Машинное обучение
В третьей части анализа аудиоданных мы разберем относительно простой и более быстрый способ классификации аудиофайлов - алгоритм машинного обучения - SVM (Support Vector Machines) / машины опорных векторов.
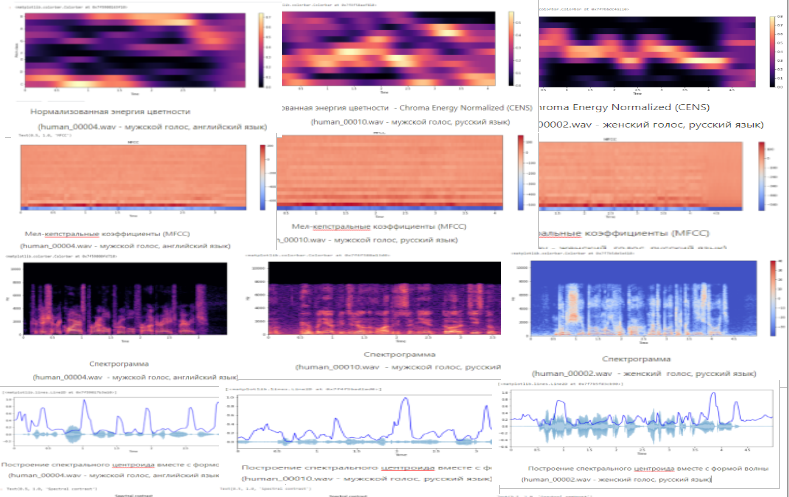
В двух частях анализа аудиоданных мы рассмотрели характеристики, которые есть у каждого аудиосигнала и извлечение значимых характеристик.
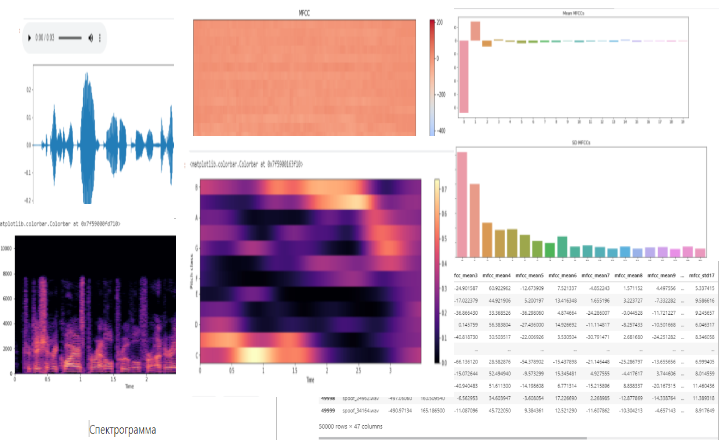
Мы получили набор данных, содержащий значимые характеристики аудиоданных (45 значений) в машиночитаемом виде - Двухмерная таблица - Dataframes, состоящая из 47столбцов и 50000 строк.
Все признаки (характеристики) важны при анализе аудиоданных, так как описывают физические свойства звука: высоту, громкость, тембр и т. д.
При прохождении воздуха через голосовые связки возникают вибрации, которые в виде упругих волн распространяются в среде. Каждый звук представляет собой набор волн. Это основной тон - волны гендерной идентификации ( у каждого говорящего базовая частота основного тона индивидуальна и обусловлена особенностями строения гортани, в среднем для мужского голоса она составляет от 80 до 210 Гц, для женского - от 150 до 320 Гц. ). Это волны - обертоны ( призвуки, которые выше основного тона) и волны форманты (распознавание речи) связанные с уровнем частоты голосового тона, которые образуют тембр звука.