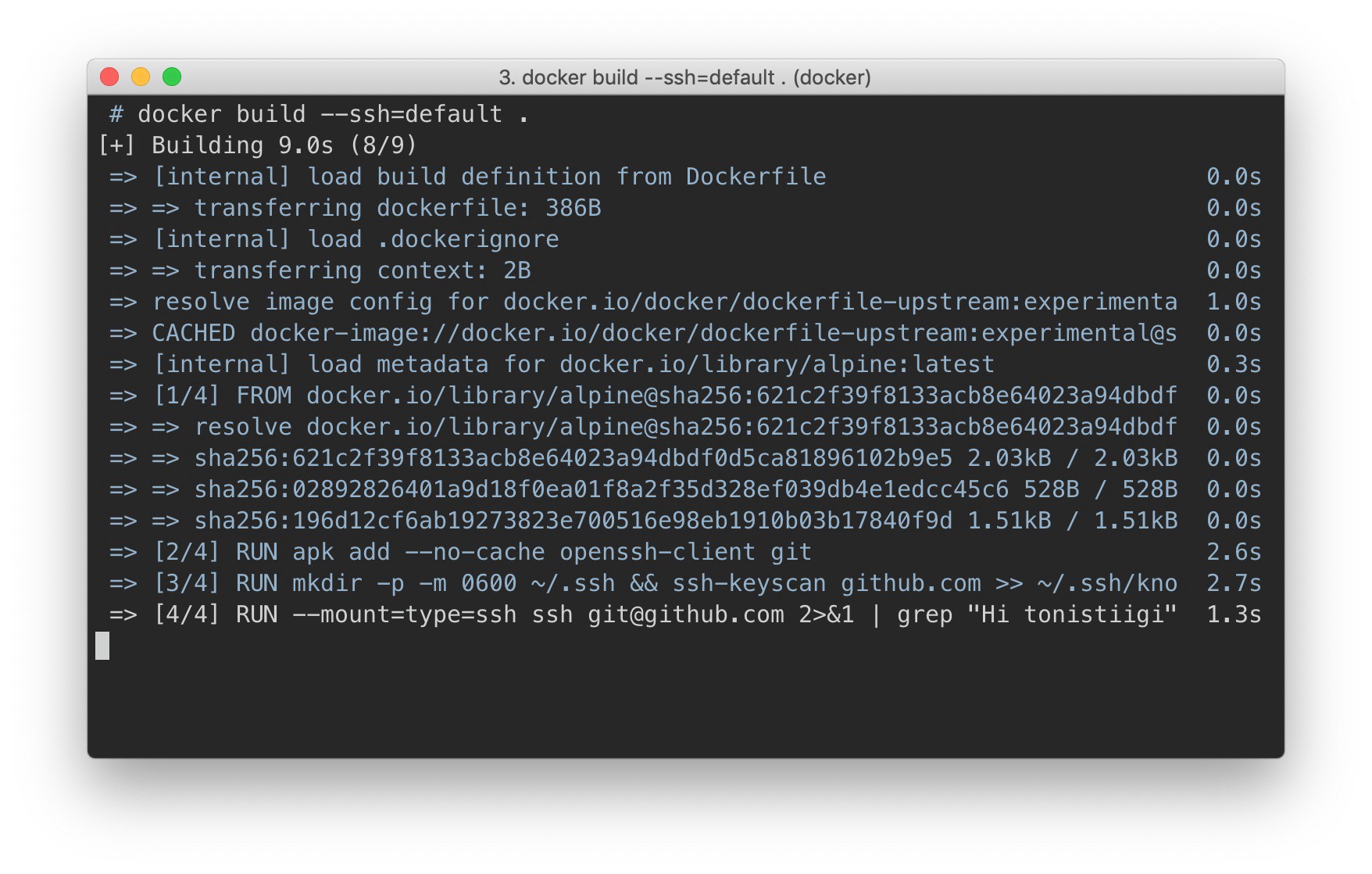
Используя Dockerfile, всегда было сложно получить доступ к частным ресурсам. Хорошего решения просто не было. Использовать переменные среды или просто удалять секретные файлы после использования не годится: они остаются в метаданных образа. Пользователи порой шли на ухищрения: создавали многоступенчатые сборки, однако все равно приходилось соблюдать крайнюю осторожность, чтобы на финальном этапе не было секретных значений, а секретные файлы до отсечения хранились в локальном кэше сборки.
Команда сборки Docker 18.09 включает множество обновлений. Основная особенность — в том, что появился абсолютно новый вариант реализации серверной части, он предлагается в рамках проекта Moby BuildKit. Серверное приложение BuildKit обзавелось новыми функциями, среди которых — поддержка секретов сборки Dockerfile.

В предыдущем посте мы масштабировали набор реплик MongoDB и познакомились со StatefulSet. Сейчас мы займемся оркестрацией кластера высокой доступности Elasticsearch (с другими мастер-нодами, нодами данных и клиентскими нодами) и задействуем ES-HQ и Kibana.
Открыта регистрация на Слёрм-3.
Это трехдневный интенсив по Kubernetes для тех, кто ничего не знает о технологии или начал ее осваивать. Фишка интенсива в практике. Каждый участник сам создаст кластер в облаке Selectel, настроит его и развернет в нем приложение.

Слёрм-3 пройдет в Санкт-Петербурге 1–3 февраля 2019.
Зачем нужен Слёрм, если есть мануалы? Он экономит несколько месяцев, которые иначе вы потратили бы на чтение и самостоятельные эксперименты.
Краткая история вопроса.
Первый Слёрм прошел в августе 2018. Это был эксперимент, который удался, несмотря на кучу ошибок и проблем. Отчет.
GitHub использует MySQL в качестве основного хранилища данных для всего, что не связано с git, поэтому доступность MySQL имеет ключевое значение для нормальной работы GitHub. Сам сайт, интерфейс API на GitHub, система аутентификации и многие другие функции требуют доступа к базам данных. Мы используем несколько кластеров MySQL для обработки различных служб и задач. Они настроены по классической схеме с одним главным узлом, доступным для записи, и его репликами. Реплики (остальные узлы кластера) асинхронно воспроизводят изменения главного узла и обеспечивают доступ для чтения.
Доступность главных узлов критически важна. Без главного узла кластер не поддерживает запись, а это значит, что нельзя сохранить необходимые изменения. Фиксация транзакций, регистрация проблем, создание новых пользователей, репозиториев, обзоров и многое другое будет просто невозможно.
Для поддержки записи необходим соответствующий доступный узел – главный узел в кластере. Впрочем, не менее важна возможность определить или обнаружить такой узел.
В случае отказа текущего главного узла важно обеспечить оперативное появление нового сервера ему на замену, а также иметь возможность быстро оповестить об этом изменении все службы. Общее время простоя складывается из времени, уходящего на обнаружение сбоя, отработку отказа и оповещение о новом главном узле.

Очередная статья в серии «Инструменты мониторинга Logicify» рассказывает о Grafana. Это программное средство мы используем для визуализации и анализа данных как внутренних, так и внешних проектов. Статья может быть полезна техническим директорам, разработчикам, DevOps, системным администраторам, менеджерам проектов, а также всем заинтересованным лицам.


Мы решили перейти на GCP, чтобы повысить производительность приложений — увеличив при этом масштаб, но без существенных затрат. Весь процесс занял более 2 месяцев. Для решения этой задачи мы сформировали специальную группу инженеров.
В этой публикации мы расскажем о выбранном подходе и его реализации, а также о том, как нам удалось достичь главной цели, — осуществить этот процесс максимально гладко и перенести всю инфраструктуру на облачную платформу Google Cloud Platform, не снижая качества обслуживания пользователей.

В последнем посте я рассказывал о Kubernetes, о том, как ThoughtSpot использует его для собственных нужд по поддержке разработки. Сегодня хотелось бы продолжить разговор о короткой, но от того не менее интересной истории отладки, которая произошла совсем недавно. Статья базируется на том, что containerization != virtualization. К тому же наглядно показывается, как контейнеризированные процессы конкурируют за ресурсы даже при оптимальных ограничениях по cgroup и высокой производительности машины.
Helm — это менеджер пакетов для Kubernetes.
На первый взгляд, неплохо. Этот инструмент значительно упрощает процесс релиза, но порой может и хлопот доставить, ничего не попишешь!

В августе Southbridge провели интенсив по Кубернетес Слёрм-1.
В октябре мы его повторили (Слёрм-2) и добавили продвинутый курс (МегаСлёрм).
Удовольствие не из дешевых: Слёрм-2 стоил 35 000 ₽, МегаСлёрм — 75 000 ₽ (онлайн 15 и 35). Я общался с заказчиками, участниками и спикерами, проводил опросы и собирал статистику.
Вот мои наблюдения о том, кто что получил за свои деньги. Многие выводы можно экстраполировать на платные курсы в целом.

Оказалось, понимание «нам подходит Кубернетес» ценнее, чем «мы можем в Кубернетес».
Руководители, отправляя своих инженеров (разработчиков, администраторов) на Слёрм, декларировали: «Пусть пощупает технологию и решит, подходит ли она для наших задач».
Участники Слёрма-1 рассказывали: «После интенсива мы внедрили Кубернетес, теперь я приехал на МегаСлёрм».
3 дня интенсива — в самый раз, чтобы увидеть технологию в полный рост, а не в режиме «Рабинович по мануалам установил». Тут даже вопросов нет, оно того стоит.